目录
一、 论文摘要
近年来,虚假信息和假新闻对个人和社会造成了危害,假新闻检测引起了广泛关注。现有的假新闻检测算法大多侧重于挖掘新闻内容和/或周围的外生上下文来发现虚假信号;而用户在决定是否传播假新闻时的内生偏好被忽略。确认偏差理论表明,当一则假新闻证实了用户已有的信念/偏好时,用户更有可能传播这条假新闻。用户的历史社交活动(如帖子)提供了丰富的用户新闻偏好信息,对推进假新闻检测具有巨大潜力。然而,针对假新闻检测的用户偏好挖掘工作还比较有限。因此,该文研究了利用用户偏好进行假新闻检测的新问题。本文提出一种新的框架UPFD,通过联合内容和图建模同时捕获用户偏好的各种信号。在真实数据集上的实验结果验证了所提框架的有效性。发布了代码和数据,作为基于gnn的假新闻检测的基准:https://github.com/safe-graph/GNN-FakeNews
二、 模型
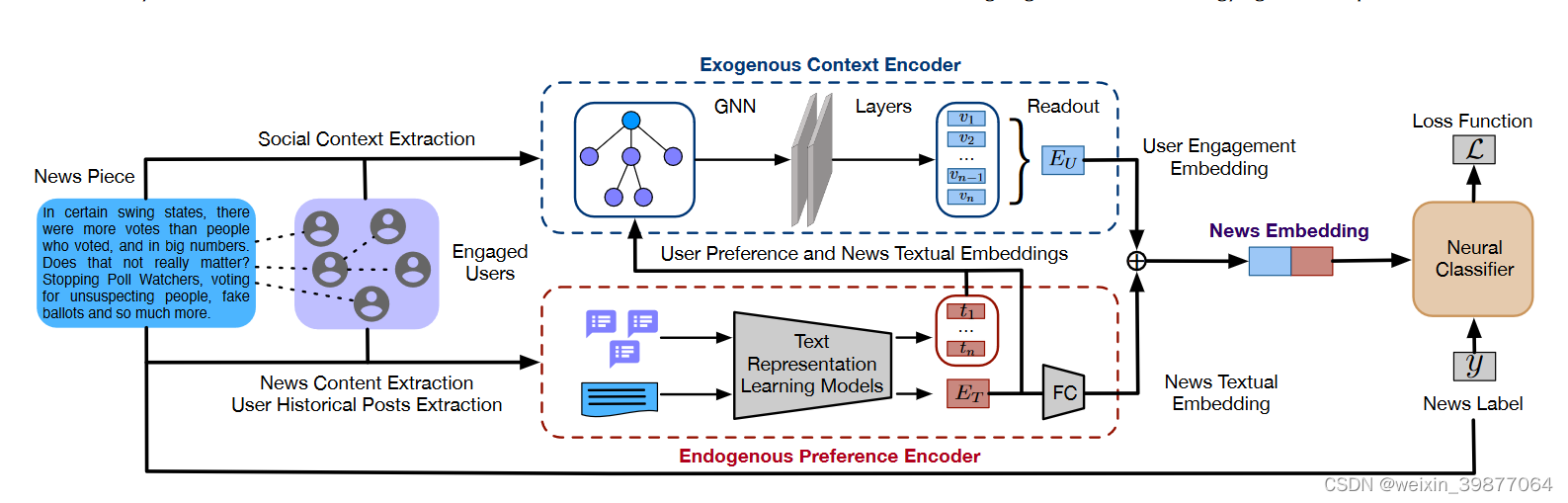
处理任务:虚假信息检测
使用特征:用户偏好 + 新闻语义
1. 内源偏好编码:
使用最近分享的前n条推文,将推文使用bert或者word2vec等表示学习的方式编码后进行平均作为用户偏好编码,新闻语义也用同样的方式进行编码。不过在bert编码的时候,由于推文一般比较短,使用最大输入序列长度为16的输入,新闻则比较长,使用最大长度为512的输入。
2.外部文章编码
将用户内源编码以及新闻编码concat之后作为用户的节点,构造图神经网络。
为构造好一个相对较好的图网络,采用以下规则:
a). 对于账户被暂停或删除的不可访问用户,我们使用从可访问用户中随机抽样的推文,这些推文与对应的历史帖子具有相同的新闻。
b). 对于一个账户vi,它转发该条新闻的的时间比前n个账户慢,这里我们假设前n个账户已经按照时间戳排序,那么账户vi 转发的新闻就来源于第n个账户,即和vi时间最接近的账户作为vi的新闻转发来源。
c). 如果帐户Vi没有关注任何一个账号包括源帐户,作者认为该账户转发的新闻来源于推特上关注者最多的账户,因为他们所发的推文被转发的概率最大。
简单对每个用户进行交互融合之后使用readout函数进行每个节点用户的读取,进行平均池化,得到用户编码,结合新闻内容编码进行检测。
实验
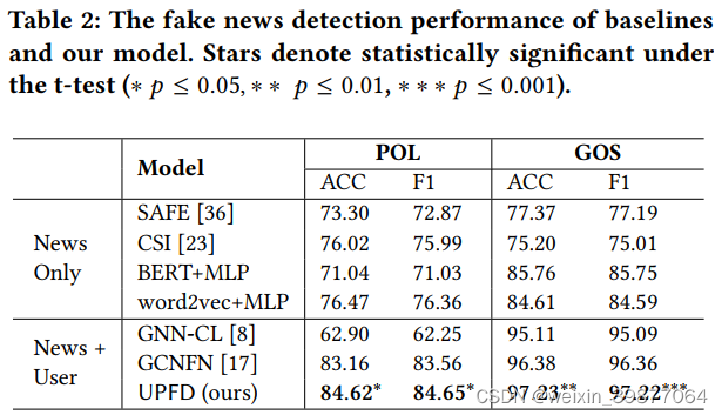
1. 有无用户偏好模块的比较
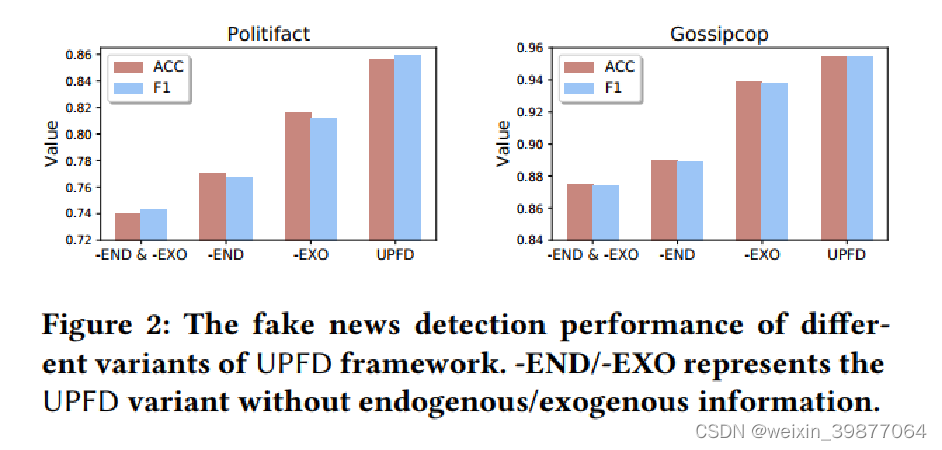
2. 消融实验
四、 结论
该文认为用户内生的新闻消费偏好在假新闻检测问题中起着至关重要的作用。为了验证这一观点,该文收集了用户发布的历史消息,隐式地建模了用户的内生偏好,并利用社交媒体上的新闻传播图作为用户的外生社会情境。提出一种端到端的假新闻检测框架UPFD,融合社交媒体上的内生信息和外生信息,预测新闻在社交媒体上的可信度。实验结果验证了该方法在建模用户内生偏好方面的优越性。
五、思考
此文证明了用户偏好信息的重要性,但采用的方式还是比较简单粗糙,处理的粒度太粗,信息融合的策略通过concat比较简单,融合效果可能会大大降低。