在巨大的数据集基础上进行训练速度很慢。优化算法,能让神经网络运行得更快,帮助我们快速训练模型。
Mini-batch 梯度下降
batch梯度下降法指的是梯度下降法算法,就是同时处理整个训练集。
如果样本个数m是500万,在对整个训练集执行梯度下降法时,必须处理整个训练集,然后才能进行一步梯度下降法,然后你需要再重新处理500万个训练样本,才能进行下一步梯度下降法。所以如果你在处理完整个500万个样本的训练集之前,先让梯度下降法处理一部分,你的算法速度会更快。
如果你的训练样本一共有500万个,你可以把训练集分割为小一点的子集训练,这些子集被取名为mini-batch,假设每一个子集中只有1000个样本,也就是说,你有5000个mini-batch。mini-batch梯度下降法,指的是每次同时处理的单个的mini-batchX和Y,而不是同时处理全部X的和Y训练集。
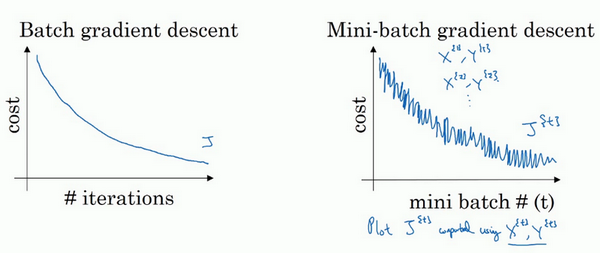
使用batch梯度下降法时,每次迭代你都需要历遍整个训练集,可以预期每次迭代成本都会下降,所以如果成本函数J是迭代次数的一个函数,它应该会随着每次迭代而减少,如果J在某次迭代中增加了,那肯定出了问题,也许你的学习率太大。
使用mini-batch梯度下降法,成本函数在整个过程中的图并不是每次迭代都是下降的,每次迭代下你都在训练不同的样本集或者说训练不同的mini-batch。图像整体走向朝下,但有更多的噪声,噪声产生的原因在于容易计算的mini-batch,成本会低一些。较难运算的mini-batch,或许需要一些残缺的样本,这样一来,成本会更高一些,所以才会出现这些摆动。
如果mini-batch的大小等于m(训练集的大小),其实就是batch梯度下降法。假设mini-batch大小为1,就成了随机梯度下降法,每个样本都是独立的mini-batch。如果mini-batch大小既不是1也不是m,应该取中间值,那应该怎么选择呢?
如果训练集较小(小于2000个样本),直接使用batch梯度下降法,没必要使用mini-batch梯度下降法。样本数目较大的话,一般的mini-batch大小为64到512,大小是2的n次方,代码会运行地快一些。
动量梯度下降法(Gradient descent with Momentum)
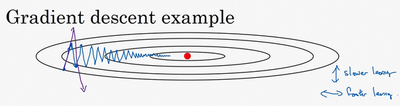
执行梯度下降,虽然横轴方向正在推进,但纵轴方向会有大幅度摆动。
Momentum,或者叫做动量梯度下降法,运行速度几乎总是快于标准的梯度下降算法。简单来说就是计算梯度的指数加权平均数,并利用该梯度更新你的权重。
动量梯度下降法的一个本质:想象你有一个碗,你拿一个球,微分项给了这个球一个加速度,此时球正向山下滚,球因为加速度越滚越快,而因为β稍小于1,表现出一些摩擦力,所以球不会无限加速下去,所以不像梯度下降法,每一步都独立于之前的步骤,你的球可以向下滚,获得动量,可以从碗向下加速获得动量。这些微分项提供了加速度,Momentum项相当于速度。
RMSprop
全称是root mean square prop算法,它也可以加速梯度下降。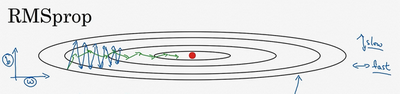
Adam 优化算法
Adam优化算法基本上就是将Momentum和RMSprop结合在一起。

学习率衰减
加快学习算法的一个办法就是随时间慢慢减少学习率,我们将之称为学习率衰减。
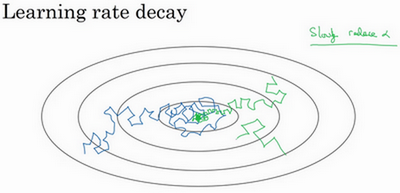
在迭代过程中会有噪音(蓝色线),下降朝向这里的最小值,但是不会精确地收敛,所以你的算法最后在附近摆动,并不会真正收敛,因为你用的是固定值,不同的mini-batch中有噪音。
但要慢慢减少学习率的话,在初期的时候,学习率还较大,你的学习还是相对较快,但随着变小,你的步伐也会变慢变小,所以最后你的曲线(绿色线)会在最小值附近的一小块区域里摆动,而不是在训练过程中,大幅度在最小值附近摆动。