
✅✅作者主页:🔗孙不坚1208的博客
🔥🔥精选专栏:🔗软件设计师备考笔记(持续更新中)💞💞觉得文章还不错的话欢迎大家点赞👍➕收藏⭐️➕评论💬支持博主🤞
👉👉你的一键三连是我更新的最大动力❤️❤️
计算机组成与体系结构
1、数据的表示
1.1 进制的转换
R进制转10进制使用按权展开法:具体操作方式为∶将R进制数的每一位数值用Rk形式表示,即幂的底数是R,指数为k,k与该位和小数点之间的距离有关。当该位位于小数点左边,k值是该位和小数点之间数码的个数,而当该位位于小数点右边,k值是负值,其绝对值是该位和小数点之间数码的个数加1。

十进制转R进制使用短除法

二进制转八进制与十六进制
①二进制转八进制:每三个二进制位对应一个八进制位,对于二进制数10001110,从低位开始三位三位的看,二进制的110对应八进制的6;二进制的001对应八进制的1;而此时只剩下两位10,那么在最前面补0(补满3位即可),也就是010,对应八进制的2,所以该二进制数10 001 110就对应八进制数216。
②二进制转十六进制:每四个二进制位对应一个十六进制位,对于二进制数10001110,从低位开始四位四位的看,二进制的1110对应十六进制的E(14);二进制的1000对应十六进制的8;如果不满四位,与转八进制一样,在最前面补0(补满4位即可)。在十六进制中,A=10,B=11,C=12,D=13,E=14,F=15。
1.2 原码补码移码IEE754浮点数计算
真值与机器数
真值:符合人类习惯的数字 譬如十进制
机器数:数字实际存到机器里的形式,正负号需要被“数字化”
题目:计算机内的整数常用补码表示,假定在一个程序中定义了变量X,Short X;X的机器数是FFF1H,则变量X真值分别是多少?
X (补码)=1111 1111 1111 0001
X (原码)=1000 0000 0000 1111
X( 真值)=-1111B=-15D
原反补码相互转换



结合C语言中的不同变量+之间的赋值,掌握变量的真值及其机器数值的表示
| 数据类型 | 类型标识符 | 所占用字节数 |
|---|---|---|
| 短整型 | short | 2 |
| 整型 | int | 4 |
| 长整形 | long long | 8 |
| 浮点型(单精度) | float | 4 |
| 浮点型(双精度) | double | 8 |
| 浮点型(高精度) | long double | 12 |
| 字符型 | char | 1 |
| 布尔型 | bool | 1 |
IEEE754标准单精度实型数的真值与机器数的表示,加减运算
浮点数表示

浮点数的标准IEEE754
- 32/64位浮点数(Float/Double)
- 构成:阶码E,尾数M,符号位S
- N = (-1)的S次方× M × 2的E-n次方

浮点数转换实例:
假定在一个程序中定义了变量X,Y,其中X是short型(补码表示),Y是float型(用IEEE754单精度标准表示),X的机器数是FFF1H,Y的机器数是4580 1000H,则变量X、Y的真值分别是多少?



定点数运算与浮点数运算
[A]补 + [B]补= [A+B]补
[A – B]补= [A+(–B )]补= [A]补 + [ – B]补
练习 1:设机器数字长为 8 位(含 1 位符号位),且 A = – 97,B = +41,用补码求 A – B

溢出
溢出的原因:运算结果超出数据表示范围
溢出的判断方法Ⅰ:进位

溢出的判断Ⅱ:变形补码(双符号位)

表示范围:
原码的表示范围
- 原码整数:若机器字长为n+1 ,原码整数的表示范围:-(2的n次方-1)到(2的n次方-1)。
- 真值0有正0与负0
- 原码小数:若机器字长为n+1 ,原码小数的表示范围:-(1-2的-n次方)到(1-2的-n次方-1)。
补码
- 正数:[X]补=[X]原
- 负数:符号除外,各位取反,末位加1
- [X]原=11001001 [X]补=10110111
设机器数字长为 8 位(其中一位为符号位)
- 8位原码整数的表示范围? -127----+127
- 8位补码整数的表示范围? -128----+127
- n位补码整数的表示范围 1000…0-------011…1 —> -2n-1------2n-1-1
- n位无符号整数的表示范围 0-------11111111 —> 0-----2n-1
浮点数的取值范围

运算结果的状态标志
数的加减运算除了有结果外,还要考虑一些状态,比如 If (a > b),两个数的大小比较是如何完成的
例:比较无符号数13 与 5

运算的常见标志位

2、计算机结构
- CPU
- 运算器
- 算术逻辑单元ALU
- 累加寄存器AC
- 数据缓冲寄存器DR
- 状态条件寄存器PSW
- 控制器
- 程序计数器PC
- 指令寄存器IR
- 指令移码器
- 时序部件
- 运算器
- 主存储器
计算机的主机中包含两大部件:CPU和内存(主存储器)。而对于声卡、显卡、鼠标键盘这些都是属于外设。
对于CPU,我们需要了解的就是运算器和控制器,以及这两者中的一些寄存器。
①算术逻辑单元 ALU:它是运算器的重要组成部件,负责处理数据,实现对数据的算术运算和逻辑运算。
②累加寄存器 AC:通常简称累加器,它是一个通用寄存器,功能是当运算器的算术逻辑单元执行算术或逻辑运算时,为ALU提供一个工作区。
③数据缓冲寄存器 DR:作为CPU和内存、外设之间数据传送的中转站,作为CPU和内存、外设之间在操作速度上的缓冲。
④状态条件寄存器 PSW:保存由算术指令和逻辑指令运行或测试的结果建立的各种条件码内容。
⑤程序计数器 PC:用于存放下一条指令的地址。当一条指令被获取后,程序计数器的地址加1,指向下一条指令的地址。
⑥指令寄存器 IR:用于存放当前从主存储器读出的正在执行的一条指令。
⑦地址寄存器 AR:用于保存当前CPU所访问的内存单元的地址。
⑧指令译码器 ID:计算机执行一条指令时,首先分析这条指令的操作码是什么,以决定操作的性质和方法,然后才能控制计算机其他各部件协同完成指令表达的功能,这个分析工作由指令译码器来完成。
3、Flynn分类法
Flynn分类法(计算机体系结构分类)中主要有两个指标:一个是指令流,一个是数据流。指令流为机器执行的指令序列;数据流是由指令调用的数据序列。无论是指令流还是数据流,它们都分为两种类型:单、多。

4、CISC与RISC

5、流水线
5.1 基本概念
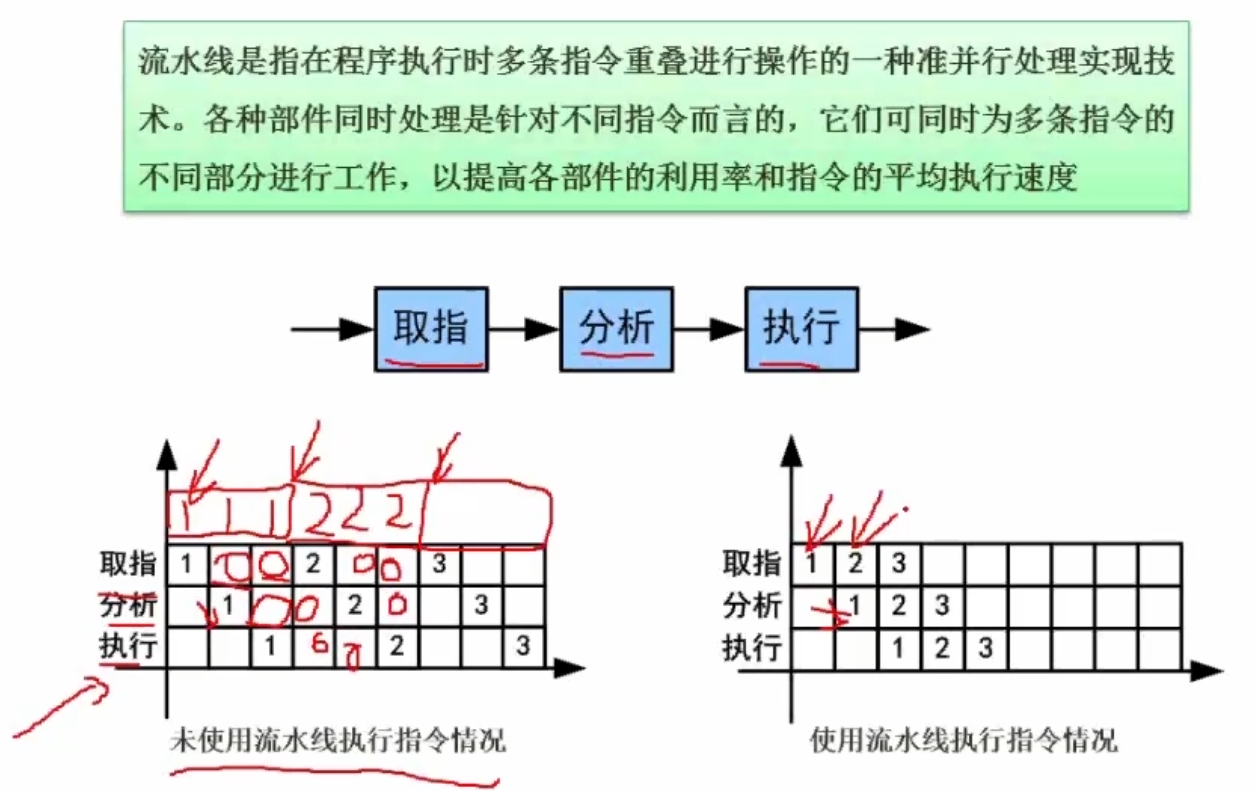
5.2 流水线计算

流水线周期是指在(取指、分析、执行)三个阶段中时间最长的一段,对应上面的例题,最长的一段时间为2ns,所以流水线周期为2ns。
100条指令全部执行完毕需要的时间为:理论公式:(2+2+1)+(100-1)*2=203ns。
100条指令全部执行完毕需要的时间为:实践公式:(3+100-1)*2=204ns。(公式中的k表示指令被分成了几段)
5.3 流水线吞吐率计算

指令条数为100,流水线执行时间为203ns,所以流水线的吞吐率TP=100/203,流水线最大吞吐率是一种理想情况,即TPmax=1/2。(Δt=流水线周期=2ns)。
5.4 流水线加速比

5.5 流水线的效率

6、层次化存储结构

上图中,存储速度最快、效率最高的就是寄存器,它位于CPU中,在CPU中,拥有运算器和控制器,而在运算器和控制器中,就会存在相应的寄存器。而寄存器的容量是极小的,但是速度非常快。
速度排在第二的是Cache高速缓存存储器,之后依次是内存(主存)、外存(辅存)。
对于Cache而言,它内部的所有内容都来自于内存,它所存储的内容是内存中的一小部分,但是运行速度却比内存快的多。
6.1 存储器的分类
按存储器所处的位置分类
- 内存:也称为主存,设在主机内或主板上,用来存放机器当前运行所需要的程序和数据,以便向CPU提供信息。相对于外存,其特点是容量小、速度快。
- 外存:也称为辅存,如磁盘、磁带、光盘和U盘等,用来存放当前不参加运行的大量信息,而在需要时调入内存。
按存储器的构成材料分类
- 磁存储器:用磁介质做成,如磁芯、磁泡、磁膜、磁鼓、磁带及磁盘等。
- 半导体存储器:根据所用元件可分为:双极型和MOS型;根据数据是否需要刷新可分为:静态和动态。
- 光存储器:利用光学方法读/写数据的存储器,如光盘。
按存储器的工作方式分类
- 读/写存储器(RAM):既能读取数据也能存入数据的存储器。
- 只读存储器:工作过程中仅能读取的存储器,根据数据的写入方式又可分为:ROM、PROM、EPROM、EEPROM等。
- 固定只读存储器(ROM):这种存储器是在厂家生产时就写好数据的,其内容只能读出,不能改变。一般用于存放系统程序BIOS和用于微程序控制。
- 可编程的只读存储器(PROM):其中的内容可以由用户一次性写入,写入后不能再修改。
- 可擦除可编程的只读存储器(EPROM):其中的内容既可以读出,也可以由用户写入,写入后还可以修改。
- 电擦除可编程的只读存储器(EEPROM):与EPROM相似,既可以读出,也可以写入,只不过这种存储器采用电擦除的方式进行数据的改写。
- 闪速存储器(FM):简称闪存,其特性介于EPROM和EEPROM之间,类似于EEPROM。
按访问方式分类
- 按地址访问的存储器。
- 按内容访问的存储器。
按寻址方式分类
- 随机存储器(RAM):这种存储器可对任何存储单元存入或读取数据,访问任何一个存储单元所需的时间是相同的。
- 顺序存储器(SAM):访问数据所需要的时间与数据所在的存储位置相关,磁带是典型的顺序存储器。
- 直接存储器(DAM):介于随机存取和顺序存取之间的一种寻址方式。磁盘是一种直接存储器。
6.2 主存
 >>
>>
主存可分为:随机存取存储器(RAM)和只读存储器(ROM)。对于这两种类型,一个明显的区别是:内存是属于RAM的,一旦断电之后,内存中的所有数据都将被清除掉,无法进行保存;而ROM在断电之后,仍然可以存储信息内容。
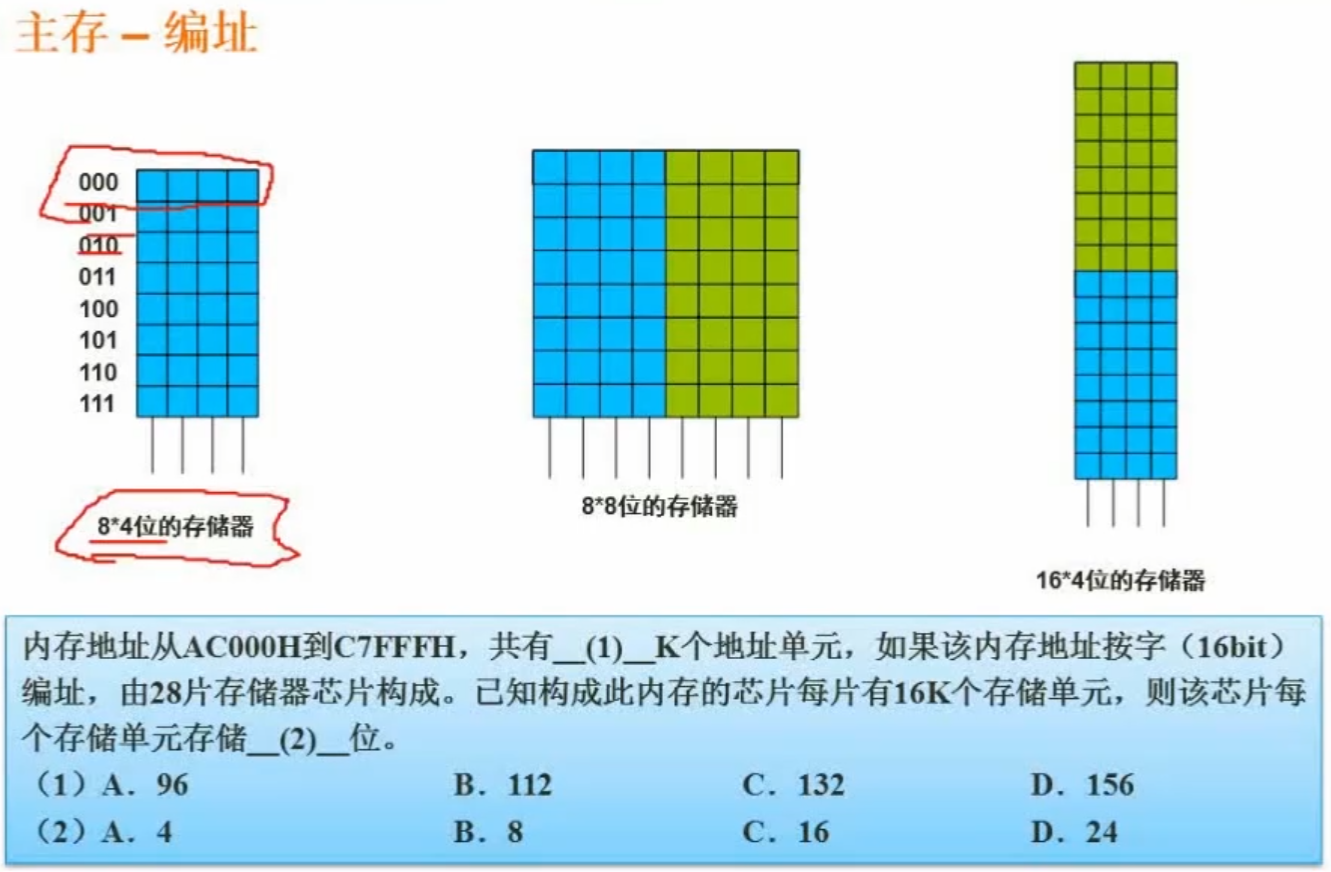
第一空:内存地址从AC000H到C7FFFH,共有多少K个地址单元,那么对这两个十六进制数进行相减、再加1即可,第5位:F-0=F;第四位:F-0=F;第三位:F-0=F;第二位:7-C,因为C=12,不够减,所以向高位借一位,此时第四位应该是:7+16-C=B(11,因为是十六进制,所以每借一位加16);第一位:因为被借走了一位,所以C-1=B,B-A=1;所得结果是:1BFFFH,再加1,即:1C000H(将其转换成K单位,要对结果除以1024)。将其转为十进制:(0×16^0 + 0×16^1 + 0×16^2 + C×16^3 + 1×16^4)/1024=112K。
第二空:总容量为112K×16bit,需要28片存储器芯片,每片芯片有16K个存储单元,问该芯片每个存储单元存储多少位?
答:(112K×16bit)/(28×16K×a)=1,比值为1是因为我们使用这些芯片组成固定的空间,16和16约掉,K和K约掉,所以112/28a=1,即解得a=4。
6.3 Cache

高速缓存中的地址映像方法:直接映像、全相联映像、组相联映像。
**直接映像:**指主存的块与Cache块的对应关系是固定的。优点是地址变换简单,缺点是灵活性差、Cache块冲突率高。
**全相联映像:**允许主存的任一块可以调入Cache存储器的任何一个块的空间中。优点是Cache块冲突率低、灵活性好,缺点是访问速度慢、地址变换较复杂、成本太高。
**组相联映像:**是前两种方式的折衷方案,即组采用直接映像方式、块采用全相联映像方式。
Cache(高速缓存)是什么样的?
- Cache是一种小容量高速缓冲存储器,它由SRAM组成。
- Cache直接制作在CPU芯片内,速度几乎与CPU一样快。
- 程序运行时,CPU使用的一部分数据/指令会预先成批拷贝在Cache中,Cache的内容是主存储器中部分内容的映象。
- 当CPU需要从内存读(写)数据或指令时,先检查Cache,若有,就直接从Cache中读取,而不用访问主存储器。


Cache映射(Cache Mapping)
什么是Cache的映射功能?
- 把访问的局部主存区域取到Cache中时,该放到Cache的何处?
- Cache行比主存块少,多个主存块映射到一个Cache行中
如何进行映射?
- 把主存空间划分成大小相等的主存块(Block)
- Cache中存放一个主存块的对应单位称为槽(Slot)或行(line),有书中也称之为块(Block)
将主存块和Cache行按照以下三种方式进行映射
- 直接(Direct):每个主存块映射到Cache的固定行
- 全相联(Full Associate):每个主存块映射到Cache的任一行
- 组相联(Set Associate):每个主存块映射到Cache固定组中任一行
cache行和主存块之间的映射方式

主存为32字节 地址为5 因为2的5次方为32
块长为4 块内地址为2位 因为 00 01 10 11正好长度是4


直接映射:

容易实现,命中时间短
无需考虑淘汰(替换)问题
需要频繁的将Cache装入
不够灵活,Cache存储空间得不到充分利用,命中率低
全相联映射:Cache的地址映射中,若主存中的任一块均可映射到Cache内的任一块的位置上。

组相联映像


- 结合直接映射和全相连映射的优点。
- 当Cache组数为1时,变为全相联映射。

题目:主存容量为512KB(2的19次方),Cache容量为4KB(2的12次方) ,每个字块为16个字,每个字32位.
有题目得每个字块是16*32bit 2的9次方,所以主存块数是2的10次方 缓存的块数为2的3次方。
在直接映射方式下,主存的第几块映射到Cache的第4块(设起始字块为0)
答:4、2的n次方+4……
画出直接映射下,主存地址字段中各段的位数
 (先求字块内地址,再求缓存块地址,然后用主存容量减去求值)
(先求字块内地址,再求缓存块地址,然后用主存容量减去求值)


7、局部性原理

时间局部性:指如果程序中的某条指令一旦被执行,则不久的将来该指令可能再次被执行。
空间局部性:指一旦程序访问了某个存储单元,则在不久的将来,其附近的存储单元也最有可能被访问。
8、磁盘结构和参数


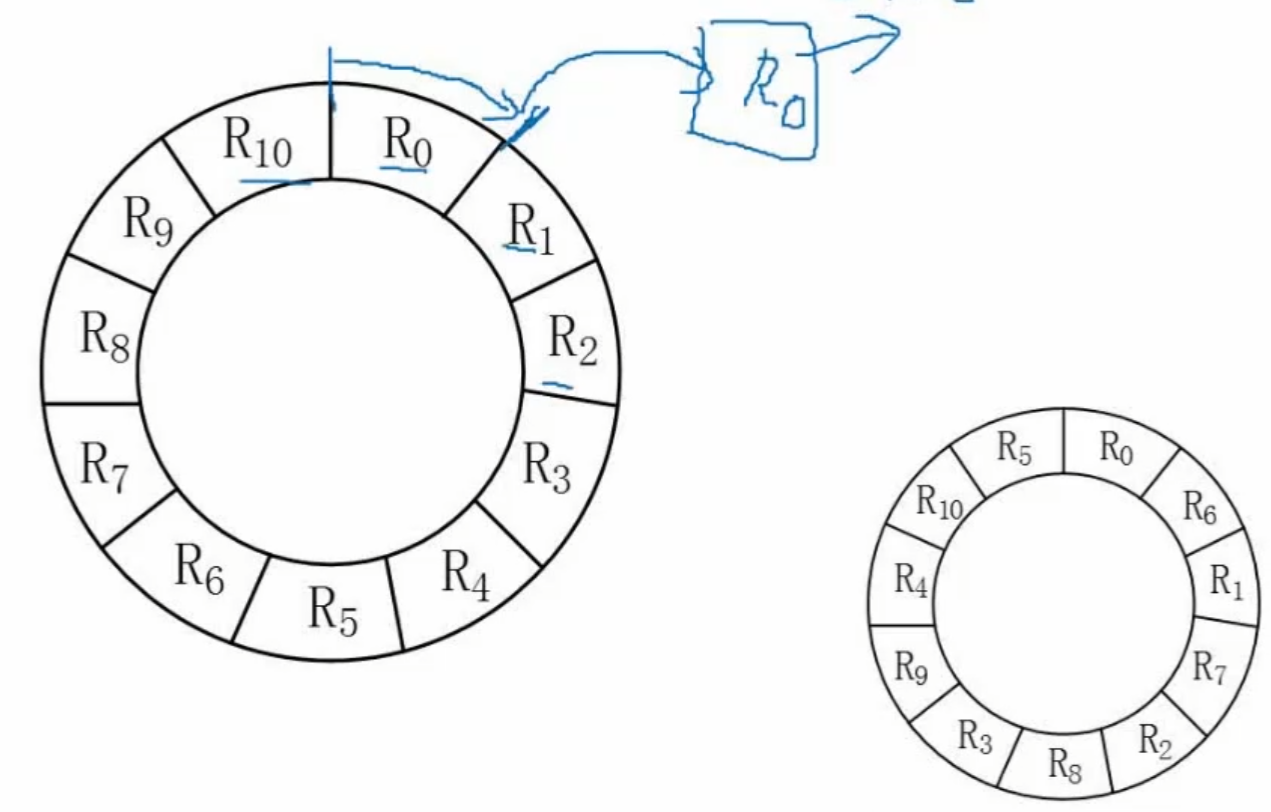
参考答案:磁盘的旋转周期为33ms,表示旋转一圈耗时33ms,一共有11个记录,可以理解为读取1个记录消耗的时间为3ms。
若采用单缓冲区顺序处理(如上图中的大圈),当我们把R0读取单缓冲区时,此时磁头跑到了R1的起始位置,但是此时是不能读取R1的,因为R0占用着缓冲区(还未处理完),所以新的记录是进不来的。当我们处理完缓冲区中的R0之后,花费了3ms,此时磁头已经跑到了R2的起始位置,但是我们接下来想要处理的应该是R1,所以这个时候磁头会一直转动,直到转过一圈,再次跑到R1的起始位置时,才可以处理R1。所以我们处理一个记录R0,一共耗时为:一个记录+一圈,也就是3+33=36ms。从R0到R9都是同样的道理,所以共耗时:36*10=360ms,而对于R10,我们就可以直接读取并处理,耗时为6ms,所以总共耗时为360+6=366ms。
若对信息存储进行优化分布(如上图中的小圈),先看大圈,我们处理R0的时候,磁头跑到了R2,此时我们将R2假设为R1;而处理完R1之后,磁头跑到了R4,此时我们将R4假设为R2,以此类推,就得到了上图中的小圈。这样下来,就没有任何的时间浪费,那么读取和处理分别耗时3ms,也就是处理完一个记录耗时3+3=6ms,一共11个记录,总共耗时6*11=66ms。
9、总线

微机中的总线分为数据总线、地址总线、控制总线。
**数据总线(DB):**用来传送数据信息,是双向的。CPU既可以通过DB从内存或输入设备读入数据,也可以通过DB将内部数据送至内存或输出设备。DB的宽度决定了CPU和计算机其他设备之间每次交换数据的位数。
**地址总线(AB):**用于传送CPU发出的地址信息,是单向的。传送地址总线的目的是指明与CPU交换信息的内存单元或I/O设备,地址总线的宽度决定了CPU的最大寻址能力。
**控制总线(CB):**用来传送控制信号、时序信号和状态信息等,双向线表示。其中有的信号是CPU向内存或外部设备发出的信息,有的信号是内存或外部设备向CPU发出的信息。CB中的每一条线的信息传送方向是单方向且确定的,但CB作为一个整体则是双向的。
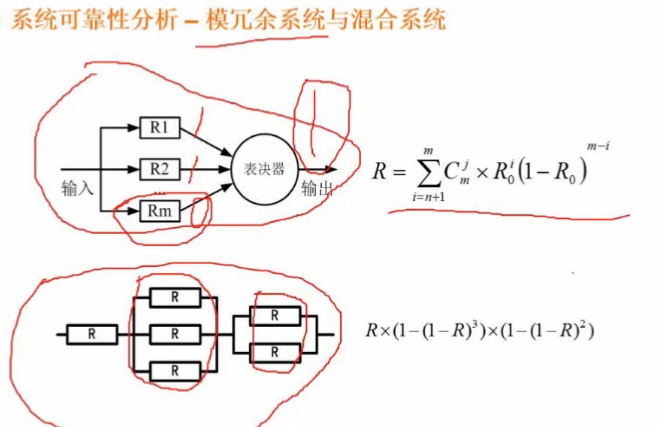
10、系统可靠性分析与设计
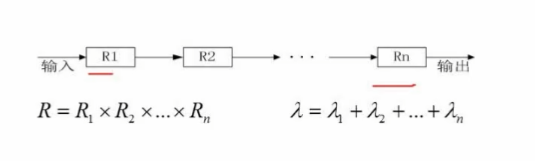
系统中的各个子系统的可靠性均采用R1、R2、…、Rn表示;失效率均采用λ1、λ2、…、λn表示。
串联系统的可靠性(R)与失效率(λ)
并联系统的可靠性(R)与失效率(μ)
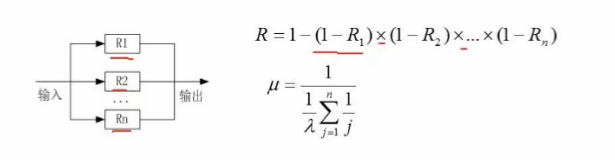
模冗余系统与混合系统
11、差错控制

11.1 循环校验码(CRC)
循环冗余校验码(CRC)广泛应用于数据通信领域和磁介质存储系统中。它利用生成多项式为k个数据位产生r个校验位来进行编码,其编码长度为k+r。
循环冗余校验码是由两部分组成的,左边为信息码(数据),右边为校验码。若信息码占k位,则校验码就占n-k位。其中,n为CRC码的字长,所以又称为(n,k)码。校验码是由信息码产生的,校验码位数越多,该代码的校验能力就越强。在求CRC编码时,采用的是模2运算。


11.2 奇偶校验码(PC)
奇偶校验是一种简单有效的校验方法(可以检错,不能纠错)。这种方法通过在编码中增加一位校验位来使编码中1的个数为奇数(奇校验)或者为偶数(偶校验),从而使码距变为2。
对于奇校验,它可以检测代码中奇数位出错的编码,但不能发现偶数位出错的情况,即当合法编码中的奇数位发生了错误时,编码中的1变成0或0变成1,则该编码中1的个数的奇偶性就发生了变化,从而可以发现错误。
奇校验:被传输的有效数据中“1”的个数是奇数个,校验位填“0”,否则填“1”。
偶校验:被传输的有效数据中“1”的个数是偶数个,校验位填“0”,否则填“1”。
例如:奇校验 1000110(0),采用奇校验,“1”的个数为奇数个,所以校验位填“0”。
偶校验 1000110(1),采用偶检验,“1”的个数为奇数个,所以校验位填“1”。
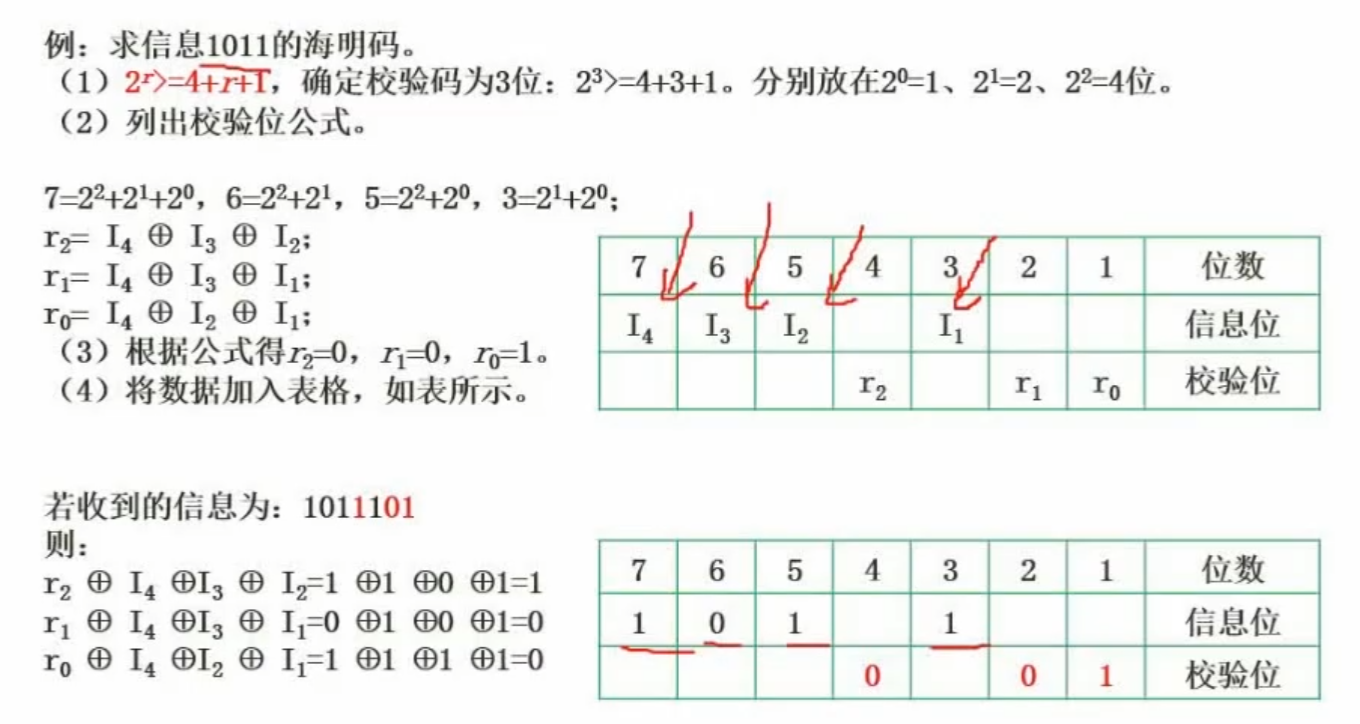
11.3 海明校验码(HC)
海明码的构成方法是在数据位之间的特定位置上插入k个校验位,通过扩大码距来实现检错和纠错(可以检错和纠错)。
设数据位是n位,校验位是k位,则n和k必须满足:2^k - 1 ≥ n + k。
12、输入输出技术
12.1 直接程序控制
直接程序控制是指外设数据的输入/输出过程是在CPU执行程序的控制下完成的。这种方法分为:无条件传送和程序查询方式两种情况。
无条件传送:在此情况下,外设总是准备好的,它可以无条件的随时接收CPU发来的输出数据,也能够无条件的随时向CPU提供需要输入的数据。
程序查询方式:在这种方式下,利用查询方式进行输入/输出,就是通过CPU执行程序来查询外设的状态,判断外设是否准备好接收数据或准备好了向CPU输入的数据。
12.2 中断方式
对于程序控制I/O的方法,其主要的缺点在于CPU必须等待I/O系统完成数据的传输任务,整个系统的性能严重下降。
利用中断方式完成数据的输入/输出过程为:当I/O系统与外设交换数据时,CPU无需等待也不必去查询I/O的状态,而可以抽身出来处理其他任务。当I/O系统准备好了以后,则发出中断请求信号通知CPU,CPU接到中断请求信号后,保存正在执行程序的现场,转入I/O中断服务程序的执行,完成与I/O系统的数据交换,然后再返回被中断的程序继续执行。
与程序控制方式相比,中断方式因为CPU无需等待而提高了效率。
12.3 直接存储器存取方式(DMA)
在计算机与外设交换数据的过程中,无论是程序控制方式,还是中断方式,都需要CPU通过执行程序来实现,这就限制了数据的传送速度。为进一步提高相应的速度,我们引入了DMA。
DMA是指数据在内存与I/O设备间(通俗的说,就是主存与外设)的直接成块传送,即在内存与I/O设备间传送一个数据块的过程,不需要CPU的任何干涉,只需要CPU在过程开始时启动、在过程结束时处理,实际操作全部由DMA硬件自动执行完成,CPU在此传送过程中可以去做别的事情。
12.4 输入/输出处理机(IOP)
DMA方式的出现减轻了CPU对I/O操作的控制,使得CPU的效率显著提高。而通道方式的出现则进一步提高了CPU的效率。通道是一个具有特殊功能的处理器,又称为输入输出处理器(IOP),它分担了CPU的一部分功能,可以实现对外围设备的统一管理,完成外围设备与主存之间的数据传送。
通道方式大大提高了CPU的工作效率,然而这种效率的提高是以增加更多的硬件为代价的。