作者:钱佳卫,研发工程师,产品研发和工程架构部-Client Infrastructure-App Infra-DevOps-Developer Tools
前言
CocoaPods 云端分析能力是字节跳动的终端技术团队(Client Infrastructure) 下 Developer Tools 部门提供的一系列云化基础设施之一, Developer Tools 团队致力于建设下一代移动端云化基础设施,团队通过云 IDE 技术、分布式构建、编译链接等技术,优化公司各业务的研发和交付过程中的质量、成本、安全、效率和体验。
一、背景
iOS 组件化研发模式下,CocoaPods 已然成为 iOS 业界标准的依赖管理工具。但随着业务能力不断拓展迭代,组件数量不断增多,导致App工程复杂度急剧增大,依赖管理效率严重下降,甚至出现潜在的稳定性问题。为了能够更快、更稳定得管理大型项目的组件依赖,iOS build 部门打造了一套中心化依赖管理服务——云端依赖分析,从工具链的层面收敛了依赖管理流程,加速了决议速度,聚合了失败问题。
二、什么是云端依赖分析
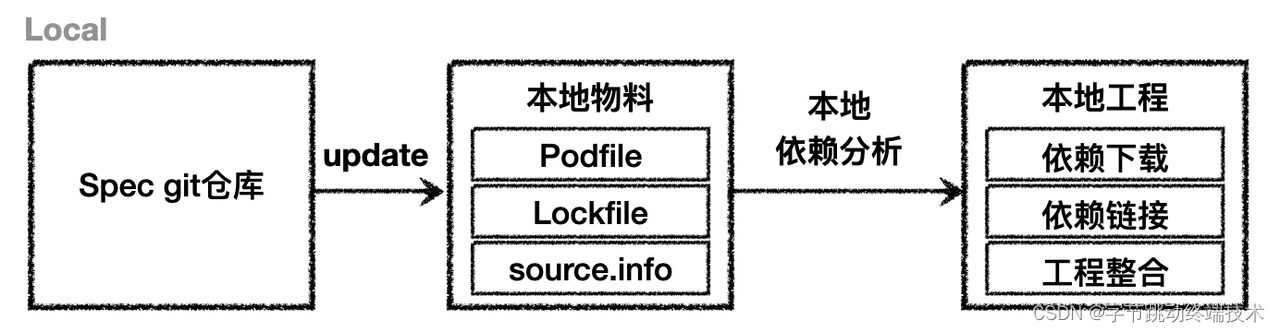
基于 CocoaPods 的 iOS 工程管理,每次执行 pod install,都需要先将组件索引信息 Spec 仓库同步到本地,一般都依靠于 git 仓库的 clone,然后读取 Podfile、Lockfile 以及其他配置文件,开始进入依赖分析、依赖下载、工程整合等几个步骤。
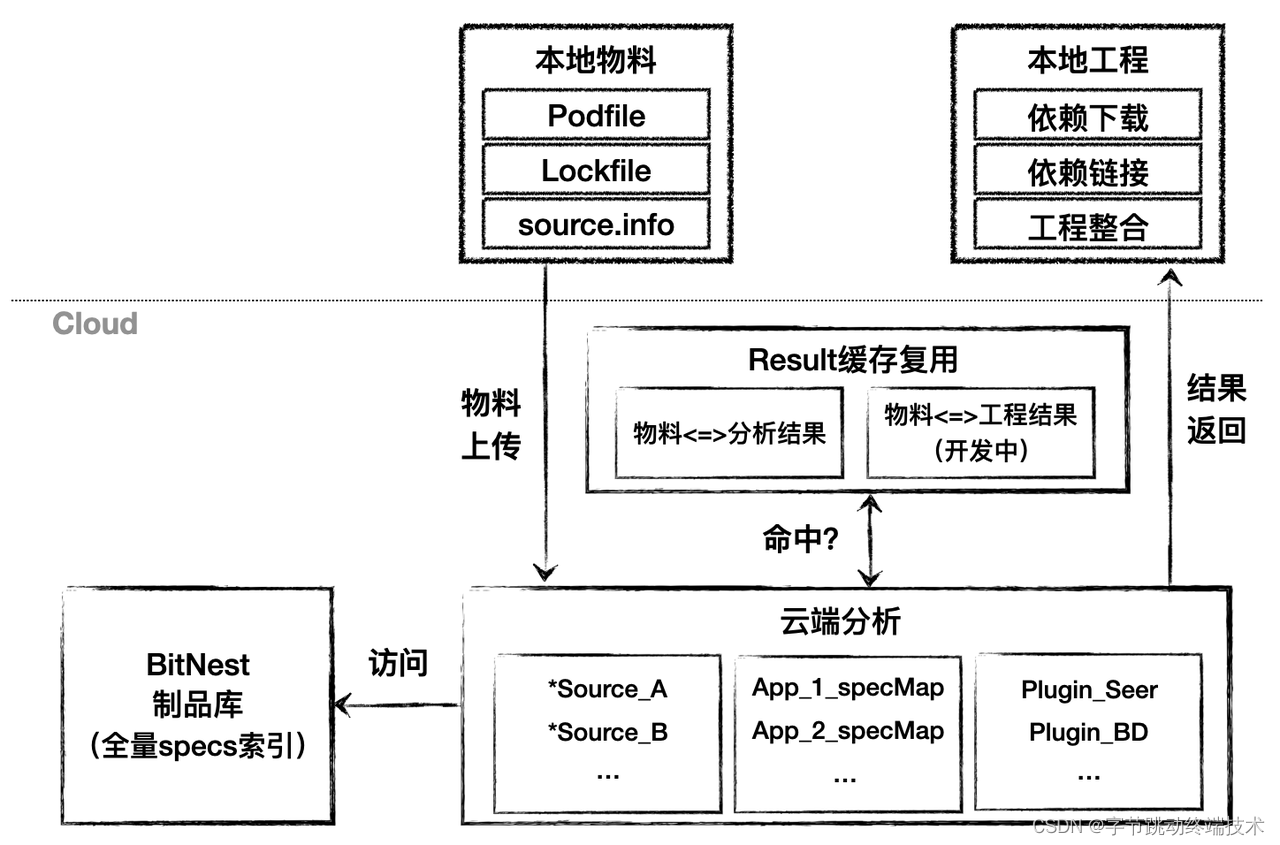
云端分析是一个依赖于字节跳动自研制品库平台,通过工具链上传本地工程构建物料,快速返回依赖分析结果,中心化管理 iOS 工程依赖的云端服务。云端分析服务会依赖于制品库提供所有组件索引信息;并且通过云端分析本地工具在环境准备过程中获取本地工程物料,统一上传至云端进行依赖决议任务,云端借助于一系列优化手段以及服务器性能,快速返回一个决议结果,本地接收到决议结果之后进行后续的依赖下载与工程整合过程。
云端分析的接入方式也极其容易,不需要增加配置文件,也不需要修改原有研发模式,以无侵入、无接入成本、不影响研发流程的方式接入到工程项目中。唯一需要做的,仅仅是在 CocoaPods 工具链中加入云端分析的 RubyGem 插件,并在 pod install 命令中增加一个开启优化功能的控制开关参数。
三、如何加速决议
3.1 制品库 (全量组件索引信息)
基于 Cocoapods 的 iOS 开发体系对 iOS 的产物管理是非常粗放的,直接将不同的 git 仓库作为构建产物(podspec 文件)的索引仓库,担当了制品库的角色。随着 iOS 工程的复杂化,git 仓库的文件信息增加导致组件索引信息查询困难,仓库的同步速度缓慢。BitNest 制品库是公司自研的移动端的产物管理系统,用于管理持续集成过程中所产生的构建产物。制品库将分离在各个 git 仓库的 podspec 源进行了中心化的管理,通过一套完整的 CLI 指令,能够快速拉取、查询 podspec 信息。云端分析服务借助于制品库能力的帮助,能够在云端实时访问一个全量完整的 podspec 源信息。每次CocoaPods 任务都不需要再去更新 podspec 源信息,也不会因为不及时更新 podspec 源信息而找不到最新发版的组件 podspec 信息。
3.2 缓存机制
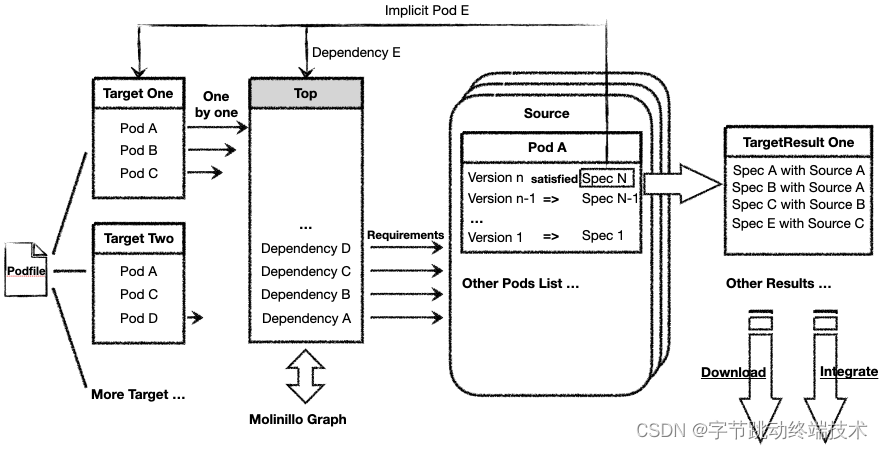
在介绍缓存机制之前,先简单介绍一下 pod install 中依赖分析的运行流程。在第一次执行的时候(忽略 lockfile),CocoaPods 会通过 DSL 从 Podfile 中读取具体的 plugin,source,target,pod 等内容,创建相应的对象完成准备阶段。在每个 Target 对象中每个 pod 都创建成了 Dependency 对象,并且都会有具体的 Requirements 对象。所有 Target 对象的所有 Dependency 对象都逐个被加入到堆栈中,并创建一个 Graph 依赖节点图。每个 Dependency 对象根据其 Requirements 去对应的 Source 仓库寻找对应的 pod,如果 Requirements 中没有仓库信息,就从 podfile 公共 Source 中遍历寻找。找到对应的 pod 之后,会先建立一个版本列表,并从版本列表中找出所有符合 Requirements 要求的 pod,然后读取对应是 podspec 文件内容。决议中会对 Spec 对象中隐式的 pod 创建新的 Dependency 加入到分析堆栈和 Graph 中。如果某个版本的 Spec 在遍历 Graph 依赖图时不满足另一个同名依赖的 Requirements,就会进行出栈回撤和依赖图回撤,直至所有 Dependency 都被找到对应的 Spec 对象为止,分析就完成了。可见,在 CocoaPods 依赖管理过程中,有大量重复的对象创建和排序查找过程,极大的降低了研发效率。试想,让 CocoaPods 任务所需的对象一直保持就绪状态,每当收到任务请求立即执行依赖分析工作,就可以快速返回结果。云端分析服务集中化了所有 CocoaPods 的依赖管理任务,针对重复的工作搭建了对象缓存机制。采用懒加载的模式,对新增对象进行缓存,在下一次任务进来之后立刻进入依赖决议过程。
3.2.1 排序 Version 缓存
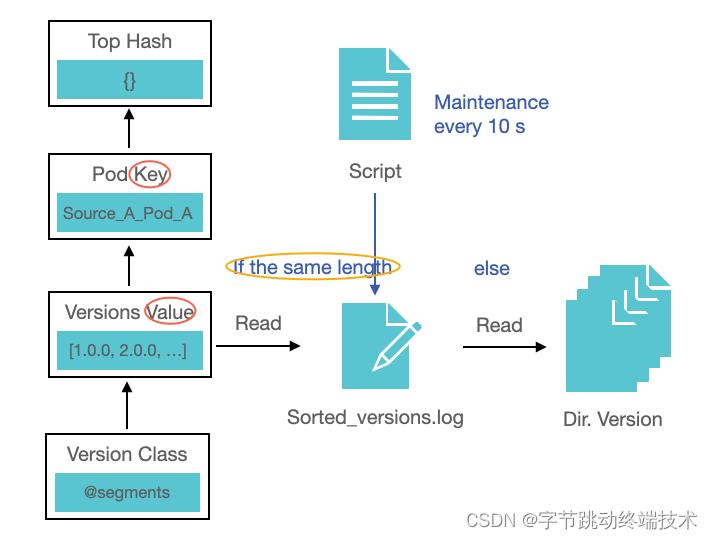
在分析每个 pod 时,为了能获取最新版本的 pod 依赖,CocoaPods 会对 source 仓库中的所有版本号建立对应的 Version 对象,并进行排序。目前,公司内部大部分制品版本已经达到上万的数量级,而且在不指定 source 源的情况下,二进制版本和源码版本都会被排序并读取,最终获取一个满足要求且最新的版本。由于组件版本号都以 “.” 和 “-” 分段,大部分组件版本都存在4个或者5个字段以上。这也致使上万个组件在进行排序的过程中,每次排序对比都需要遍历4次以上,使时间复杂度提升了好几倍,极大得增加了耗时。
为了更快得获取到有序的版本列表,由制品库服务维护了所有 pod 组件从大到小排序的版本文件;每增加一个新的 pod 版本,制品库都会向文件中插入一个新版本;删除时,则会删除相应的版本字段。
有了有序的版本文件,云端分析增加 Version 缓存的主要目的是为了将版本分段信息一直维持在 Version 对象中,可以快速判断当前 Version 是否满足依赖的要求。Version 缓存可以让依赖管理过程提速大约10-12秒左右。
云端分析在无版本缓存的情况下,会优先读取版本文件中的数据,直接获得有序的版本列表;如果版本列表长度与 source 中组件版本目录长度不一致,会回退到原始方法(版本列表出错,确保分析的正确性)。在缓存命中的情况下,也需要判断缓存版本列表长度是否与 pod 版本目录长度相等(有新增版本,缓存未新增),则会从版本列表数组中查找出差异版本,并对缓存进行修正。
3.2.2 Spec 对象缓存
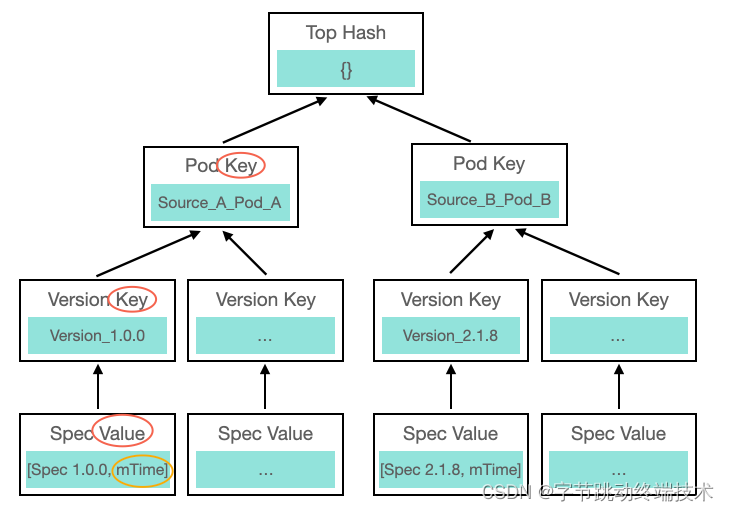
CocoaPods 在从排序版本中查找满足依赖要求的 podspec 时,会将所有满足依赖要求的 podspec 版本内容全部读取进来,进行依赖决议遍历。如果在不注明具体版本的情况下,所有版本的 podspec 文件都将被读取,并且在不注明具体 source 源的情况下,所有 source 存在的 pod 也都会被读取。一万个 podspec 文件读取就需要花费 30 秒左右(据不同磁盘而定) 。
云端分析会对每次分析任务 IO 读取的 podspec 文件内容进行缓存。在下次任务获取 Spec 对象时,可以根据 source,pod_name,version 三个字段直接得到对应的Spec对象。
同时,为了确保 Spec 的正确性,防止 Spec 在不改变版本而更改内容的情况出现。Spec 对象缓存是以一个多维数组的形式存在,通过判断 podspec 文件的修改时间,来更新缓存中的 podspec 内容为最新提交的,确保 checksum 计算与本地拉仓依赖分析的计算值相同,实现云端依赖分析的正确性。后续,也会增加 Spec 缓存命中次数,Spec 对象过期时间等,实现 Spec 缓存的清理策略。
3.2.3 缓存复用
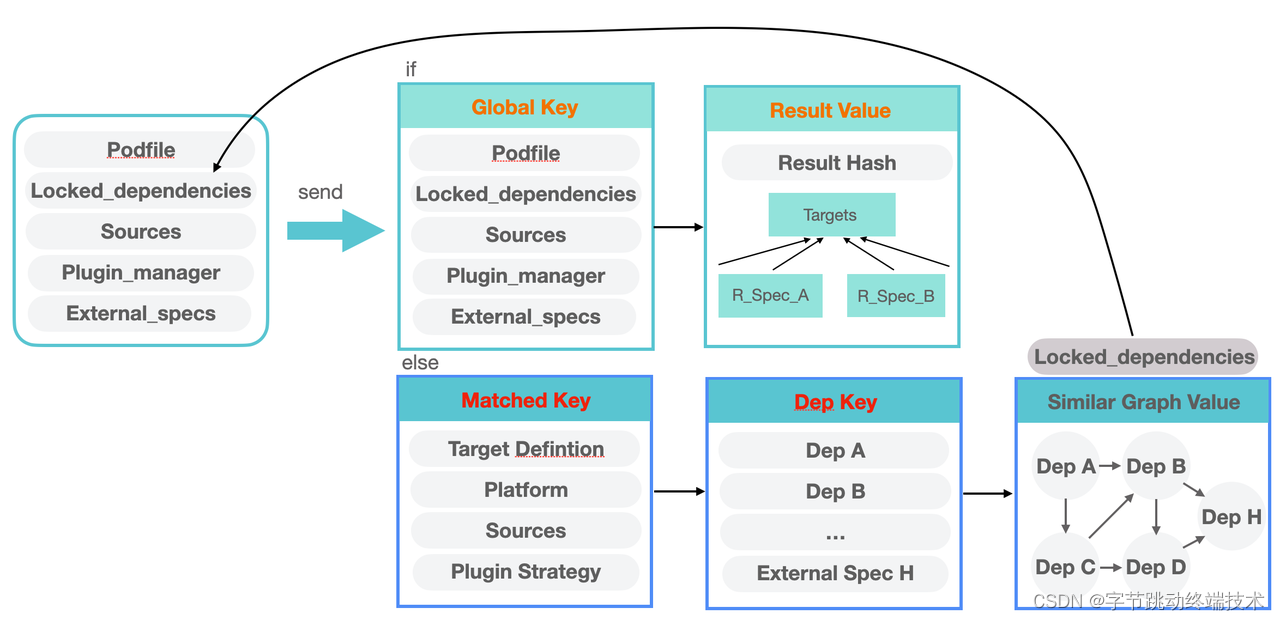
云端分析也会对分析结果进行缓存,下一次遇到相同的分析任务能够直接复用。云端在获取一次物料之后,会对物料做一次全局 hash 计算和一次分段 hash 计算,分别缓存完整的分析结果和分析结果图 Graph。针对下一次分析任务,如果是完全相同的物料可以直接返回一个可用的完整分析结果;如果未匹配,会通过一些 target,platform 等信息计算出一级平台信息 key,来确定具体 app 信息;再对所有target 下的组件依赖逐个计算 hash 值,获得二级 hash 数组 key,并对应一个分析结果图 Graph value;通过模糊匹配的方式对 hash 数组 key 进行匹配,匹配到依赖个数相同最多的相近图,来替换物料中的 locked_dependencies,来加速分析。当然,模糊匹配能力也有一定的局限性,无法对原本上传 lockfile 物料的分析任务进行加速。
3.3 物料剪枝
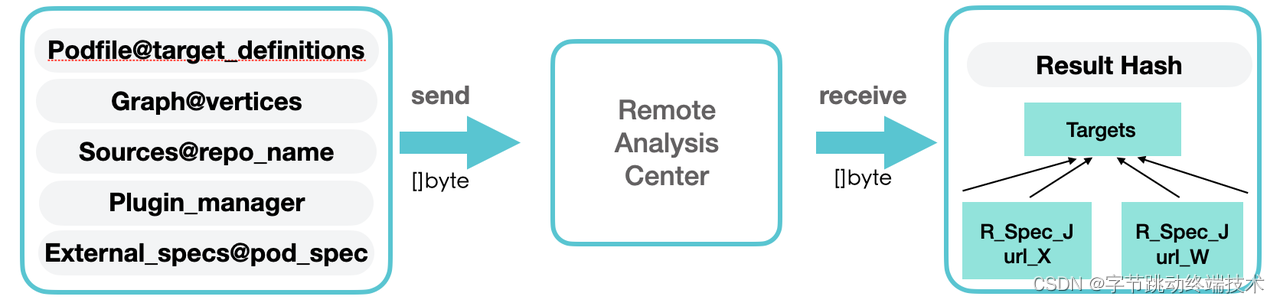
云端分析会将 CocoaPods 对象转变为字节流进行传输。具体的上传物料与分析结果具体如下:
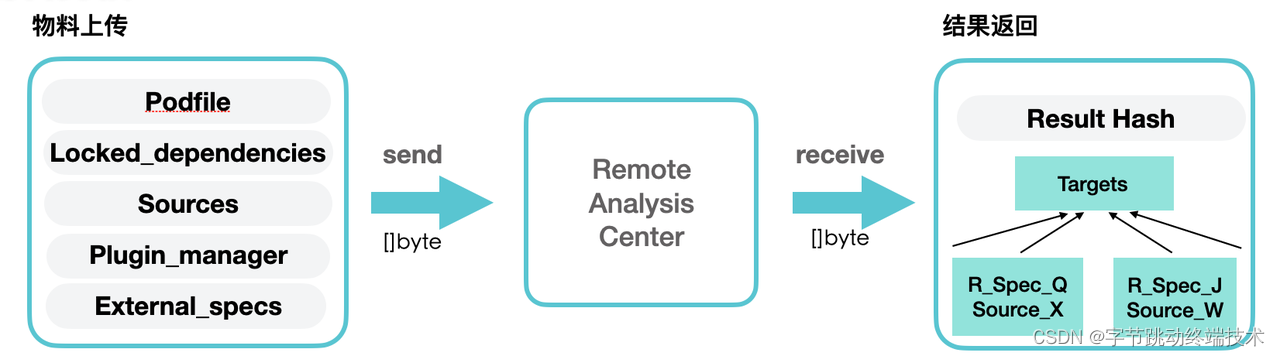
1. 上传物料
云端分析工具链会将 Podfile 对象、lockfile 生成的 Molinillo Graph 对象、指定的 Source 对象、插件适配器,所有的外部源 Specs 对象(具体为指定 git,path 和 podspec 的 pre-release 对象)作为上传物料。但其实,云端分析并不需要这些本地对象的全部信息,可以对这些对象进行剪枝,例如 Podfile 对象仅需要 target_definitions 的链表即可;Molinillo Graph 对象仅需要所有 pod 对应的节点,而不需要记录操作节点的 log;Source 对象仅需要知道 name 和 repo_dir 即可,等等。其中,部分决议优化插件需要通过插件适配器额外传输一些配置 Config 对象。
2. 结果返回
云端分析返回的结果为以 Target 为 key,相应的 Specs 数组为 value 的 hash 对象。结果返回之前,会先对所有 Spec 的 Source 进行剪枝。由于每个 Spec 对应的 Source 在后续流程中仅使用到 url 的字段进行分类与生成 lock 文件。因此,可以删除 Source 对象其他无用的字段,最小化传输内容,加快响应时间。对返回结果进行剪枝后,传输内容大小可以减少大约10MB以上。
3.4 决议策略兼容
为了确保决议结果的正确性和唯一性(single truth),云端分析兼容了字节跳动内部各 CocoaPods 决议策略优化的工具链。根据工程中构建配置参数,云端分析本地插件识别出具体的决议策略,并传递到云端分析服务器并激活对应决议策略算法进行快速决议。同时,结合已有的决议优化策略和云端的优化加速机制,让 CocoaPods 的依赖管理流程达到秒级返回。
四、总结
本文主要分享了目前字节跳动内部的一种 CocoaPods 云端化的优化方案,针对大量重复的 iOS 工程流水线构建任务进行了收敛和复用,在保证依赖决议正确性的前提下加速了依赖管理速率,提升了研发效能。目前云端分析服务已经完成第一阶段的开发并落地使用,已被公司内部几个核心的生产线使用。如头条接入云端分析服务后,pipeline 的依赖分析阶段耗时加速60%以上。后续,对于 CocoaPods 的下载优化,工程缓存服务也已经在技术探索中,相关技术文章将陆续分享,敬请期待!
扩展阅读
CocoaPods优化:https://www.infoq.cn/article/adqsbwtvsyzuvh429p8w
加入我们
我们是字节的 Client Infrastructure 部门下的 Developer Tools 团队,团队成员由 IDE 专家及构建系统专家组成,团队致力于通过客户端云化技术以及编译构建技术,优化公司各业务的研发和交付过程中的质量、成本、安全、效率和体验。同时,在实践的过程中我们也看到了很多令人兴奋的新机会,希望有更多对编译工具链技术感兴趣的同学加入我们一起探索。
职位链接
【扫码投递简历】