仅以此篇纪念我的研究生论文研究过程,将不定时的更改,补充
1.爬取数据
本人python 小白一个,短时间学会爬虫实属不易,因此寻了一个比较蠢的办法就是用现成的爬取器。由于我需要翻墙去德国的亚马逊去爬取评论,需要自行准备好梯子。有梯子的一个好处就是可以利用google安装以下两个扩展应用

第一个比较简单,可以自行百度,仅需选中需爬取的评论区的大框架,它会自动将所有内容分类爬取,并可以选择用xlsx或者csv输出 但是后续筛选工作会加重,因为它没有办法选择哪些部分不爬取
第二个在此说一下思路,这个是需要在开发者平台去运作的,普通电脑按下F12即可运作,
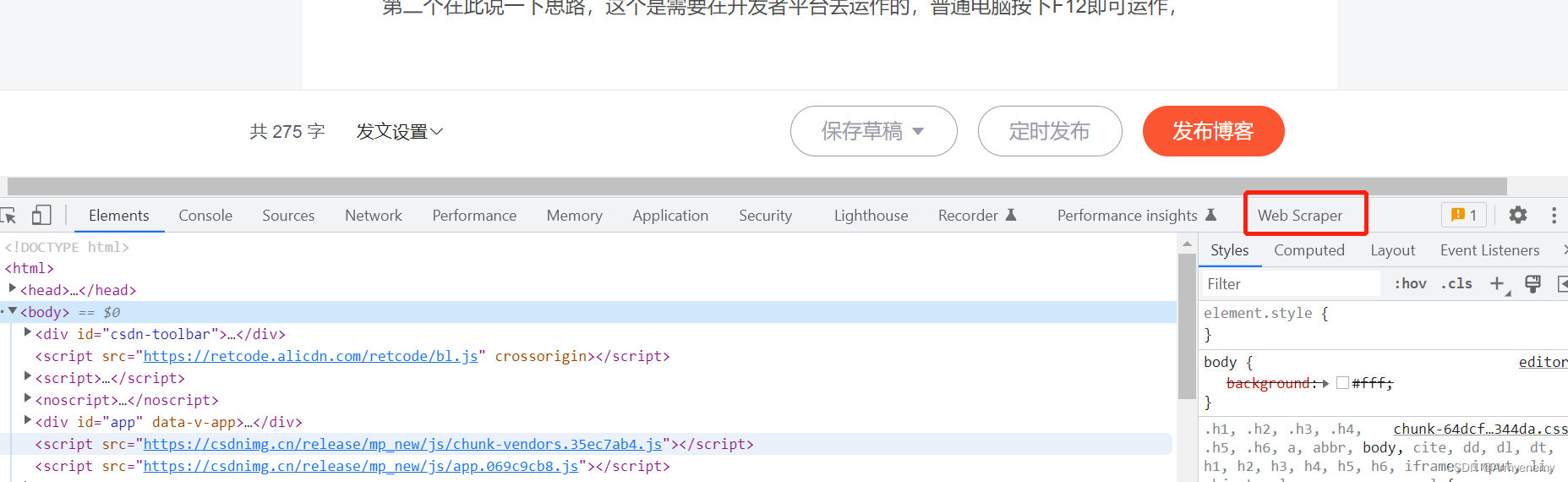

从此处开始新建需要爬取的网页等配置信息

网页链接部分有较多讲究,若网页的翻页具有规律,例如********page1,*******page2等,可以以*****page1-2这种方式链接,也可以点击下方create 进行网页添加翻页较乱的网页
先选择大框,类型选element,点进element,再进行配置,之后在进行解释
2.语言分类
亚马逊的评论不仅仅只有德语,还包含了很多法语,意大利语,西班牙语等等,不同于中英文本质上的不同,也不同于中日韩泰之间,西方语言所使用的字母,语法都是较为接近的,且其unicode使用范围也十分接近。如果仅需英语,或许可以使用正则去 匹配a-A z-Z。
英德的区分十分困难,需要借助python中的langid包才可以进行区分。
但langid包对于英语识别的正确率远不及德语的高,如果可以还是建议使用fasttext等深度学习的工具去对语言进行区分(本人没学会,因此只用langid)
以下是langid使用 方法(真的很白目,换个文件路径就好)
import langid
fileopen = open(r'C:\Users\17438\Desktop\2.txt', 'r', encoding='utf-8', errors='ignore')
lines = fileopen.readlines()
with open(r'C:\Users\17438\Desktop\3.txt', 'w+', encoding='utf-8', errors='ignore') as f:
def lang_by_langid(para_text):
ret = langid.classify(para_text)
print(f"langid:{ret}")
f.write(str(ret))
return ret[0]
for item in lines:
print(f"text:{item}")
tmp = lang_by_langid(item)
f.write(str(item))为本人改进过的版本,输出新的文档,且可以在pycharm中看到结果,知道运行进展。
为啥使用的是text而不是xlsx~( ̄▽ ̄)~*?因为本人电脑上用的是wps,而不是excel。如果不转换为txt格式,德语将会有很多乱码,text自带utf格式,经本人测试过无数,utf-8最适合德语的运行。
运行所得出的结果会是这个样子的,
| ('de', -1262.4733004570007)Die Serienaufnahme für Bilder ist recht flüssig. Ähnlich rudimentär wie auf einem smartphone aber für mich nicht so wichtig. Interessant ist auf jeden Fall die verzögerte Aufnahme. Sie funktioniert für alle Modis. Ob Foto, Video, Serienaufnahme oder Zeitlupe. Dies muss aber in den tieferen Einstellungen vorab eingestellt sein. |
前面的‘de’,是德语的缩写,后面是原始句子,需要自己提取除de,并且提炼后面的句子,此处没有代码,因为我是用wps做的 呜呼!
可以把wps所用函数列出,在此单元格旁,列出 =Right(A1,Len(A1)-FindP(")",A1)) (意思是将第一个右括号后的字符串列出,避免后续文本中存在右括号,又进行分列)
3. 数据预处理
第一步 还原词性
NLTK、spaCy都可以进行词性的还原,本人选择的是spaCy。
需要先在cmd 或者pycharm中安装spaCy。但由于各种原因,下载速度不会很快,建议使用清华源下载。
普通
pip install spacy
快速(此方法最为稳妥,可以解决Cannot determine archive format of xxx的问题)
pip install -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com spacy
其次得去spacy的官网下载对应的链接,
https://github.com/explosion/spacy-models/releases
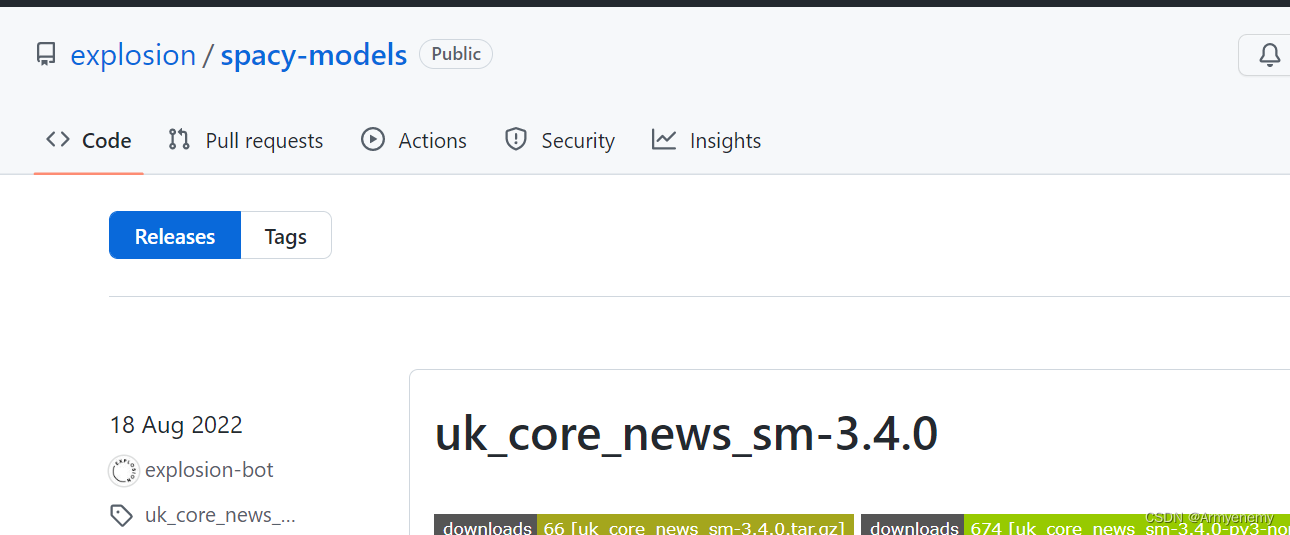
选择tags 涵盖绝大部分语言的spacy模型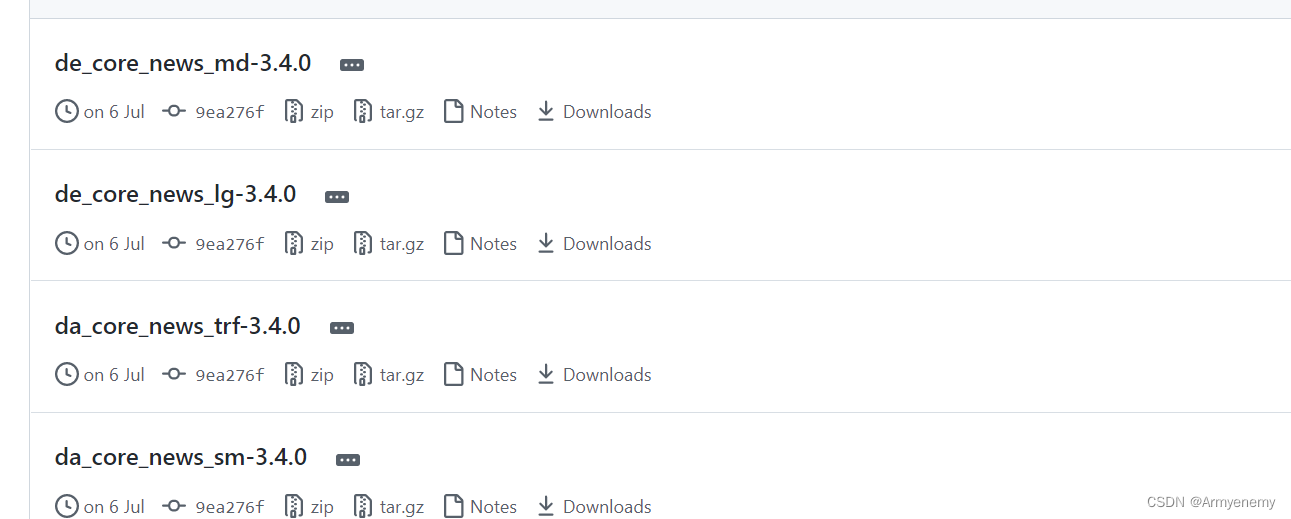
选择自己想要的模型(sm= small md lg= large)
一定要点进链接里去下载,
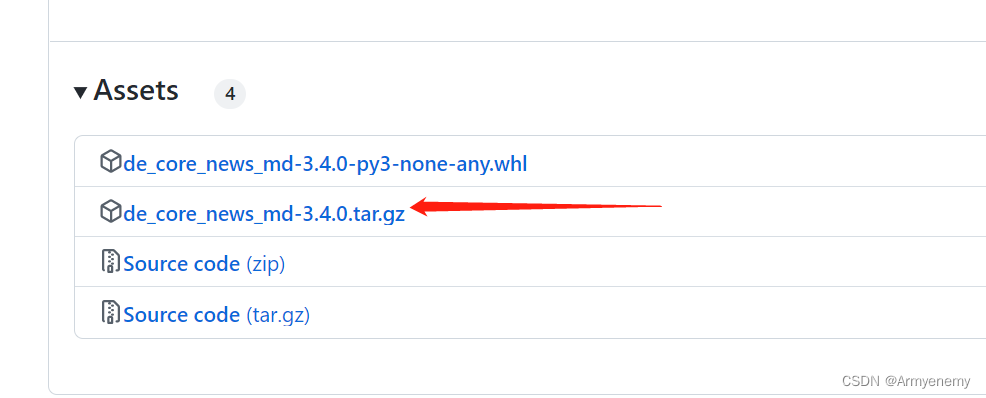
拉到最下方,选择箭头标注的,下载进任意位置
在下载的文件位置

输入cmd后,pip install 压缩文件名字即可
参考文章: python -m spacy dowmload en失败_ICANFLY@的博客-CSDN博客
谢谢此大佬的救命大恩
随后就可以开心的进行词性还原了
import spacy
nlp = spacy.load('de_core_news_md')
file_open = open(r'C:\Users\17438\Desktop\7.txt', 'r', encoding="utf-8", errors="ignore")
mails = file_open.readlines()
mails_lemma = []
with open(r'C:\Users\17438\Desktop\8.txt', 'w', encoding="utf-8", errors="ignore") as f:
for mail in mails:
doc = nlp(mail)
result = ' '.join([x.lemma_ for x in doc])
mails_lemma.append(result)
print(result)
f.write("".join(result))
大概结果如下
vermutlich werden ich sich ein anderer Drucker zulegen
非常的还原词性
第二步 删除停用词
词性还原后需要对其进行TF-IDF(对于关键词进行提取),但是常理来说,每句话都会有人称代词,还有些没有实际意义的词。而这些词在每一句话中都会存在,如果不将其去除的话,会影响TF-IDF的最终结果。而这些词被叫做停用词,对于停用词的引用可以借助nltk库。
调用停用词库的代码如下
from nltk.corpus import stopwords
words = stopwords.words('german')
print(words)此处我调用的是德语的停用词
nltk的停用词库较为广泛,包含了以下语言的停用词库
arabic, azerbaijani, danish, dutch, english, finnish, french, german, greek, hungarian, indonesian, italian, kazakh, nepali, norwegian, portuguese, romanian, russian, slovene, spanish, swedish, tajik, turkish
但是此处的停用词库仅仅是最基础的停用词库,需要根据你对不同的数据要求进行添加或者筛选
ps:补充一点贼有用的 如果想将,转换为转行符号,将,替换为^p
对于文本的处理我更习惯于用txt文件,比起xlsx,csv等文件,txt对于小语种的包容度更高,不是说xlsx和csv不可以处理小语种,但是需要自己选择对应最适合语言的存储方式,比较麻烦,而且运行后的结果可能有乱码的风险。
以下是停用词使用的代码,部分库是为之后做词云等可视化,可以自行删除,或者保留
# coding=utf-8
import jieba
def stopwordslist():
stopwords = [line.strip() for line in open(r'C:\Users\abm\Desktop\停用词典.txt', encoding='UTF-8',
errors="ignore").readlines()]
return stopwords
# 对句子进行中文分词
def seg_depart(sentence):
# 对文档中的每一行进行中文分词
sentence_depart = jieba.cut(sentence.strip())
# 创建一个停用词列表
stopwords = stopwordslist()
# 输出结果为outstr
outstr = ''
# 去停用词
for word in sentence_depart:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
# 给出文档路径
filename = r"C:\Users\abm\Desktop\3.txt"
outfilename = r"C:\Users\abm\Desktop\result.txt"
inputs = open(filename, 'r', encoding='UTF-8', errors="ignore")
outputs = open(outfilename, 'w', encoding='UTF-8', errors="ignore")
# 将输出结果写入ou.txt中
for line in inputs:
line_seg = seg_depart(line)
outputs.write(line_seg + '\n')
outputs.close()
inputs.close()
print("删除停用词和分词成功!!!")
此代码我运行过可以成功,但是结果呈现的时候,单词与单词之间的空格较多 需要进行处理
处理办法如下:
# 创建一个变量并存储我们要搜索的文本
search_text = " --"
# 创建一个变量并存储我们要添加的文本
replace_text = " "
# 使用 open() 函数以只读模式打开我们的文本文件
with open(r'C:\Users\17438\Desktop\text.txt', 'r', encoding='UTF-8') as file:
# 使用 read() 函数读取文件内容并将它们存储在一个新变量中
data = file.read()
# 使用 replace() 函数搜索和替换文本
data = data.replace(search_text, replace_text)
# 以只写模式打开我们的文本文件以写入替换的内容
with open(r'C:\Users\17438\Desktop\text.txt', 'w',encoding='UTF-8') as file:
# 在我们的文本文件中写入替换的数据
file.write(data)
# 打印文本已替换
print("文本已替换")注意:读取的文件应当同处理后的文件是同一文件,否则将是无效修改
上述代码在处理德语文本时发现变音符号两侧都出现了一个空格,建议先处理变音符号的空格,在修改文本中多余一个的空格部分(私心将德语变音列出,方便处理 Ä ä Ö ö Ü ü ß )
此处经检验补充一点,国外较多时候会使用文字表情符号,类似于: ),; )这些表情可以在这一步处理掉,下方的代码没有太智能,如果标点符号中间有空格等,是无法完全删除干净的
经测验速度贼快 请放心使用
这个代码可以替换任何像替换的字或者符号,如果不嫌麻烦,标点符号和表情符号都可以用这个代码,但是本人觉得略麻烦,找了一下去除标点符号和表情符号的代码,如下
#This program reads in a file
#and remove all symbols within a file and
#output the new data to a new file
#Created by: TheOnionSeed-Tri Do
import re
file = open(r"C:\Users\17438\Desktop\text.txt", "r", encoding="utf-8", errors="ignore")#change origDictionary.txt with an old file
outputFile = open(r"C:\Users\17438\Desktop\text1.txt", "w", encoding="utf-8", errors="ignore")#the new file that we will write to
#read the original file by getting each line
contents=file.read()#contents is a list with all the lines
file.close()
outputContents = re.sub('[-!$%^&*()@#_+|~=`{}\[\]:";\'<>?,.\/]','', contents)# replace all
# ''中也可以替换成其他的符号
the symbols with an empty character
#output the new string to a new file
outputFile.write(outputContents)
outputFile.close()源代码链接:https://github.com/L-Unions/WASSA-2018-Implicit-Emotion-Shared-Task-Data
表情符号的删除需要用到demoji这个库,请亲们提前安装对应的库哦
运用代码如下
# -*- coding: UTF-8 -*-
import os
import demoji
file_path = r"C:\Users\17438\Desktop\result.txt"
final_file = r"C:\Users\17438\Desktop\1.txt"
# 如果final_file文件存在,则删除
if os.path.exists(final_file):
os.remove(final_file)
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
# 替换表情符号为 空
rap_line = demoji.replace(line, "")
# 写入文件
with open(final_file, 'a', encoding='utf-8') as f:
f.write(rap_line)速度会比上面直接替换空格、变音符号的运行慢很多,但是是可以成功的
注意 一定不要将处理文件和存储文件命名成一样的,不然文件会自动被删除掉,名称最好取的不太一样一点。
最后记得浏览一下文本是否处理干净 剩余无法处理的部分建议用re替换
经过上述处理之后,文本已经预处理的差不多了,之后需要将所有的文本合并在一起
还差最后一步,就是在总合文件中进行筛选,删除重复的行。代码如下
# 去除重复行
num = 0
oriTxt_path = "C:/Users/abm/Desktop/python/第二步结果.txt" # 包含重复字段的文本
genTxt_path = "C:/Users/abm/Desktop/python/第三步结果.txt"
lines = set()
outfile = open(genTxt_path, "w", encoding="utf-8", errors="ignore")
with open(oriTxt_path, "r", encoding="utf-8", errors="ignore") as f:
for line in f:
if line not in lines:
num += 1
outfile.write(line)
lines.add(line)
outfile.close()
# 去除空白值
file1 = open('C:/Users/abm/Desktop/python/第三步结果.txt.txt', 'r', encoding='utf-8') # 打开要去掉空行的文件
file2 = open('C:/Users/abm/Desktop/python/第三步结果1.txt', 'w', encoding='utf-8') # 生成没有空行的文件
for line in file1.readlines():
if line == '\n':
line = line.strip('\n')
file2.write(line)————————————————
补充
后续进行关键词提取时,发现忘记处理字母大小写
此处补上
in_file = open(r'C:\Users\Armyenemy\Desktop\总2.txt', 'r', encoding="utf-8", errors="ignore")
out_file = open(r'C:\Users\Armyenemy\Desktop\总3.txt', 'w', encoding="utf-8", errors="ignore")
lines = in_file.readlines()
for i in lines:
out_file.write(i.lower())
in_file.close()
out_file.close()