甲骨文 CDC 客户端
支持的管道类型:
|
您可以使用此源来执行数据库复制。您可以将单独的管道与 JDBC 查询使用者或 JDBC 多表使用者源结合使用,以读取现有数据。然后,使用 Oracle CDC 客户端源启动管道以处理后续更改。
Oracle CDC 客户端根据提交编号(按升序)处理数据。
要读取重做日志,Oracle CDC 客户端需要日志矿工字典。源可以在重做日志或联机目录中使用字典。在重做日志中使用字典时,源会捕获并调整到架构更改。使用重做日志字典时,源还可以生成事件。
源可以为数据库中一个或多个表的 INSERT、UPDATE、SELECT_FOR_UPDATE和 DELETE 操作创建记录。您可以选择要使用的操作。源还在记录标头属性中包含 CDC 和 CRUD 信息,因此生成的记录可以很容易地由启用了 CRUD 的目标进行处理。有关数据收集器更改数据处理的概述以及启用了 CRUD 的目标的列表,请参阅处理已更改的数据。
源可以为事件流生成事件。有关数据流触发器和事件框架的详细信息,请参阅数据流触发器概述。
配置 Oracle CDC 客户端时,可以配置更改数据捕获详细信息,例如要从中读取的架构和表、如何读取初始更改、字典源位置以及要包括的操作。您还可以指定要使用的事务窗口和 LogMiner 会话窗口。
您可以将源配置为在本地缓冲记录或使用数据库缓冲区。在使用本地缓冲区之前,请验证所需的资源是否可用,并指定要对未提交的事务执行的操作。
您可以指定当源遇到不受支持的数据类型时的行为,并且可以将源配置为在从补充日志记录数据接收空值时传递 null 值。当源数据库具有高精度时间戳时,可以将源配置为写入字符串值而不是日期时间值以保持精度。
您还可以指定 JDBC 连接信息和用户凭证。如果架构是在可插入数据库中创建的,请声明可插入数据库名称。您可以配置驱动程序所需的自定义属性。
您可以配置高级连接属性。要使用早于 4.0 的 JDBC 版本,请指定驱动程序类名并定义运行状况检查查询。
当担心性能时,例如在处理非常宽的表时,您可以考虑默认源行为的几种替代方法。您可以使用备用 PEG 解析器或使用多个线程进行解析。或者,可以将源配置为不分析 SQL 查询语句,以便将查询传递给要分析的 SQL 分析器处理器。
日志矿工字典源
日志矿工提供字典来帮助处理重做日志。日志矿工可以将字典存储在多个位置。
- 联机目录 - 在预计表结构不会更改时使用联机目录。
- 重做日志 - 当表结构预计会更改时使用重做日志。从重做日志中读取字典时,Oracle CDC 客户端源确定何时发生架构更改,并刷新用于创建记录的架构。源还可以为它在重做日志中读取的每个 DDL 生成事件。
重要:在重做日志中使用字典时,请确保每次更改时间表结构时,都将最新的字典提取到重做日志中。有关详细信息,请参阅 任务 4。提取日志矿工字典(重做日志)。
请注意,在重做日志中使用字典的延迟可能比在联机目录中使用字典的延迟要高得多。但是,使用联机目录不允许进行架构更改。
有关字典选项和配置日志挖掘机的更多信息,请参阅 Oracle 日志挖掘机文档。
Oracle CDC 客户端先决条件
- 启用日志挖掘机。
- 为数据库或表启用补充日志记录。
- 创建具有所需角色和权限的用户帐户。
- 要在重做日志中使用字典,请提取日志矿工字典。
- 安装甲骨文 JDBC 驱动程序。
任务 1.启用日志挖掘机
日志矿工提供重做日志来汇总数据库活动。源使用这些日志来生成记录。
- 以具有 DBA 权限的用户身份登录到数据库。
- 检查数据库日志记录模式:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>select log_mode from v$database;</code></span></span>如果该命令返回存档日志,则可以跳到任务 2。
如果该命令返回无存档日志,请继续执行以下步骤:
- 关闭数据库:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>shutdown immediate;</code></span></span> - 启动并装入数据库:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>startup mount;</code></span></span> - 配置启用存档并打开数据库:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>alter database archivelog; alter database open;</code></span></span>
任务 2.启用补充日志记录
要从重做日志中检索数据,LogMiner 需要对数据库或表进行补充日志记录。
在表级别为要使用的每个表启用至少主键或“标识键”日志记录。使用标识键日志记录,记录仅包括主键和已更改的字段。
由于 Oracle 已知问题,若要为表启用补充日志记录,必须首先为数据库启用最小补充日志记录。
- 若要验证是否为数据库启用了补充日志记录,请运行以下命令:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>SELECT supplemental_log_data_min, supplemental_log_data_pk, supplemental_log_data_all FROM v$database;</code></span></span>如果该命令对所有三列都返回“是”或“隐式”,则使用标识键和完整补充日志记录启用补充日志记录。您可以跳到任务 3。
如果该命令对前两列返回“是”或“隐式”,则使用标识键日志记录启用补充日志记录。如果这是您想要的,则可以跳到任务 3。
- 启用标识密钥或完整补充日志记录。
对于 12c 多租户数据库,最佳做法是为表的容器(而不是整个数据库)启用日志记录。可以先使用以下命令将更改仅应用于容器:您可以启用标识密钥或完整补充日志记录,以从重做日志中检索数据。您不需要同时启用这两项:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>ALTER SESSION SET CONTAINER=<pdb>;</code></span></span>启用标识键日志记录
您可以为数据库中的单个表或所有表启用标识键日志记录:
- 对于单个表
使用以下命令为数据库启用最小补充日志记录,然后为要使用的每个表启用标识键日志记录:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;</code></span></span><span style="color:#333333"><span style="background-color:#eeeeee"><code>ALTER TABLE <schema name>.<table name> ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;</code></span></span> - 对于所有表
使用以下命令为整个数据库启用标识键日志记录:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;</code></span></span>
启用完全补充日志记录
您可以为数据库中的单个表或所有表启用完整的补充日志记录:
对于单个表
使用以下命令为数据库启用最小补充日志记录,然后为要使用的每个表启用完全补充日志记录:<span style="color:#333333"><span style="background-color:#eeeeee"><code>ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;</code></span></span><span style="color:#333333"><span style="background-color:#eeeeee"><code>ALTER TABLE <schema name>.<table name> ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;</code></span></span>对于所有表
使用以下命令为整个数据库启用完全补充日志记录:<span style="color:#333333"><span style="background-color:#eeeeee"><code>ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;</code></span></span>
- 对于单个表
- 要提交更改,请执行以下操作:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>ALTER SYSTEM SWITCH LOGFILE;</code></span></span>
任务 3.创建用户帐户
创建要用于 Oracle CDC 客户端源的用户帐户。您需要该帐户才能通过 JDBC 访问数据库。
甲骨文 12c 多租户数据库
对于多租户 Oracle 12c 数据库,请创建一个通用用户帐户。常见用户帐户是在 cdb$root 中创建的,必须使用约定:。c##<name>
- 以具有 DBA 权限的用户身份登录到数据库。
- 创建公共用户帐户:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>ALTER SESSION SET CONTAINER=cdb$root; CREATE USER <user name> IDENTIFIED BY <password> CONTAINER=all; GRANT create session, alter session, set container, select any dictionary, logmining, execute_catalog_role TO <username> CONTAINER=all; ALTER SESSION SET CONTAINER=<pdb>; GRANT select on <db>.<table> TO <user name>;</code></span></span>对要使用的每个表重复最后一个命令。
配置源时,请将此用户帐户用于 JDBC 凭证。使用整个用户名(包括“c##”)作为 JDBC 用户名。
甲骨文 12c 标准数据库
对于标准 Oracle 12c 数据库,请创建一个具有必要权限的用户帐户:- 以具有 DBA 权限的用户身份登录到数据库。
- 创建用户帐户:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>CREATE USER <user name> IDENTIFIED BY <password>; GRANT create session, alter session, select any dictionary, logmining, execute_catalog_role TO <user name>; GRANT select on <db>.<table> TO <user name>;</code></span></span>对要使用的每个表重复最后一个命令。
配置源时,请将此用户帐户用于 JDBC 凭证。
甲骨文 11g 数据库
对于 Oracle 11g 数据库,请创建一个具有必要权限的用户帐户:- 以具有 DBA 权限的用户身份登录到数据库。
- 创建用户帐户:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>CREATE USER <user name> IDENTIFIED BY <password>; GRANT create session, alter session, execute_catalog_role, select any dictionary, select any transaction, select any table to <user name>; GRANT select on v_$logmnr_parameters to <user name>; GRANT select on v_$logmnr_logs to <user name>; GRANT select on v_$archived_log to <user name>; GRANT select on <db>.<table> TO <user name>;</code></span></span>对要使用的每个表重复最后一个命令。
配置源时,请将此用户帐户用于 JDBC 凭证。
任务 4.提取日志矿工字典(重做日志)
使用重做日志作为字典源时,必须在启动管道之前将 Log Miner 字典解压缩到重做日志中。定期重复此步骤以确保包含字典的重做日志仍然可用。
Oracle 建议您仅在非高峰时段提取字典,因为提取会消耗数据库资源。
<span style="color:#333333"><span style="background-color:#eeeeee"><code>EXECUTE DBMS_LOGMNR_D.BUILD(OPTIONS=> DBMS_LOGMNR_D.STORE_IN_REDO_LOGS);</code></span></span><span style="color:#333333"><span style="background-color:#eeeeee"><code>ALTER SESSION SET CONTAINER=cdb$root;
EXECUTE DBMS_LOGMNR_D.BUILD(OPTIONS=> DBMS_LOGMNR_D.STORE_IN_REDO_LOGS);</code></span></span>任务5.安装驱动程序
甲骨文 CDC 客户端源通过 JDBC 连接到甲骨文。在安装所需的驱动程序之前,您无法访问数据库。
为您使用的 Oracle 数据库版本安装甲骨文 JDBC 驱动程序。有关安装其他驱动程序的信息,请参阅安装外部库。
架构、表名和排除模式
配置 Oracle CDC 客户端源时,可以指定包含要处理的更改捕获数据的表。要指定表,请定义架构、表名模式和可选的排除模式。
定义架构和表名模式时,可以使用正则表达式在架构内或跨多个架构定义一组表。需要时,还可以使用正则表达式作为排除模式,从较大的集合中排除表的子集。
- 架构:销售
- 表名模式: 销售*
- 排除模式:销售。
初始更改
初始更改是 LogMiner 重做日志中要开始处理的点。启动管道时,Oracle CDC 客户端将从指定的初始更改开始处理,并一直持续到您停止管道为止。
请注意,Oracle CDC 客户端进程仅更改捕获数据。如果需要现有数据,则可以在启动 Oracle CDC 客户端管道之前,在单独的管道中使用 JDBC 查询使用者或 JDBC 多表使用者来读取表数据。
从最新更改
源处理启动管道后发生的所有更改。
从指定的日期时间
源处理在指定日期时间及以后发生的所有更改。使用以下格式:日-月-年-HH24:米:秒。
从指定的系统更改编号 (SCN)
源处理在指定的 SCN 及更高版本中发生的所有更改。使用指定的 SCN 时,源开始处理时将使用与 SCN 关联的时间戳进行处理。如果在重做日志中找不到 SCN,则源将继续读取重做日志中可用的下一个更高 SCN。
通常,数据库管理员可以提供要使用的 SCN。
例
您希望处理 Orders 表中的所有现有数据,然后捕获更改的数据,将所有数据写入 Amazon S3。要读取现有数据,请将管道与 JDBC 查询使用者和 Amazon S3 目标结合使用,如下所示: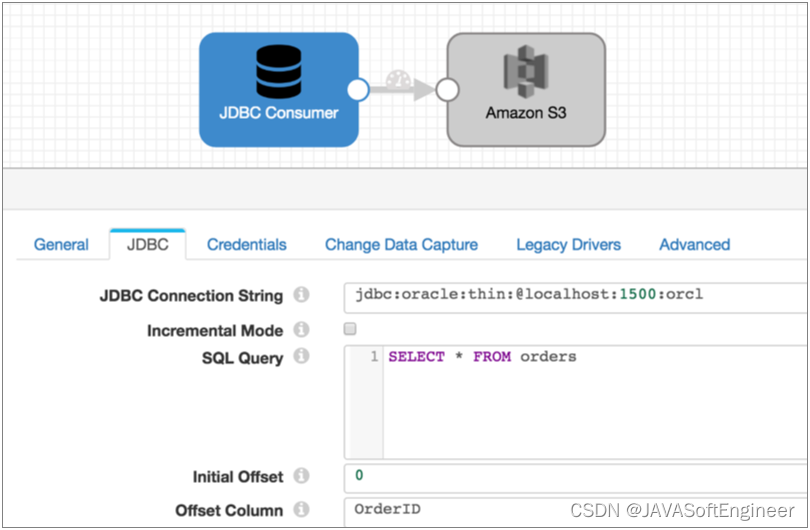
读取所有现有数据后,停止 JDBC 查询使用者管道并启动以下 Oracle CDC 客户端管道。此管道配置为选取在启动管道后发生的更改,但如果要防止数据丢失的任何机会,则可以将初始更改配置为确切的日期时间或更早的 SCN: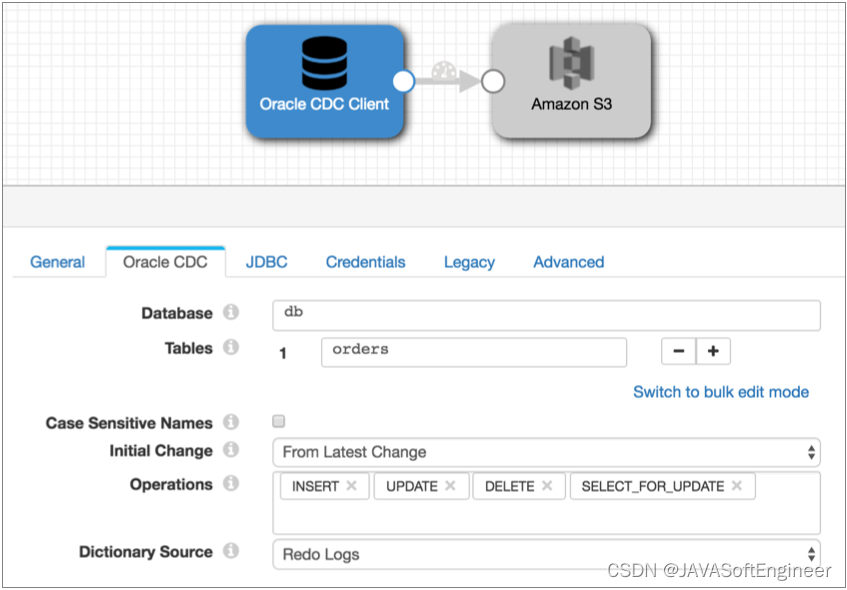
选择缓冲区
处理数据时,Oracle CDC 客户端可以在数据收集器计算机上本地缓冲数据,也可以使用 Oracle 日志挖掘器缓冲区:
本地缓冲区
使用本地缓冲区时,源请求相关表和时间段的事务。源会缓冲生成的 LogMiner 重做 SQL 语句,直到它验证事务的提交。看到提交后,它会解析并处理提交的数据。
源可以完全在内存中缓冲重做 SQL 语句,或者主要将它们写入磁盘,同时使用少量内存进行跟踪。
默认情况下,源使用本地缓冲区。通常,使用本地缓冲区应该比 Oracle 日志挖掘缓冲区提供更好的性能。
使用本地缓冲区处理大型事务或避免独占 Oracle PGA。在数据收集器资源允许时,在内存中缓冲信息以获得更好的性能。将信息缓冲到磁盘以避免独占数据收集器资源。
Oracle 日志挖掘缓冲区
使用甲骨文日志挖掘机缓冲区时,源站会从甲骨文矿机请求特定时间段内的数据。然后,LogMiner 会为数据库中的所有表缓冲该时间段内的所有事务,而不仅仅是源所需的表。
日志挖掘机将事务信息保留在缓冲区中,直到它读取日志中的提交,然后将提交的数据传递到 Oracle CDC 客户端源。
根据事务的大小和数量以及要缓冲的时间段,缓冲事务可以独占 PGA,即 Oracle 服务器进程的专用内存区域。
当您不希望事务量使 Oracle 资源负担过重时,请使用 LogMiner 缓冲区。
本地缓冲区资源要求
在使用本地缓冲区之前,应验证分配的资源是否足以满足管道的需求。
在内存中
在内存中缓冲时,源会缓冲日志矿工重做 Oracle 返回的 SQL 语句。它在收到语句的提交后处理数据。
在内存中缓冲之前,请增加数据收集器 Java 堆大小,以容纳您希望管道接收的信息。
使用以下等式来估计 Java 堆大小要求:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>Required Memory = (L * (30 + S) * T * 1.5) bytes</code></span></span>- L - 日志管理器为每个事务生成的最大语句数。
每个更改的行都会生成一个包含所有字段名称和值的语句。
- S - 由 LogMiner 生成的每个重做 SQL 语句的最大长度(以字符为单位),包括所有字段名称和值。
例如,以下 SQL 语句包含 92 个字符,包括空格和标点符号。
<span style="color:#333333"><span style="background-color:#eeeeee"><code>insert into "SYS"."Y"("ID","D") values ('690054',TO_TIMESTAMP('2017-07-18 02:00:00.389390'))</code></span></span> - T - 在任何给定时间,表的运行中的最大事务数。
30 表示语句 ID 中的字节数,该字节数也存储在其中。
到磁盘
缓冲到磁盘时,源在内存中仅存储每个 SQL 查询的语句 ID。然后,它将查询保存到磁盘。
请注意,当缓冲到磁盘时,数据收集器会在管道启动和停止时清除缓冲的数据。重新启动管线时,数据收集器将使用上次保存的偏移量,除非您重置原点。
在缓冲到磁盘之前,请确保本地磁盘上有足够的可用空间。您还可以增加数据收集器 Java 堆的大小,但其程度低于在内存中完全缓冲时的大小。
使用以下计算来确定管道所需的磁盘空间量:<span style="color:#333333"><span style="background-color:#eeeeee"><code>Required Disk Space = (L * S * T * 1.5) bytes</code></span></span>- L - 日志管理器为每个事务生成的最大语句数。
每个更改的行都会生成一个包含所有字段名称和值的语句。
- S - 由 LogMiner 生成的每个重做 SQL 语句的最大长度(以字符为单位),包括所有字段名称和值。
例如,以下 SQL 语句包含 92 个字符,包括空格和标点符号。
<span style="color:#333333"><span style="background-color:#eeeeee"><code>insert into "SYS"."Y"("ID","D") values ('690054',TO_TIMESTAMP('2017-07-18 02:00:00.389390'))</code></span></span> - T - 在任何给定时间,表的运行中的最大事务数。
使用以下等式来估计管道所需的 Java 堆大小:
<span style="color:#333333"><span style="background-color:#eeeeee"><code>Required Memory = (L * T * 30 * 1.5) bytes</code></span></span>- L - 日志管理器为每个事务生成的最大语句数。
每个更改的行都会生成一个包含所有字段名称和值的语句。
- T:任何给定时间表的运行中的最大事务数。
有关配置数据收集器堆大小的信息,请参阅 Java 堆大小。
未提交的事务处理
使用本地缓冲区时,您可以配置 Oracle CDC 客户端源如何处理旧的未提交事务。旧事务是早于当前事务窗口的事务。
默认情况下,源处理旧的已提交事务。它将每个 LogMiner 重做 SQL 语句转换为一条记录,并将该记录传递到阶段以进行错误处理。
如果不需要错误记录,则可以将源配置为丢弃未提交的事务。这也减少了用于生成错误记录的开销。
包括空值
当 Oracle LogMiner 执行完全补充日志记录时,生成的数据包括表中未发生任何更改的具有空值的所有列。当 Oracle CDC 客户端处理此数据时,默认情况下,它在生成记录时忽略 null 值。
可以将源配置为在记录中包含 null 值。当目标系统具有必填字段时,您可能需要包括 null 值。若要包括空值,请在“Oracle CDC”选项卡上启用“包括空值”属性。
不支持的数据类型
您可以配置源如何处理包含不受支持的数据类型的记录。源可以执行以下操作:
- 将记录传递到管道,而不使用不受支持的数据类型。
- 将记录传递到错误,而不使用不受支持的数据类型。
- 放弃记录。
您可以将源配置为在记录中包含不受支持的数据类型。包括不受支持的类型时,源将包括字段名称,并将数据作为未分析的字符串传递。
- 数组
- 斑点
- 断续器
- 数据链
- 不同
- 间隔
- 爪哇对象
- 恩克洛布
- 其他 __________
- 裁判
- 引用光标
- 断续器
- 结构
- 时间与时区
条件数据类型支持
- Oracle 原始数据类型被视为数据收集器字节数组。
- “具有时区的 Oracle 时间戳”数据类型将转换为“数据收集器已分区日期时间”数据类型。为了在提供更高精度的同时最大限度地提高效率,原点仅包括与数据的 UTC 偏移量。它省略时区 ID。
生成的记录
当源配置为解析 SQL 查询时,它会根据 Oplog 操作类型以及为数据库和表启用的日志记录以不同的方式生成记录。它还在记录标头属性中包括 CDC 和 CRUD 信息。
| 操作日志 | 仅标识/主键日志记录 | 完整补充日志记录 |
|---|---|---|
| 插入 | 包含数据的所有字段,忽略具有空值的字段。 | 所有字段。 |
| 更新 | 主键字段和具有更新值的字段。 | 所有字段。 |
| SELECT_FOR_更新 | 主键字段和具有更新值的字段。 | 所有字段。 |
| 删除 | 主键字段。 | 所有字段。 |
当源配置为不解析 SQL 查询时,它只是将每个日志矿工 SQL 语句写入 SQL 字段。
CRUD 操作标头属性
操作类型
Oracle CDC 客户端评估与其处理的每个条目关联的 Oplog 操作类型,并在适当时将操作类型写入 sdc.operation.type 记录标头属性。
源使用 sdc.operation.type 记录标头属性中的以下值来表示操作类型:- 1 用于插入
- 2 表示删除
- 3 用于更新和SELECT_FOR_UPDATE
如果在管道中使用启用了 CRUD 的目标(如 JDBC 创建器或弹性搜索),则在写入目标系统时,目标可以使用该操作类型。必要时,可以使用表达式计算器或脚本处理器来操作标头属性中的值。有关数据收集器更改数据处理的概述以及启用了 CRUD 的目标的列表,请参阅处理已更改的数据。sdc.operation.type
使用启用了 CRUD 的目标时,目标会在 sdc.operation.type 属性中查找操作类型,然后再检查 oracle.cdc.operation 属性。
甲骨文.cdc.operation
Oracle CDC 客户端还会将 Oplog CRUD 操作类型写入“操作”记录标头属性。此属性是在早期版本中实现的,并且支持向后兼容。
源将 Oplog 操作类型写入 oracle.cdc.操作属性,如下所示的字符串:- 插入
- 更新
- SELECT_FOR_更新
- 删除
CDC 标头属性
- 甲骨文.cdc.operation
- oracle.cdc.query
- oracle.cdc.rowId
- oracle.cdc.scn
- 预言机.cdc.timestamp
- 甲骨文.cdc.table
- oracle.cdc.user
- jdbc.<文件名>.precision
- jdbc.<字段名>.scale
您可以使用记录:属性或记录:属性或默认值函数来访问属性中的信息。有关使用记录标头属性的详细信息,请参阅使用标头属性。
事件生成
Oracle CDC 客户端源可以生成事件,当源使用重做日志作为字典源时,您可以在事件流中使用这些事件。使用联机目录作为字典源时,源不会生成事件。
当您使用重做日志作为字典源并启用事件生成时,Oracle CDC 客户端会在读取 DDL 语句时生成事件。它为 ALTER、创建、删除和截断语句生成事件。
启动管道时,源将查询数据库并缓存源中列出的所有表的架构,然后为每个表生成初始事件记录。每个事件记录描述每个表的当前架构。源使用缓存的架构在处理与数据相关的重做日志条目时生成记录。
然后,源为它在重做日志中遇到的每个 DDL 语句生成一个事件记录。每个事件记录都包含 DDL 语句和记录标头属性中的相关表。
源在新的和已更新的表的事件记录中包含表架构信息。当源遇到 ALTER 或 CREATE 语句时,它会在数据库中查询表的最新架构。
如果 ALTER 语句是对缓存架构的更新,则源将更新缓存,并在事件记录中包含更新的表架构。如果 ALTER 语句早于缓存的架构,则源在事件记录中不包括表架构。同样,如果 CREATE 语句用于“新”表,则源将缓存新表,并在事件记录中包含表架构。由于源验证管道启动时所有指定的表是否存在,因此只有在管道启动后删除并创建表时,才会发生这种情况。如果 CREATE 语句用于已缓存的表,则源在事件记录中不包括表架构。
- 使用电子邮件执行程序在收到事件后发送自定义电子邮件。
有关示例,请参阅案例研究:发送电子邮件。
- 具有用于存储事件信息的目标。
有关示例,请参阅案例研究:事件存储。
有关数据流触发器和事件框架的详细信息,请参阅数据流触发器概述。
活动记录
| 记录标头属性 | 描述: __________ |
|---|---|
| 事件类型 | 事件类型。使用以下类型之一:
|
| sdc.event.version | 指示事件记录类型的版本的整数。 |
| sdc.event.creation_timestamp | 阶段创建事件时的纪元时间戳。 |
| 甲骨文.cdc.table | 已更改的 Oracle 数据库表的名称。 |
| oracle.cdc.ddl | 触发事件的 DDL 语句。 |
删除和截断事件记录仅包括上面列出的记录标头属性。
CREATE 事件记录包括删除并重新创建新表时该表的架构。ALTER 事件记录包括语句更新高速缓存模式时的表模式。有关 CREATE 和 ALTER 语句的行为的详细信息,请参阅事件生成。
例如,以下 ALTER 事件记录显示更新的架构中的三个字段 - 昵称、ID 和名称: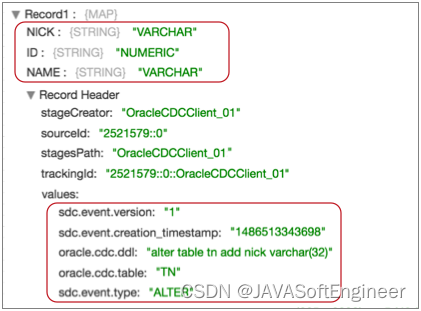
在记录标头属性列表中,请注意添加 NICK 字段的 DDL 语句、更新的表的名称和 ALTER 事件类型。
PEG 解析器(测试版)
Oracle CDC 客户端源提供了一个备用 PEG 解析器,您可以在关注管道性能时尝试该解析器。
Oracle CDC 客户端源提供 PEG 解析器作为默认解析器的替代方法。当您认为默认解析器的性能不足时,您可以尝试使用 PEG 解析器,例如在处理非常宽的表时。请注意,PEG 解析器目前处于 beta 阶段,在生产中使用之前应仔细测试。
有关 PEG 处理的详细信息,请参阅 https://en.wikipedia.org/wiki/Parsing_expression_grammar。
若要使用 PEG 分析器,请在 Oracle CDC 选项卡上启用“分析 SQL 查询”属性,然后在“高级”选项卡上启用“使用 PEG 分析器”属性。
多线程解析
将源配置为使用本地缓冲并分析 SQL 查询时,可以将 Oracle CDC 客户端源配置为使用多个线程来分析事务。您可以将多线程分析与默认的 Oracle CDC 客户端解析器和备用 PEG 解析器结合使用。
执行多线程解析时,源使用多个线程从事务中提交的 SQL 语句生成记录。它不对生成的记录执行多线程处理。
Oracle CDC 客户端源根据“分析线程池大小”属性使用多个线程进行解析。启动管道时,原点将创建属性中指定的线程数。源连接到 Oracle,创建一个日志矿工会话,并一次处理一个事务。
当源处理事务时,它会读取事务中的所有 SQL 语句并将其缓冲到内存中队列中,并等待语句提交后再处理它们。提交后,将使用所有可用线程解析 SQL 语句,并保留 SQL 语句的原始顺序。
生成的记录将传递到管道的其余部分。请注意,启用多线程分析不会启用多线程处理 - 管道使用单个线程读取数据。
使用 SQL 分析器处理器
对于非常宽的表,具有数百列的表,使用 Oracle CDC 客户端源读取重做日志并分析 SQL 查询的表可能需要比预期更长的时间,并且可能导致 Oracle 重做日志在读取之前轮换出来。发生这种情况时,数据将丢失。
若要避免这种情况,可以使用多个管道和 SQL 分析器处理器。第一个管道包含 Oracle CDC 客户端和一个中间终结点。将源配置为不解析 SQL 查询。第二个管道将记录从中间终结点传递到 SQL 分析器处理器,以分析 SQL 查询并更新字段。使用此方法,源可以读取重做日志,而无需等待 SQL 解析器完成,因此不会丢失任何数据。
- 读取更改数据日志。
- 生成仅包含 SQL 查询的记录。
- 生成事件。
- 分析 SQL 查询。
- 生成 CDC 和 CRUD 记录标头属性。
有关 SQL 分析器处理器的详细信息,请参阅 SQL 分析器。
使用漂移同步解决方案
如果使用 Oracle CDC 客户端源作为 Hive 管道的漂移同步解决方案的一部分,请确保仅将标记为插入的记录传递到 Hive 元数据处理器。
- 将 Oracle CDC 客户端配置为仅处理插入记录。
- 如果要处理管道中的其他记录类型,请使用流选择器仅将插入记录路由到 Hive 元数据处理器。
使用 Oracle CDC 客户端进行数据预览
将数据预览与 Oracle CDC 客户端源结合使用时,可能需要增加“预览超时数据预览”属性。
默认情况下,数据预览会等待 10,000 毫秒(10 秒)以建立与源系统的连接,然后才会超时。由于此源的复杂性,初始启动所需的时间可能比默认启动时间长。
如果数据预览超时,请尝试将 timeout 属性增加到 120,000 毫秒。如果预览继续超时,请以增量方式增加超时。
配置甲骨文 CDC 客户端
配置 Oracle CDC 客户端源,以处理来自 Oracle 数据库的日志矿工更改数据捕获信息。
在使用源之前,请完成先决条件任务。有关详细信息,请参阅 Oracle CDC 客户端先决条件。
- 在“属性”面板的“常规”选项卡上,配置以下属性:
- 在 Oracle CDC 选项卡上,配置以下更改数据捕获属性:
甲骨文 CDC 属性 描述: __________ 表 要跟踪的表。根据需要指定相关属性。 使用简单或批量编辑模式,单击添加图标以定义其他表配置。
架构名称 要使用的架构。可以输入架构名称或使用 SQL LIKE 语法指定一组架构。 默认情况下,源以全部大写形式提交架构名称。若要使用小写或大小写混合的名称,请启用“区分大小写的名称”属性。
表名模式 指定要跟踪的表的表名称模式。可以输入表名或使用 SQL LIKE 语法指定一组表。
默认情况下,源提交所有大写的表名称。若要使用小写或大小写混合的名称,请启用“区分大小写的名称”属性。排除模式 一种可选的表排除模式,用于定义要排除的表的子集。您可以输入表名或使用正则表达式指定要排除的表的子集。 区分大小写的名称 允许使用区分大小写的架构、表和列名称。如果未启用,则源将提交全部大写的名称。 默认情况下,Oracle 对架构、表和列名称使用所有大写字母。仅当创建架构、表或列时,名称才能为小写或混合大小写,并在名称两边加上引号。
初始更改 读取的起点。使用以下选项之一: - 从最新更改 - 处理启动管道后到达的更改。
- 从日期开始 - 处理从指定日期开始的更改。
- 从 SCN - 处理从指定的系统更改编号 (SCN) 开始的更改。
开始日期 启动管道时要读取的日期时间。对于基于日期的初始更改。 使用以下格式:
日-月-年-HH24:米:秒。启动断续器 系统会更改数字以从您启动管道时开始读取。如果在重做日志中找不到 SCN,则源将继续读取重做日志中可用的下一个更高 SCN。 对于基于 SCN 的初始更改。
操作 创建记录时要包括的操作。所有未列出的操作都将被忽略。 字典源 日志矿工字典的位置: - 重做日志 - 在架构可以更改时使用。允许源适应架构更改并为 DDL 语句生成事件。
- 联机目录 - 用于在架构预计不会更改时获得更好的性能。
本地缓冲区更改 确定原点使用的缓冲区。选择以使用本地数据收集器缓冲区。清除以使用 Oracle 日志挖掘缓冲区。通常,使用本地缓冲区将增强管道性能。 默认情况下,源使用本地缓冲区。
缓冲区位置 确定使用哪些本地缓冲区: - 在内存中
- 到磁盘
在运行管道之前,请注意本地缓冲区资源要求。有关详细信息,请参阅本地缓冲区资源要求。
丢弃旧的未提交事务 丢弃较旧的未提交事务,而不是将它们处理为错误记录。 不支持的字段类型 确定当源在记录中遇到不受支持的数据类型时的行为: - 忽略并将记录发送到管道 - 源忽略不受支持的数据类型,并将仅包含受支持数据类型的记录传递到管道。
- 将记录发送到错误 - 源根据为阶段配置的错误记录处理来处理记录。错误记录仅包含支持的数据类型。
- 丢弃记录 - 原点丢弃记录。
有关不受支持的数据类型的列表,请参阅不支持的数据类型。
将不受支持的字段添加到记录 包括记录中数据类型不受支持的字段。包括字段名称和不受支持的字段的未分析字符串值。 包括空值 在从包含空值的完整补充日志记录生成的记录中包含 null 值。默认情况下,源生成不带 null 值的记录。 将时间戳转换为字符串 使源能够将时间戳写入字符串值,而不是日期时间值。字符串保持存储在源数据库中的精度。例如,字符串可以保持高精度时间戳(6) 字段的精度。 将时间戳写入不存储纳秒的数据收集器日期或时间数据类型时,源将时间戳的任何纳秒存储在字段属性中。
最大交易长度 等待事务更改的时间(以秒为单位)。输入您希望事务所需的最长时间段。 默认值为 ${ 1 * 小时 },即 3600 秒。
日志矿工会话窗口 保持日志矿工会话打开的时间(以秒为单位)。设置为大于最大事务长度。不使用本地缓冲时减少,以减少 LogMiner 资源使用量。 默认值为 ${ 2 * 小时 },即 7200 秒。
解析 SQL 查询 确定是否分析 SQL 查询。 如果设置为 false,则源将 SQL 查询写入“sql”字段,该字段以后可由 SQL 分析器处理器进行分析。
默认值为 true,表示源解析 SQL 查询。
在标头中发送重做查询 在 oracle.cdc.query 记录标头属性中包括“日志矿工重做”查询。 数据库时区 数据库的时区。指定数据库在与数据收集器不同的时区中运行的时间。 - 在“JDBC”选项卡上,配置以下 JDBC 属性:
京东财经地产 描述: __________ JDBC 连接字符串 用于连接到数据库的连接字符串。注意:如果在连接字符串中包含 JDBC 凭据,请使用为源创建的用户帐户。Oracle 12c 多租户数据库的常见用户帐户以“c##”开头。有关详细信息,请参阅 任务 3。创建用户帐户。最大批大小(记录) 一次处理的最大记录数。接受的值最高可达数据收集器最大批大小。 默认值为 1000。数据收集器默认值为 1000。
.PDB 包含要使用的架构的可插拔数据库的名称。仅当在可插入数据库中创建架构时使用。 对于在可插入数据库中创建的架构是必需的。
使用凭据 允许在“凭据”选项卡上输入凭据。在 JDBC 连接字符串中不包含凭据时使用。 其他 JDBC 配置属性 要使用的其他 JDBC 配置属性。要添加属性,请单击添加并定义 JDBC 属性名称和值。 按照 JDBC 的预期使用属性名称和值。
- 要将 JDBC 凭证与 JDBC 连接字符串分开输入,请在凭证选项卡上配置以下属性:
凭据属性 描述: __________ 用户名 JDBC 连接的用户名。使用为源创建的用户帐户。Oracle 12c 多租户数据库的常见用户帐户以“c##”开头。
有关详细信息,请参阅任务 3。创建用户帐户。
密码 帐户的密码。 - 使用早于 4.0 的 JDBC 版本时,在“旧版驱动程序”选项卡上,可以选择配置以下属性:
旧驱动程序属性 描述: __________ JDBC 类驱动程序名称 JDBC 驱动程序的类名。对于早于 4.0 版的 JDBC 版本是必需的。 连接运行状况测试查询 用于测试连接运行状况的可选查询。仅当 JDBC 版本早于 4.0 时才建议使用。 - 在“高级”选项卡上,可以选择配置高级属性。
在大多数情况下,这些属性的默认值应该有效:
高级属性 描述: __________ 当前窗口的 JDBC 读取大小 当 LogMiner 会话包含当前时间时,要一起获取和处理的重做日志数。 在会话结束时,源将提取并处理任何剩余的重做日志。
设置为 1 可在源收到重做日志后立即使数据可用。
默认值为 1。
过去窗口的 JDBC 提取大小 当 LogMiner 会话完全过去时,要一起获取和处理的重做日志数。 当读取大小超过可用的重做日志时,源将提取并处理剩余的重做日志。当写入目标系统的速度较慢时,较低的读取大小会增加吞吐量。
默认值为 1。
使用 PEG 解析器(测试版) 允许使用测试版 PEG 解析器,而不是默认的 Oracle CDC 客户端源解析器。可以提高性能,但在生产中使用前应仔细测试。 解析线程池大小 源用于多线程解析的线程数。仅在执行本地缓冲和分析 SQL 查询时可用。 可与默认解析器和 PEG 解析器一起使用。
最大池大小 要创建的最大连接数。 默认值为 1。建议的值为 1。
最小空闲连接数 要创建和维护的最小连接数。若要定义固定连接池,请设置为与“最大池大小”相同的值。 默认值为 1。
连接超时 等待连接的最长时间。在表达式中使用时间常量来定义时间增量。 默认值为 30 秒,定义如下:<span style="color:#333333"><code>${30 * SECONDS}</code></span>空闲超时 允许连接空闲的最长时间。在表达式中使用时间常量来定义时间增量。 使用 0 可避免删除任何空闲连接。
当输入的值接近或大于连接的最长生存期时,数据收集器将忽略空闲超时。
默认值为 10 分钟,定义如下:<span style="color:#333333"><code>${10 * MINUTES}</code></span>最大连接寿命 连接的最长生存期。在表达式中使用时间常量来定义时间增量。 使用 0 不设置最大生存期。
设置最大生存期后,最小有效值为 30 分钟。
默认值为 30 分钟,定义如下:<span style="color:#333333"><code>${30 * MINUTES}</code></span>强制实施只读连接 创建只读连接以避免任何类型的写入。 默认值为启用。不建议禁用此属性。
事务隔离 用于连接到数据库的事务隔离级别。 默认值是为数据库设置的默认事务隔离级别。您可以通过将级别设置为以下任一值来覆盖数据库缺省值:
- 已阅读已提交
- 读取未提交
- 可重复读取
- 序列 化