回归的概念:(其实就是用曲线拟合的方式探索数据规律)

回归问题的分类:
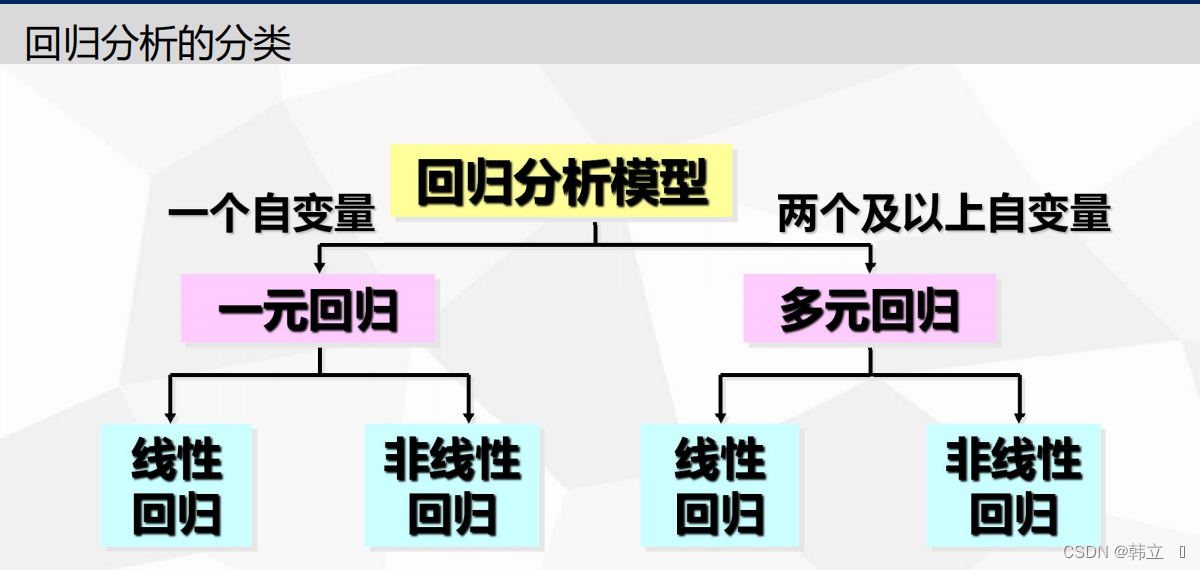
一元线性回归:
线性回归模型是利用线性拟合的方式探寻数据背后的规律。如下图所示,先通过搭建线性回归模型寻找这些散点(也称样本点)背后的趋势线(也称回归曲线),再利用回归曲线进行一些简单的预测分析或因果关系(自变量和因变量分析)分析。
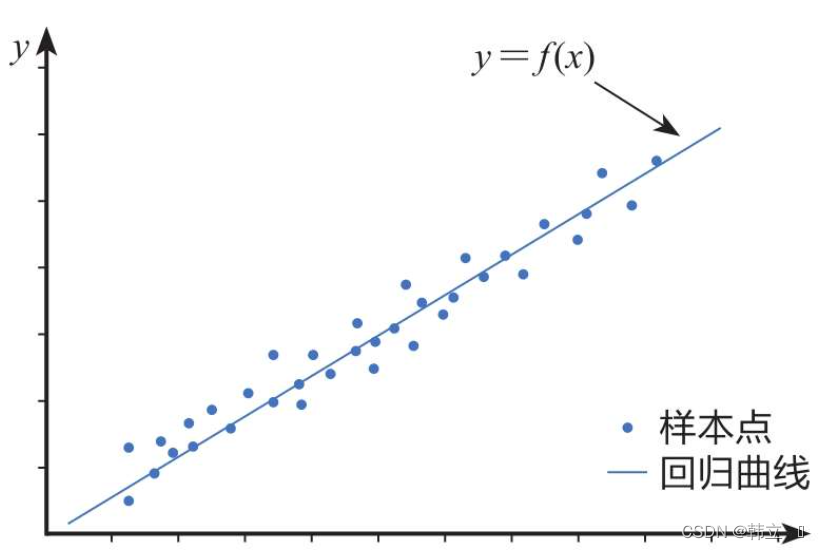
实例:

在线性回归中,根据特征变量(也称自变量)来预测反应变量(也称因变量)。
根据特征变量的个数可将线性回归模型分为一元线性回归和多元线性回归。
例如,通过“人均可制配收入”这一个特征变量来预测“人均消费支出”,就属于一元线性回归;
而通过“人均可制配收入”“行业”“所在城市”等多个特征变量来预测“薪水”,就属于多元线性回归。
一元线性回归的数学原理及其形式:
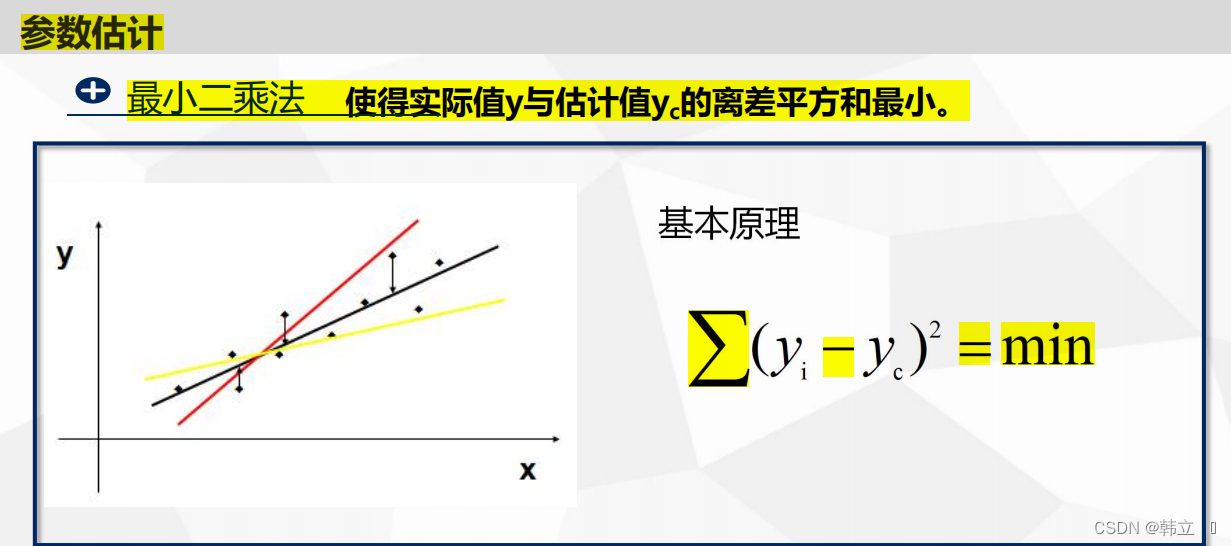


采用偏导数为0,求其最小值(算法都是这个套路,将数据问题转化成参数问题,参数问题转化为极值问题)

结论:

一元线性回归案例:
薪水会随着工龄的增长而增长,不同行业的薪水增长速度有所不同。本案例要应用一元线性回归模型探寻工龄对薪水的影响,即搭建薪水预测模型。
# # 3.1 一元线性回归
# # 3.1.2 一元线性回归的代码实现
# # 3.1.3 案例实战:工作年限与收入的线性回归模型
# 读取数据
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.linear_model import LinearRegression
plt.rcParams['font.sans-serif'] = ['SimHei']
df = pd.read_excel('C:\\Users\\Administrator\\Desktop\\数据挖掘项目\\应用统计学案例\\源代码汇总-案例\\第3章 线性回归模型\\源代码汇总_PyCharm格式\\IT行业收入表.xlsx')
print(df.head())
X = df[['工龄']]
Y = df['薪水']
plt.scatter(X, Y) # 绘制散点图
plt.xlabel('工龄')
plt.ylabel('薪水')
plt.show()
# 3.模型搭建 : 一元线性回归
regr = LinearRegression()
regr.fit(X, Y) # 模型训练
# 4.模型可视化
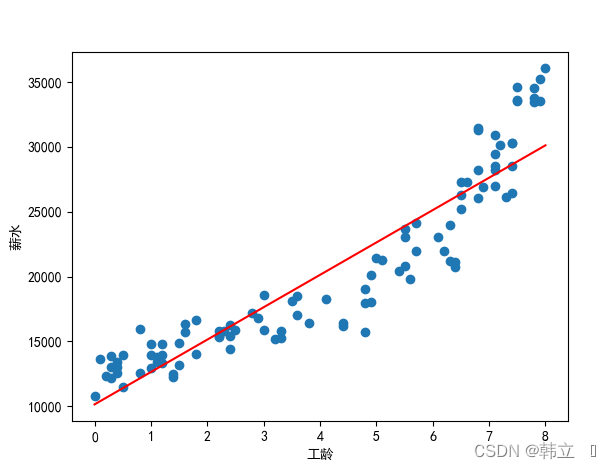
plt.scatter(X, Y)
plt.plot(X, regr.predict(X), color='red') # color='red'设置为红色
plt.xlabel('工龄')
plt.ylabel('薪水')
plt.show()
# 线性回归方程构造
print('系数a为:' + str(regr.coef_[0]))
print('截距b为:' + str(regr.intercept_))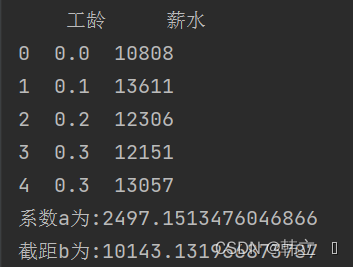
模型优化
一元多次线性回归模型:
之所以还需要研究一元多次线性回归模型,是因为有时真正契合的趋势线可能不是一条直线,而是一条曲线。根据一元二次线性回归模型绘制的曲线更契合散点图呈现的数据变化趋势。
比如一元二次模型:如图(对上图的解释)

代码:
from sklearn.preprocessing import PolynomialFeatures
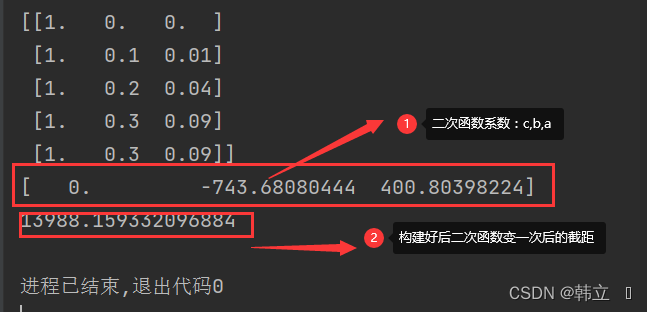
poly_reg = PolynomialFeatures(degree=2) # 构建二次函数 ax*2 + bx +c
X_ = poly_reg.fit_transform(X) # 获取结果
print(X_[0:5])
regr = LinearRegression()
regr.fit(X_, Y)
plt.scatter(X, Y)
plt.plot(X, regr.predict(X_), color='red')
plt.show()
print(regr.coef_)
print(regr.intercept_)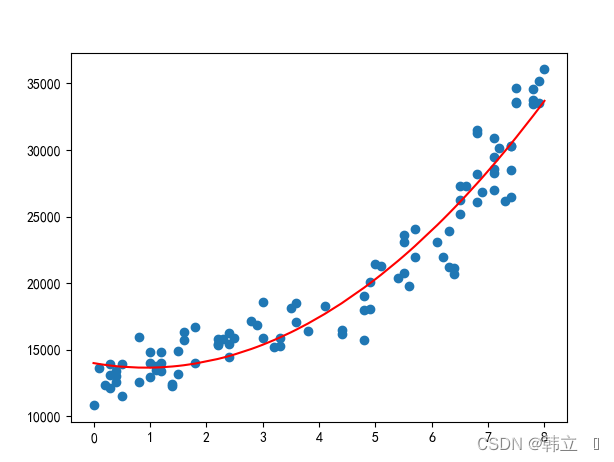
线性回归模型的评估及其显著性检验:

三组概念的理解:
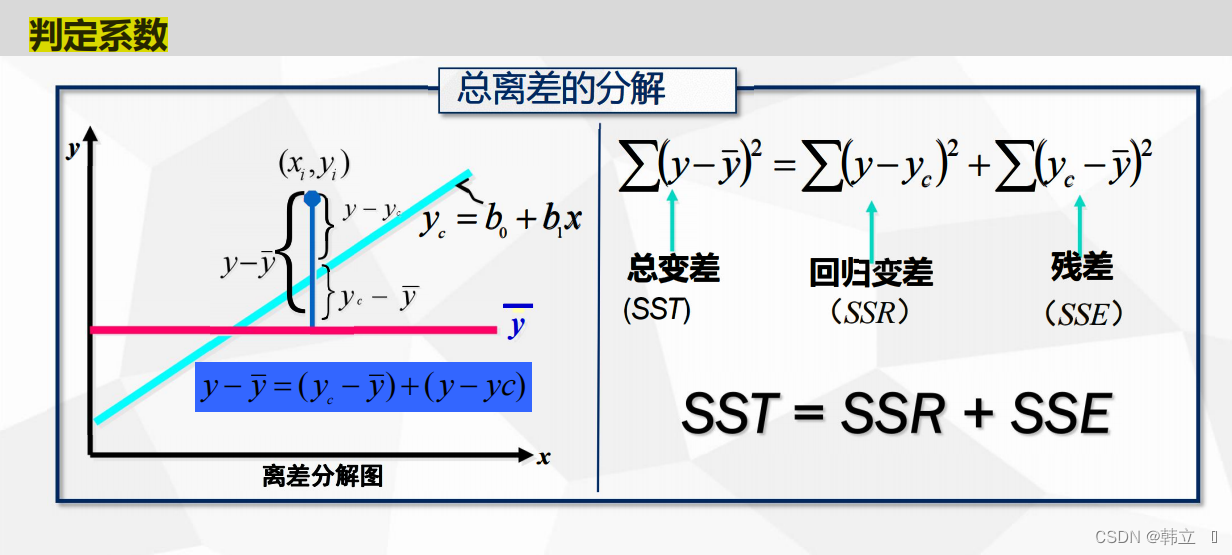
判定系数(R-squared:相关系数的平方)
判定系数含义:

获取R-squared值的另一种方法:
from sklearn.metrics import r2_score
r2 = r2_score(Y,model.predict(X))
线性回归模型的显著性检验(p<0.05:具有显著性):
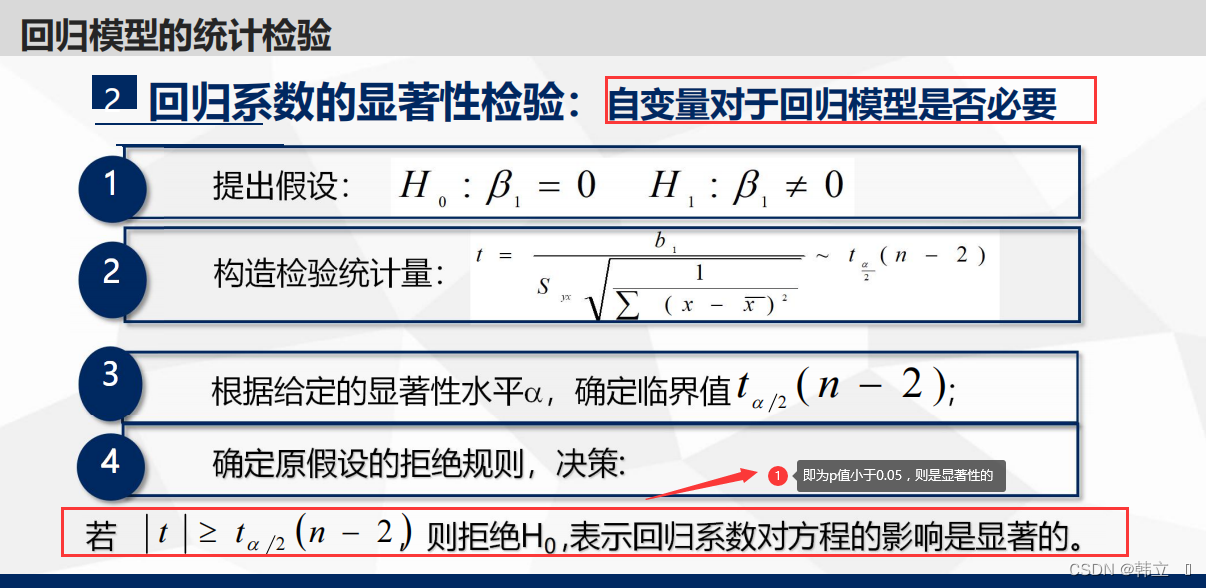
代码:
import pandas as pd
df = pd.read_excel('C:\\Users\\Administrator\\Desktop\\数据挖掘项目\\应用统计学案例\\源代码汇总-案例\\第3章 线性回归模型\\源代码汇总_PyCharm格式\\IT行业收入表.xlsx')
X = df[['工龄']]
Y = df['薪水']
import statsmodels.api as sm
X2 = sm.add_constant(X)
est = sm.OLS(Y, X2).fit()
print(est.summary())
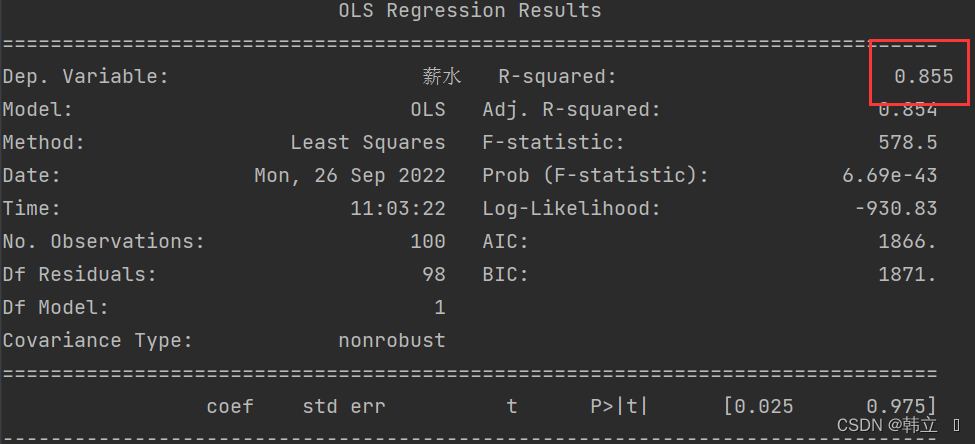
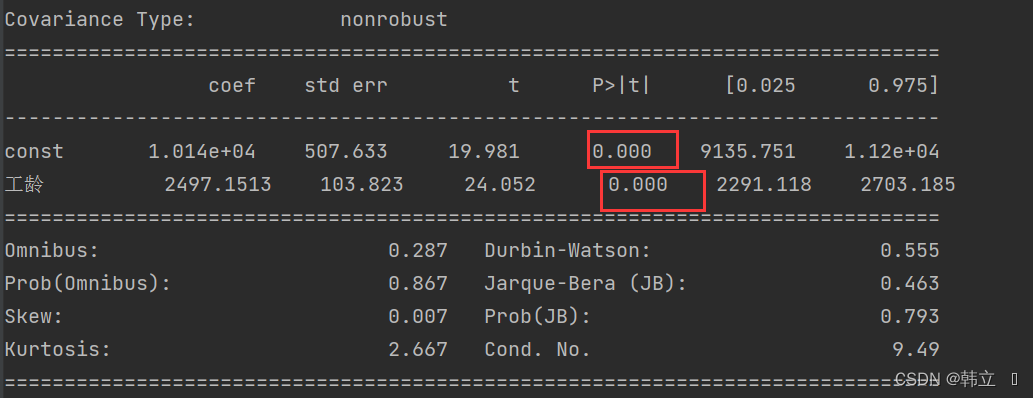
左下角的coef就是常数项(const)和特征变量(工龄)前的系数,即截距b和斜率系数a。
对于模型评估而言,通常需要关心上图中的R-squared、Adj.R-squared和P值信息。这里的R-squared为0.855,Adj.R-squared为0.854,说明模型的线性拟合程度较高;这里的P值有两个,常数项(const)和特征变量(工龄)的P值都约等于0<0.05,所以这两个变量都和目标变量(薪水)显著相关,即真的具有相关性,而不是由偶然因素导致的。
先二次项一元线性拟合:
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree=2)
X_ = poly_reg.fit_transform(X)
import statsmodels.api as sm
X2 = sm.add_constant(X_)
est = sm.OLS(Y, X2).fit()
print(est.summary())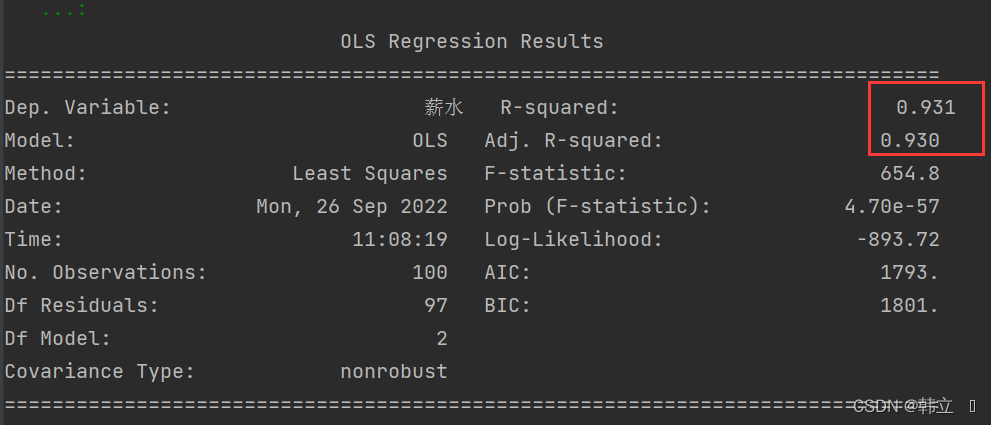
如上图,可以看出R-squared更大,拟合效果越好
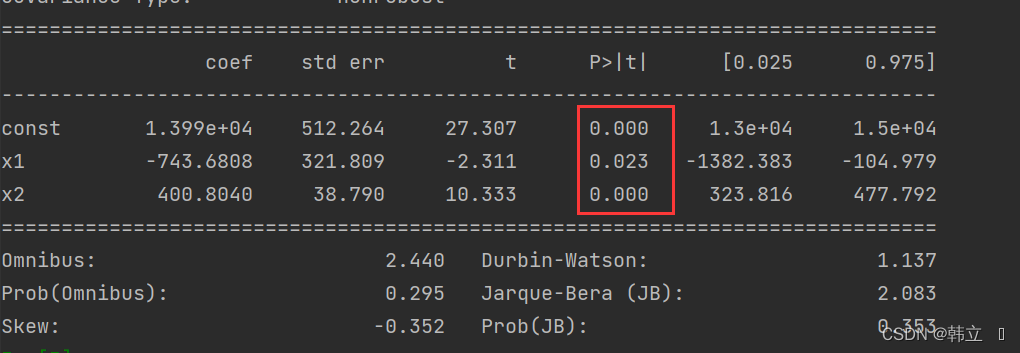
如上图,三个自变量的显著性检验,均小于0.05
最后:采用机器学习库对线性回归进行拟合:
# 1.读取数据
import pandas
df = pandas.read_excel('C:\\Users\\Administrator\\Desktop\\数据挖掘项目\\应用统计学案例\\源代码汇总-案例\\第3章 线性回归模型\\源代码汇总_PyCharm格式\\IT行业收入表.xlsx')
X = df[['工龄']]
Y = df['薪水']
# 2.模型训练
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,Y)
from sklearn.metrics import r2_score
r2 = r2_score(Y, regr.predict(X))
print(r2)
R2(就是统计学习库中的R-squred):
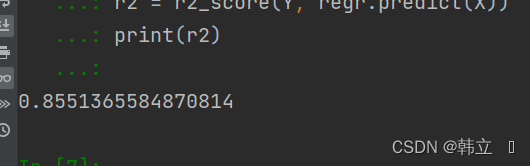
结论:与统计学习库分析一致
全部代码:
# # 3.2 线性回归模型评估
# # 3.2.1 模型评估的编程实现
# 3.1.3 代码汇总 :不同行业工作年限与收入的线性回归模型
import pandas as pd
df = pd.read_excel('C:\\Users\\Administrator\\Desktop\\数据挖掘项目\\应用统计学案例\\源代码汇总-案例\\第3章 线性回归模型\\源代码汇总_PyCharm格式\\IT行业收入表.xlsx')
X = df[['工龄']]
Y = df['薪水']
import statsmodels.api as sm
X2 = sm.add_constant(X)
est = sm.OLS(Y, X2).fit()
print(est.summary())
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree=2)
X_ = poly_reg.fit_transform(X)
import statsmodels.api as sm
X2 = sm.add_constant(X_)
est = sm.OLS(Y, X2).fit()
print(est.summary())
# 1.读取数据
import pandas
df = pandas.read_excel('C:\\Users\\Administrator\\Desktop\\数据挖掘项目\\应用统计学案例\\源代码汇总-案例\\第3章 线性回归模型\\源代码汇总_PyCharm格式\\IT行业收入表.xlsx')
X = df[['工龄']]
Y = df['薪水']
# 2.模型训练
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,Y)
from sklearn.metrics import r2_score
r2 = r2_score(Y, regr.predict(X))
print(r2)
本文含有隐藏内容,请 开通VIP 后查看