本文内容仅整合 python 操作 redis 的一些函数,包括函数参数,解释以及部分示例,可作为一个python redis 教程使用。
目录
简介
引用菜鸟教程的内容
Redis 简介
Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis与其他key-value存储有什么不同?
Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问
入门
安装redis包
pip install redis
连接redis
按照其他文章的说法redis提供了Redis和StrictRedis
但在现在新版的源码里面定义了StrictRedis = Redis
而且在源码和文档中也没有找到区分开StrictRedis 和 Redis的代码和说明。
所以两者应该已经没有区别了
import redis
host = 'greenkonglong.blog.csdn.net' # redis服务地址
# host='127.0.0.1'
port = 6379 # redis服务默认端口
db = 0
# Redis 推荐用这种方式
cache = redis.Redis(host=host, port=port, db=db, decode_responses=True)
# from_url
'''
redis://[[username]:[password]]@localhost:6379/0
rediss://[[username]:[password]]@localhost:6379/0
unix://[[username]:[password]]@/path/to/socket.sock?db=0
'''
cache_from_url = redis.from_url(f'redis://{host}:{port}/{db}?decode_responses=true')
redis源码Redis类下的__init__初始化方法如下
def __init__(
self,
host="localhost",
port=6379,
db=0, # redis有0-15 共计16个数据库 默认是0 可以根据不同类型数据存放到不同的数据库下
password=None,
socket_timeout=None, # socket响应超时时间
socket_connect_timeout=None, # socket连接超时时间
socket_keepalive=None,
socket_keepalive_options=None,
connection_pool=None, # 连接池
unix_socket_path=None,
encoding="utf-8",
encoding_errors="strict",
charset=None, # 新版源码注释了该项已弃用改用encoding
errors=None, # 新版源码注释了该项已弃用改用encoding_errors
decode_responses=False, # 此项为False时从redis取出的结果默认是字节类型
retry_on_timeout=False, # 超时是否重试
retry_on_error=[],
ssl=False, # ssl证书连接
ssl_keyfile=None,
ssl_certfile=None,
ssl_cert_reqs="required",
ssl_ca_certs=None,
ssl_ca_path=None,
ssl_ca_data=None,
ssl_check_hostname=False,
ssl_password=None,
ssl_validate_ocsp=False,
ssl_validate_ocsp_stapled=False,
ssl_ocsp_context=None,
ssl_ocsp_expected_cert=None,
max_connections=None, # 最大连接数
single_connection_client=False,
health_check_interval=0,
client_name=None,
username=None,
retry=None,
redis_connect_func=None,
):
# 此处省略1万代码...
连接池
pool = redis.ConnectionPool(host=host,port=port,db=0,decode_responses=True)
cache = redis.Redis(connection_pool=pool)
新版源码中初始化默认就定义了连接池,可以不自己定义
if not connection_pool:
# 此处省略1万代码...
connection_pool = ConnectionPool(**kwargs)
self.connection_pool = connection_pool
存储第一个数据
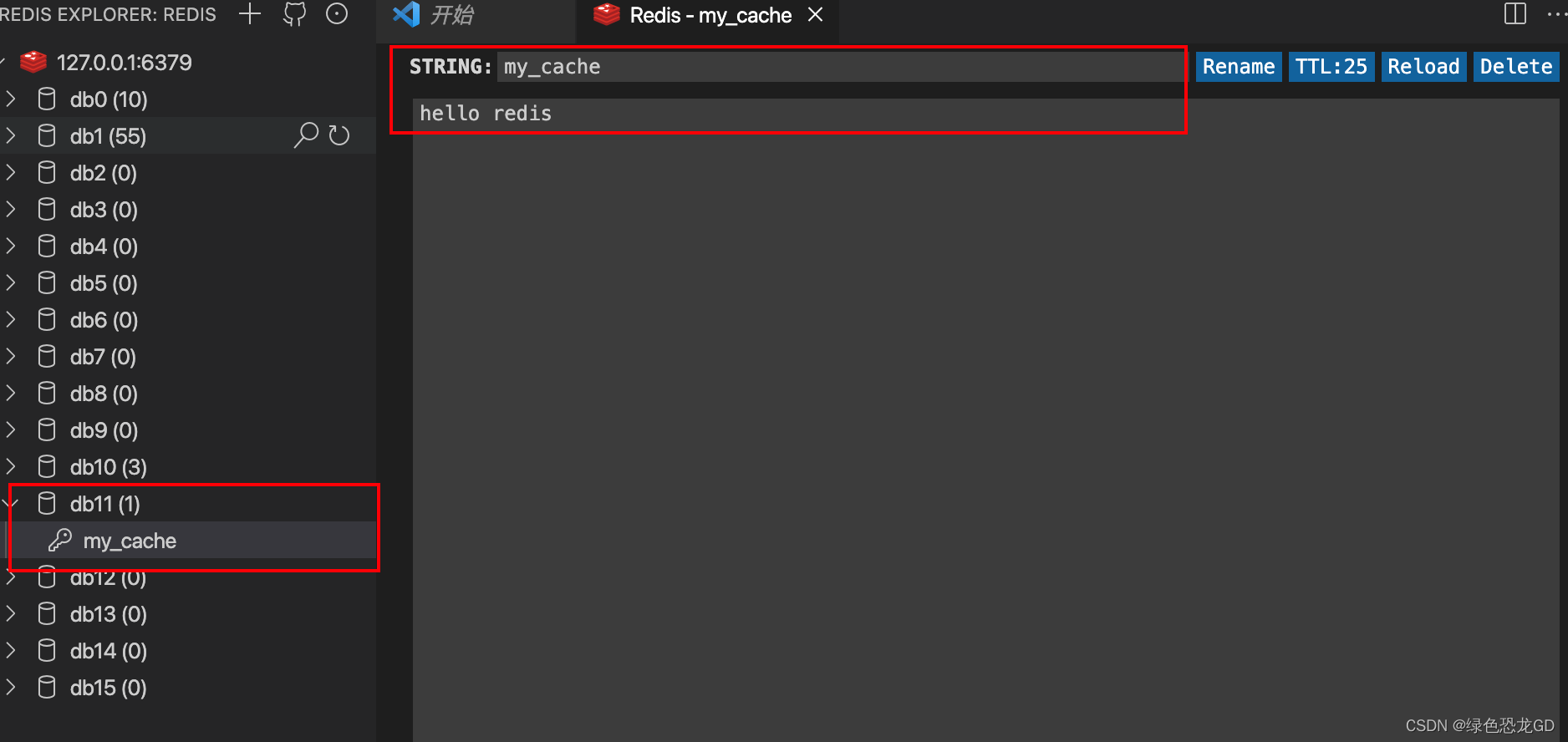
import redis
cache = redis.Redis(host='127.0.0.1', port=6379, db=11)
# key:my_cache value:hello redis 存活时间:30s
cache.set('my_cache', 'hello redis', ex=30)
if cache.exists('my_cache'):
print(cache.get('my_cache'))
else:
print('没有这个键值对')

String操作
set存操作(单个存、批量存)
| 函数 | 参数 | 说明 | 示例 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| set |
|
在Redis中设置值,默认,不存在则创建,存在则修改 | cache.set('my_cache', 'hello redis', ex=30) | ||||||||||
| setnx | name value |
等同于set(name,value,nx=True) | - | ||||||||||
| setex | name value time 过期时间(数字秒 或 timedelta对象) |
等同于set(name,value,ex=expiration_time) | - | ||||||||||
| psetex | name value time_ms 过期时间(数字毫秒 或 timedelta对象) |
等同于set(name,value,px=expiration_time) | - | ||||||||||
| mset | mapping:dict | 1、批量设置值; 2、只能批量设置键值对,不能设置过期时间 |
cache.mset({'k1': 'v1', 'k1': 'v1'}) | ||||||||||
| msetnx | mapping:dict | 1、批量设置值; 2、只能批量设置键值对,不能设置过期时间 3、同setnx,即使只有一个键已经存在,也不会执行任何操作 |
cache.msetnx({'k1': 'v1', 'k1': 'v1'}) |
get取操作(单个取、批量取、获取原来的设置新的)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| get | name:str | 1、根据key值获取value值 2、如果没有设置decode_responses=True 返回的结果则是bytes类型字符串 |
- |
| mget | keys:str *args |
批量获取 | 1、cache.mget(['k3', 'k4']) 2、cache.mget('k3', 'k4') |
| getset | name:str value:str |
设置新值,并获取原来的值 | - |
其他(获取key长度、自增、自减、追加)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| strlen | name:str | 返回name对应值的字节长度(一个汉字3个字节) | - |
| incr(incr = incrby) | name:str amount:int=1 自增数 |
自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 | 1、cache.mget(['k3', 'k4']) 2、cache.mget('k3', 'k4') |
| incrbyfloat | name:str amount:float=1.0 自增数 |
自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 | - |
| decr | name:str amount:int=1 自减数 |
自减数 | - |
| append | key:str value:str |
在redis key对应的值后面追加内容 | - |
Hash(字典)操作
set存操作(单个存、批量存)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| hset | name:str key:str mapping:dict=None |
name对应的hash map中设置一个键值对(不存在,则创建;否则,修改) | 1、cache.hset(name='hash_key', key='k1', value='v1') 下面这种写法相当于是hmset(name,dict) 但是新版中hmset已经弃用建议使用下面这种写法了 2、cache.hset(name='hash_key', mapping={'k2': 'v2', 'k3': 'v3'}) 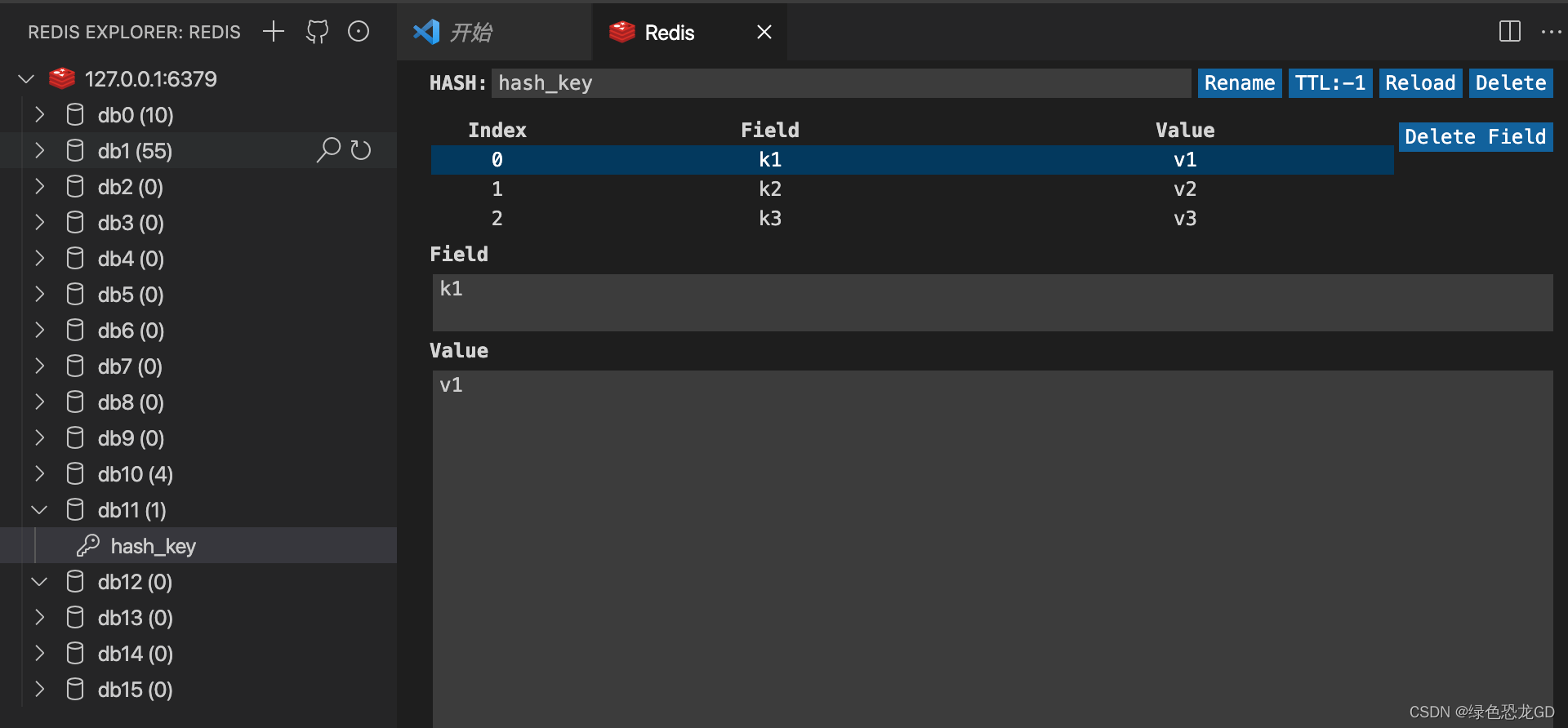 |
| mapping:dict name:str key:str=None value:str=None |
|||
| hsetnx | name: str key: str value: str |
当name对应的hash中不存在当前key时则创建(相当于添加) 缺点:只能单个创建 |
- |
| hmset(已弃用请看hset) | - | DeprecationWarning: Redis.hmset() is deprecated. Use Redis.hset() instead. | - |
get取操作(单个取、批量取、取所有键值对、取所有键、取所有值)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| hget | name:str key:str |
在name对应的hash中根据key获取value | - |
| hmget | name:str keys:list *args |
在name对应的hash中获取多个key的值 | cache.hmget(name='hash_key', keys=['k2', 'k3']) -> ['v2', 'v3'] |
| hgetall | name:str |
获取name对应hash的所有键值 | cache.hgetall(name='hash_key') -> {'k2': 'v2', 'k3': 'v3'} |
| hkeys | name:str | 获取name对应的hash中所有的key的值 | cache.hkeys(name='hash_key') -> ['k2', 'k3'] |
| hvals | name:str | 获取name对应的hash中所有的value的值 | cache.hvals(name='hash_key') -> ['v2', 'v3'] |
其他(获取长度、检查是否存在、删除键、自增)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| hlen | name:str | 获取name对应的hash中键值对的个数 | - |
| hexists | name:str key:str |
检查name对应的hash是否存在当前传入的key | - |
| hdel | name: str *keys: List |
将name对应的hash中指定key的键值对删除 | cache.hdel('hash_key',*('k1','k2')) |
| hincrby | name:str key:str amount:int=1 自增数 |
自增name对应的hash中的指定key的值,不存在则创建key=amount | - |
| hincrbyfloat | name:str key:str amount:float=1 自增数 |
自增name对应的hash中的指定key的值,不存在则创建key=amount | - |
List操作
set存操作(单个存/追加、中间追加)
| 函数 | 参数 | 说明 | 示例 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| lpush/rpush | name: str *values: List |
在name对应的list中添加元素,每个新的元素都添加到列表的最左边(rpush为从右向左) | cache.lpush('hash_key',*['k1','k2','k3']) 保存顺序为k3,k2,k1(rpush->k1,k2,k3) |
||||||||||
| lpushx/rpushx | name: str *values: List |
在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边(rpushx为从右向左) | - | ||||||||||
| linsert |
|
在name对应的列表的某一个值前或后插入一个新值 | cache.linsert(name='hash_key',where='before',refvalue='k3',value='4') 表示在hash_key下'k3'的前面插入一个'k4' |
||||||||||
| lset | name:str value:str index:int |
对name对应的list中的某一个索引位置重新赋值 | - |
get取操作(获取并删除、索引取值、切片取值、获取并添加、获取并删除添加)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| lpop/rpop | name: str | 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素(rpop为从右删除) | - |
| lindex | name: str index:int |
在name对应的列表中根据索引获取列表元素 | - |
| lrange | name: str start:int end:int |
在name对应的列表切片获取数据 | - |
| rpop/lpush | src: str dst:str |
从一个列表获取最右边的元素,同时将其添加至另一个列表的最左边 | - |
| brpop/lpush | src: str dst:str timeout:int=0 当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞 |
从一个列表取出并移除最右边的元素,同时将其添加至另一个列表的最左边 | - |
其他(获取长度、删除)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| llen | name:str | name对应的list元素的个数 | - |
| lrem | name:str value:str num:int 删除几次 |
在name对应的list中删除指定的值 | - |
| ltrim | name:str start:int end:int 索引结束位置(大于列表长度,则代表不移除任何) |
在name对应的列表中移除没有在start-end索引之间的值 | - |
Set集合操作
set存操作(单集合添加)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| sadd | name:str *values |
name对应的集合中添加元素 | cache.sadd('key',*['v1','v2','v3','v3']) 重复的值只会保留一个 |
| 有序集合...待续 | |||
get读操作(获取多集合元素并集/交集、pop类取值)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| sdiff | keys: list *args |
在第一个name对应的集合中且不在其他name对应的集合的元素集合 | cache.sdiff(['set1','set2','set3']) -> set |
| sdiffstore | dest: str keys: list *args |
获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中 | - |
| sinter | keys: list *args |
获取多个name对应集合的交集 | key1 = {a,b,c,d} key2 = {c} key3 = {a,c,e} -> {c} |
| sinterstore | dest:str keys:list *args |
获取多个name对应集合的交集,并将其加入到dest对应的集合汇总 | - |
| smembers | name:str | 获取name对应的集合的所有成员 | - |
| spop | name:str | 从集合的(尾部)获取并移除一个元素 | - |
| srandmember | name:str numbers:int |
从name对应的集合中随机获取 numbers 个元素 | - |
| sunion | keys: list *args |
获取多个name对应集合的并集 | - |
| sunionstore | dest:str keys:list *args |
获取多个name对应集合的并集,并将其加入到dest对应的集合汇总 | - |
| 有序集合...待续 | |||
其他(获取元素个数、删除、批量删除、检查是否在某集合、集合移动到集合)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| scard | name:str | 获取name对应的集合中元素个数 | - |
| ltrim | name:str start:int end:int 索引结束位置(大于列表长度,则代表不移除任何) |
在name对应的列表中移除没有在start-end索引之间的值 | - |
| sismember | name:str value:str |
检查value是否是name对应的集合的成员 | - |
| smove | src:str dst:str value:str |
将某个成员从一个集合中移动到另外一个集合 | - |
| srem | name: str *values |
在name对应的集合中删除某些值 | - |
其他操作(删除、判断存在、模糊匹配、设置过期时间、重命名、数据改库位置、随机取、类型判断)
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
| delete | *names | 删除任意类型符合name的数据 | - |
| exists | name | 检测redis的name是否存在 | - |
| keys | pattern:str='*' | 根据模型获取redis的name 1、* 匹配数据库中所有 key 2、h?llo 匹配 hello , hallo 和 hxllo 等 3、h*llo 匹配 hllo 和 heeeeello 等 4、h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo 5、.... |
- |
| expire | name: str time: int | timedelta nx: bool = False xx: bool = False gt: bool = False lt: bool = False |
为某个redis的某个name设置超时时间 | - |
| rename | src dst |
对redis的name重命名为 | - |
| move | name:str db:int |
将redis的某个值移动到指定的db下 | - |
| randomkey | - | 随机获取一个redis的name | - |
| type | name:str | 获取name对应值的类型 | - |
管道(仅介绍)
日常使用中一般不会使用到管道,并且管道较为复杂,不在此篇内容涉及过多
这里引用pipeline详解到说法:
redis客户端执行一条命令分4个过程:发送命令-〉命令排队-〉命令执行-〉返回结果
这个过程称为Round trip time(简称RTT, 往返时间),mget mset有效节约了RTT,但大部分命令(如hgetall,并没有mhgetall)不支持批量操作,需要消耗N次RTT ,这个时候需要pipeline来解决这个问题
原文:pipeline详解
菜鸟教程:
Redis 管道技术
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
服务端处理命令,并将结果返回给客户端。
Redis 管道技术
Redis 管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。
原文:redis-pipelining
场景案例
会失效的token
需求:
需要从某平台的API接口中请求获取token,然后利用token去请求其他接口;已知每次请求token都会使前一次token失效,为了防止接口请求冲突,现在要将token保存进redis。
1、每次请求下来的token有效期可以从接口返回结果中获得。
2、接口返回结果是json格式
# 字典版本
import requests
from redis import Redis
cache = Redis(host='127.0.0.1', port=6379, db=1, decode_responses=True)
def request_token() -> requests.Session:
"""请求token
:return: requests.Session
"""
pass
def get_token_for_redis() -> dict:
"""从redis获取token
:return: dict
"""
if not cache.exists('api_token1'):
token_response = request_token().json() # 请求token
cache.hset(name='api_token1', mapping=token_response) # 保存dict进redis
expiration_time = token_response.get('expiration_time') # 获取过期时间
cache.expire('api_token1', expiration_time) # 设置api_token1过期时间
else:
token_response = cache.hgetall('api_token1') # 从redis获取token
return token_response
# 字符串版本
import requests
from redis import Redis
cache = Redis(host='127.0.0.1', port=6379, db=1, decode_responses=True)
def request_token() -> requests.Session:
"""请求token
:return: requests.Session
"""
pass
def get_token_for_redis() -> str:
"""从redis获取token
:return: str
"""
if not cache.exists('api_token1'):
token_response = request_token().json() # 请求token
token = token_response.get('token') # 获取token
expiration_time = token_response.get('expiration_time') # 获取过期时间
cache.set(name='api_token1', value=token, ex=expiration_time) # 保存dict进redis
else:
token_response = cache.get('api_token1') # 从redis获取token
return token_response
网站限流
需求:
现在公司网站为了防止别人暴力攻击,需要进行访问频率的限制;限制的逻辑是ip+cookie访问次数>=200次则限制访问,被限制后需要24h*1后接触解除。
from redis import Redis
cache = Redis(host='127.0.0.1', port=6379, db=1, decode_responses=True)
user_ip, user_cookie = ('xxx.xxx.xx.xxx', 'user_id=123456')
def get_user_ip_and_cookie(user_ip, user_cookie) -> str:
"""获取ip+cookie
:return: str
"""
pass
def auto_increment() -> bool:
"""访问自增
:return: bool # True-可以访问 False-被限制
"""
user_key = get_user_ip_and_cookie(user_ip, user_cookie) # 用户标识
if not cache.exists(user_key):
cache.incr(user_key, amount=1) # 自增数/新建自增
return True
else:
count=int(cache.get('user_key'))
if count == 200:
cache.expire(user_key, 1 * 24 * 86400) # 访问次数大于200,24h内限制访问
return False
elif count >= 200:
return False
else:
cache.incr(user_key, amount=1) # 访问次数+1
return True