CVPR2015:Modality-dependent Cross-media Retrieval
将文本信息和图片信息映射到一个公共特征空间
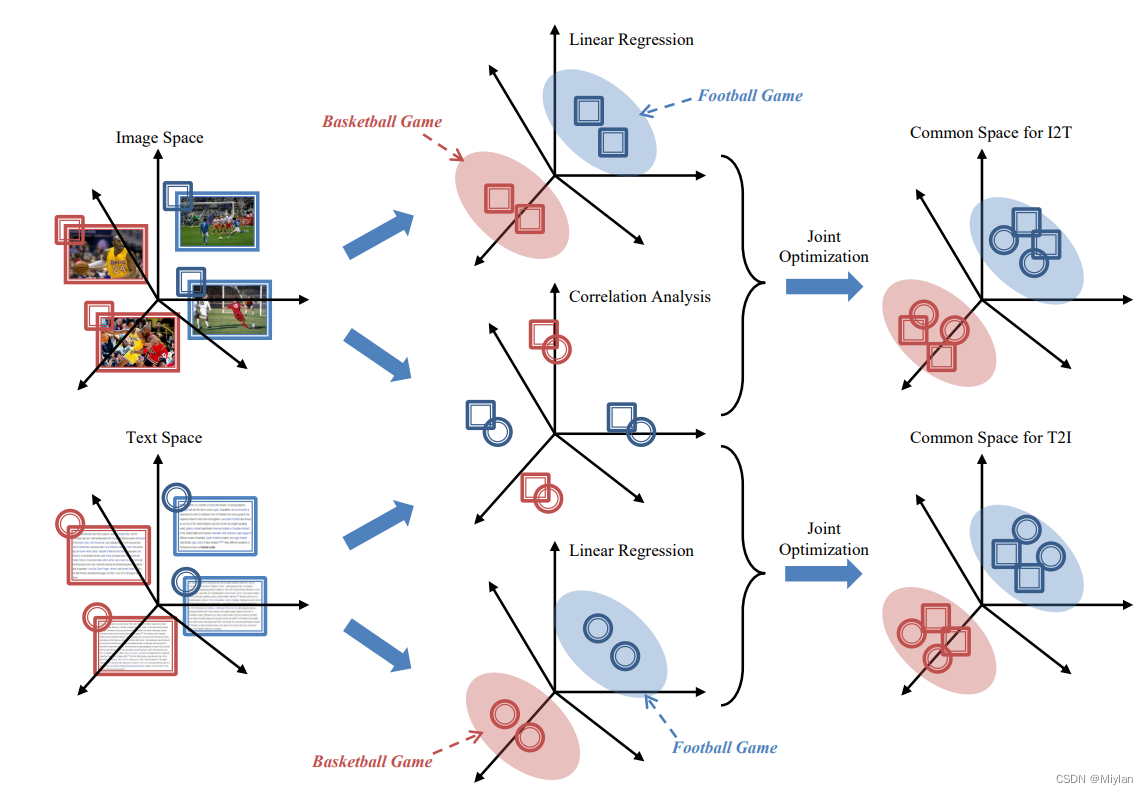
本文提出了基于模态的跨媒体检索(MDCR)模型。图像用方形图标表示,文本用圆形图标表示;不同的颜色表示不同的类别。蓝色和红色的椭圆字段分别表示足球游戏和篮球游戏的语义簇。(a) 从图像特征空间到语义空间的线性回归,为不同类别的图像生成更好的分割。(b) 图像和文本之间的相关性分析,以保持成对的紧密性。(c) 从文本特征空间到语义空间的线性回归,为不同类别的文本生成更好的分隔CVPR2021:Self-Ensemling for 3D Point Cloud Domain Adaption
用于3D点云域自适应任务的端到端自集成网络(SEN)
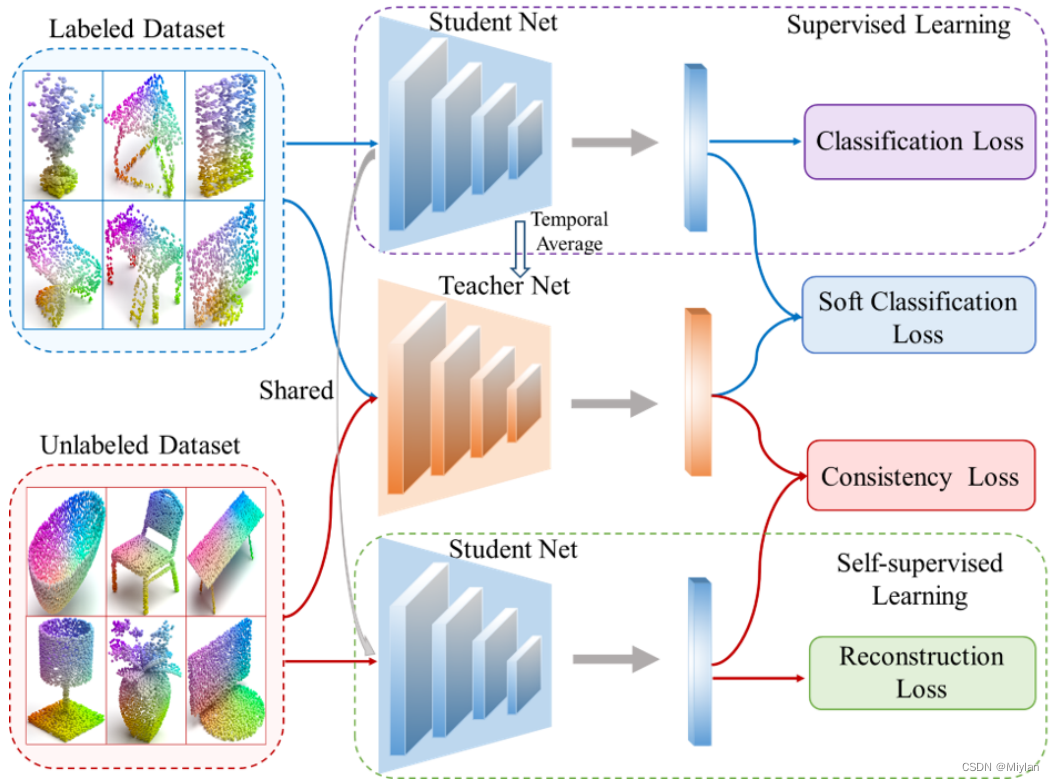
我们用于3D点云域适配的SEN框架的管道。它主要包括两个重要的模型(学生网和教师网)和两个分支的联合学习:1)源域上的监督学习;2) 目标域上的自监督学习。我们的SEN通过引入软分类损失和一致性损失,利用教师和学生网络进行半监督学习,旨在实现一致性泛化和提高精确重建。2021 CROSS-DOMAIN ACTIVITY RECOGNITION VIA SUB-STRUCTURAL OPTIMAL TRANSPORT
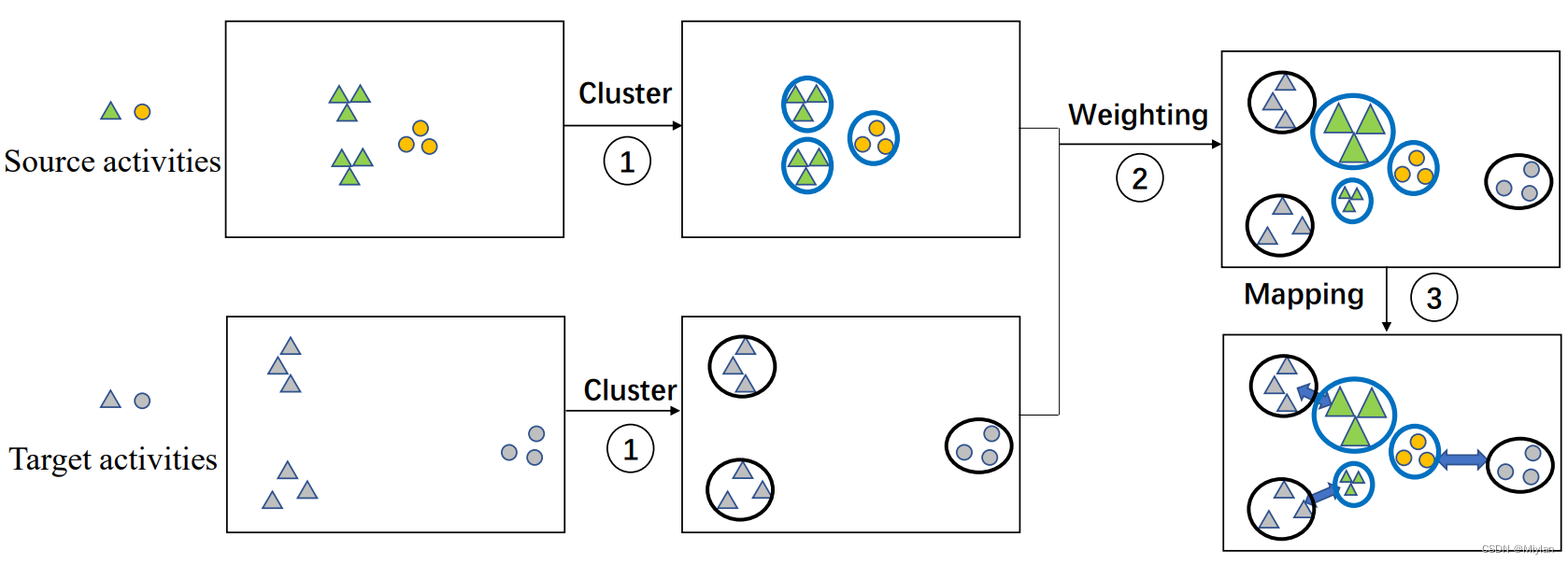
本文提出了一种通用的子结构域自适应(SSDA)方法。SSDA是与子结构一致的通用框架,图3说明了SSDA的主要过程,主要包括三个步骤。首先,SSDA对数据进行聚类,以获得活动的子结构。作为一个通用框架,我们可以选择合适的集群算法进行定制。然后,根据先验或自适应方法对源子结构赋予权重。重量代表子结构的重要性,不同的子结构往往发挥不同的作用。例如,一些远离大多数数据的子结构应该以较小的权重发挥较小的作用。为了简单起见,我们通常在没有先验的情况下对所有结构赋予统一的权重。最后,对不同域的子结构进行映射。
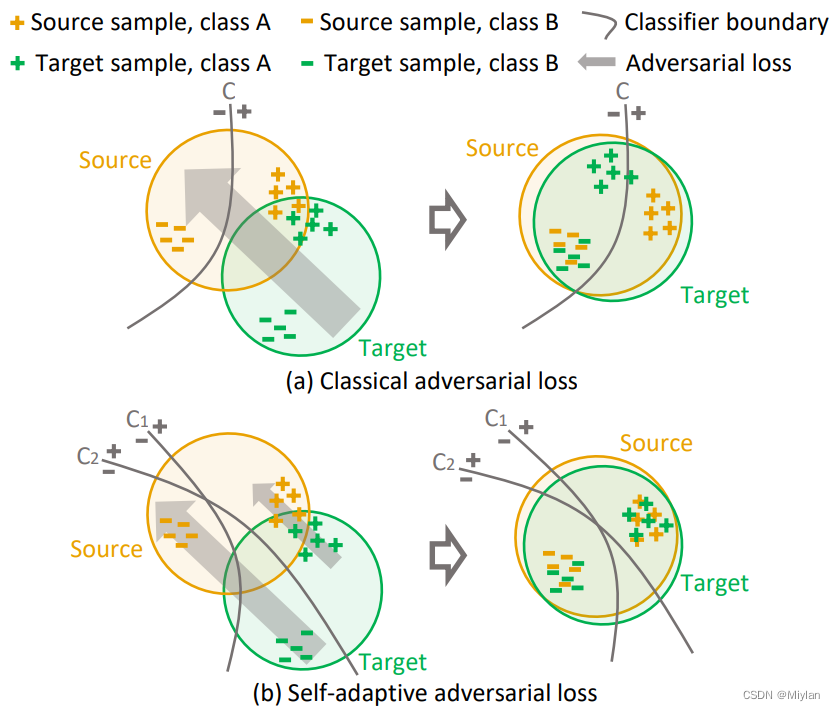
CVPR2019:Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation
代码: https://github.com/RoyalVane/CLAN
为强制两个域的数据分布相似,常见的策略之一是通过对抗性学习调整特征空间中的边缘分布。这种全局移动的一个可能后果是,源和目标之间最初很好对齐的某些类别可能被错误映射,从而导致目标域中的分割结果变差。为了解决这个问题,我们引入了一个类别级别的对抗网络,旨在在全局对齐趋势中加强局部的语义一致性。我们降低了类别级对齐功能的对抗性损失的权重,同时增加了那些不太对齐的功能的对抗力。通过共同训练的方法来决定一个特征在源和目标之间的类别级对齐程度。
详细解析可参看 CVPR 2019 Oral 论文解读 | 无监督域适应语义分割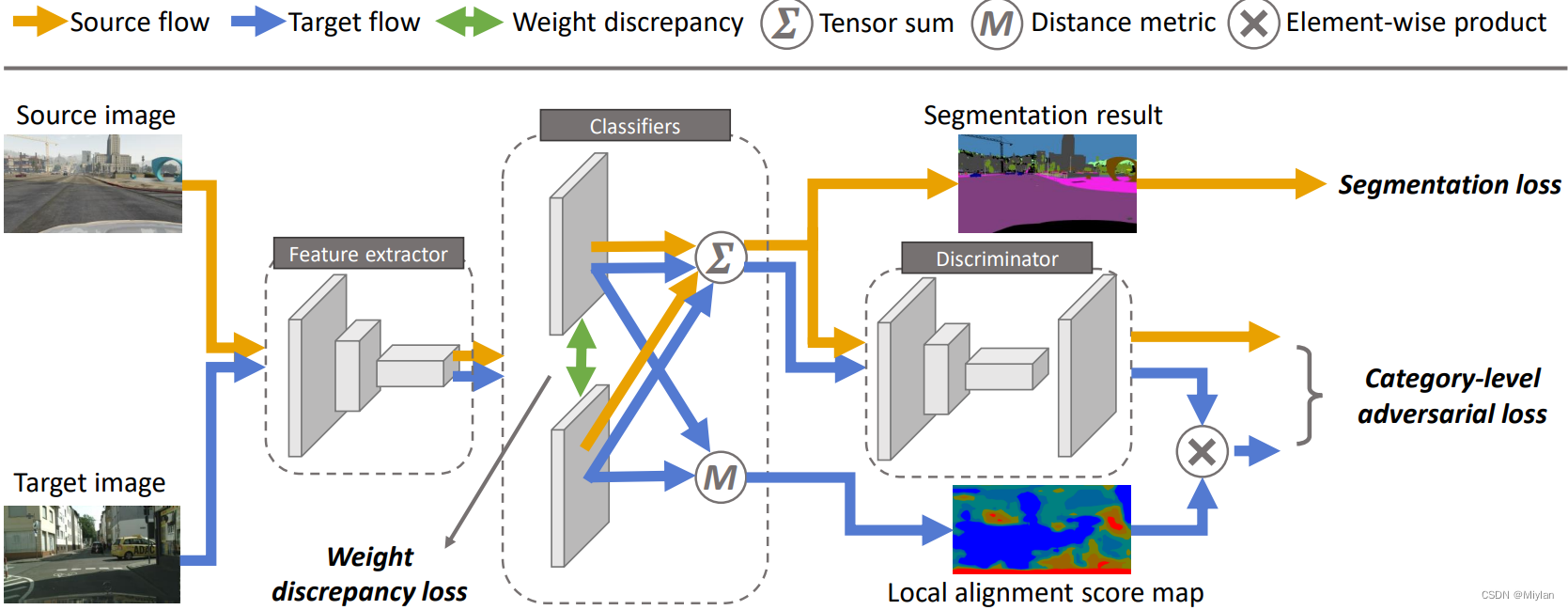
另:迁移学习的代码库