🌮开发平台:jupyter lab
🍖运行环境:python3、TensorFlow2.x
----------------------------------------------- 2022.9.16 测验成功 ----------------------------------------------------------------
1. 时间序列预测:用电量预测 01 数据分析与建模
2. 时间序列预测:用电量预测 02 KNN(K邻近算法)
3. 时间序列预测:用电量预测 03 Linear(多元线性回归算法 & 数据未标准化)
4.时间序列预测:用电量预测 04 Std_Linear(多元线性回归算法 & 数据标准化)
5. 时间序列预测:用电量预测 05 BP神经网络
6.时间序列预测:用电量预测 06 长短期记忆网络LSTM
7. 时间序列预测:用电量预测 07 灰色预测算法
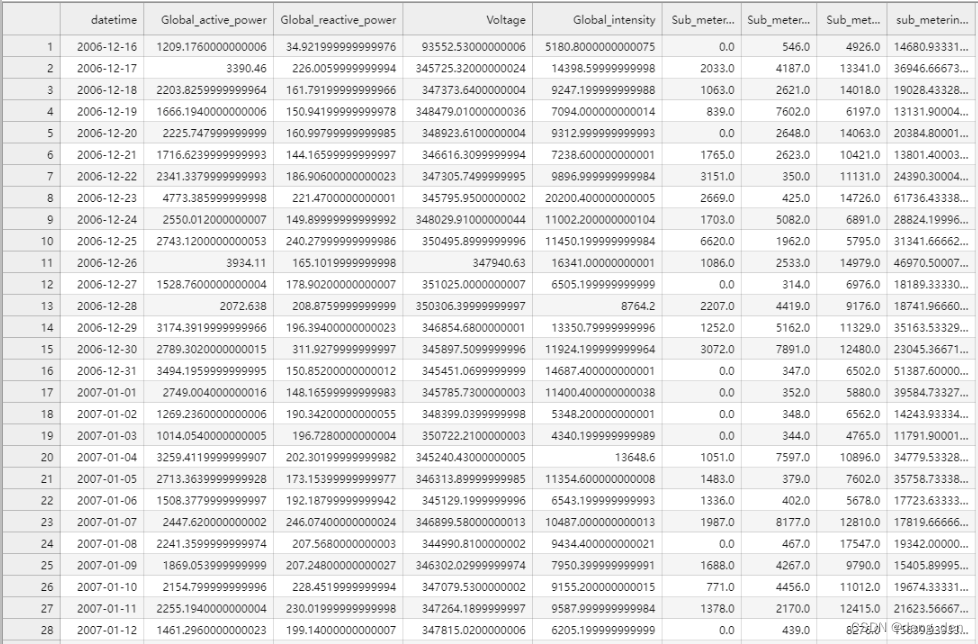
说明:根据上述列表中 1.时间序列预测:用电量预测 01 数据分析与建模 进行数据整理,得到household_power_consumption_days.csv文件,部分数据展示如下:
用电量预测 03 Linear(多元线性回归算法 & 数据未标准化)
1.导包
### 线性回归
## 测试数据:该表格的末200条
## 注意:未对数据进行标准化,该算法采用前四列为参数列,末列为标签
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
2. 拆分数据集和训练集
### 2.1 将日期变作index
dataset = pd.read_csv('../household_power_consumption_days.csv',engine='python',encoding='utf8',index_col=['datetime'])
dataset.tail(15)
### 2.2 关键字
dataset.keys()
## Index(['Global_active_power','Global_reactive_power', 'Voltage','Global_intensity', 'Sub_metering_1', 'Sub_metering_2','Sub_metering_3', 'sub_metering_4'],dtype='object')
### 2.3 定义自变量和因变量
## 定义自变量
data_train = dataset.iloc[:,:-4]
data_label = dataset.iloc[:,-1]
data_train.shape,data_label.shape ## ((1442, 4), (1442,))
### 2.4 划分训练集和测试集
x_train,x_test = data_train[:-200],data_train[-200:]
y_train,y_test = data_label[:-200],data_label[-200:]
3.构建模型,进行测试集数据预测
from sklearn.linear_model import LinearRegression
lrModel = LinearRegression()
lrModel.fit(x_train,y_train)
# out: LinearRegression()
## 预测测试集数据
y_test_predict = lrModel.predict(x_test)
y_test_predict
# out: array([13649.03353361, 17831.09325286, 13378.99489899, ...,13256.21736225, 13437.9122577])

4.数据展示
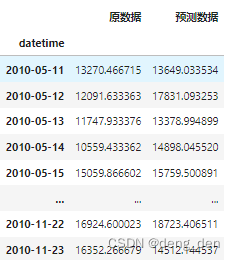
4.1 以表格形式对比测试集原始目标数据和预测目标数据
## 将array列合并成df表格
compare = pd.DataFrame({
"原数据":y_test,
"预测数据":y_test_predict
})
compare
## 注意:直接df形式合成,会自带原index,若是array,则index为常规序号值
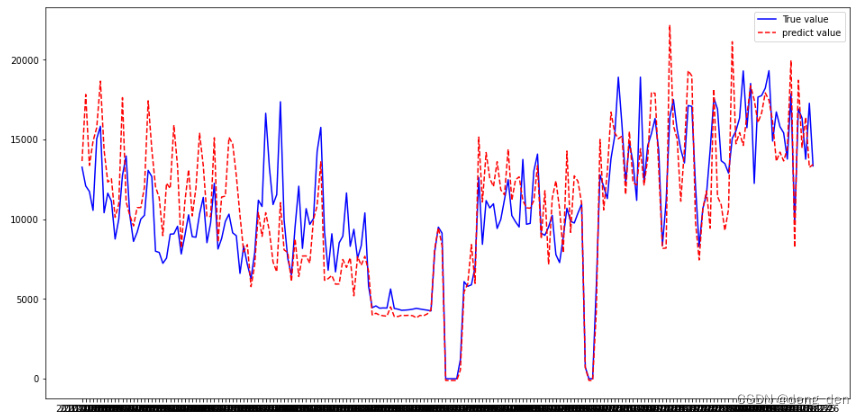
4.2 以可视化图的形式对比测试集原始目标数据和预测目标数据
import matplotlib.pyplot as plt
# 绘制 预测与真值结果
plt.figure(figsize=(16,8))
plt.plot(y_test, 'b-',label="True value")
plt.plot(y_test_predict, 'r--',label="predict value")
plt.legend(loc='best')
plt.show()
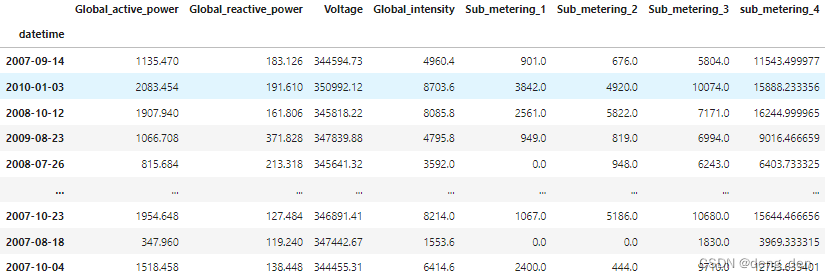
4.3 随机获取数据并进行预测
## 随机抽样测试
# 随机抽取100个测试数据
random_test = dataset.sample(n=100)
random_test
# 获取前4列为参数值
random_train = random_test.iloc[:,:-4]
# 获取末位列为标签列
random_test = random_test.iloc[:,-1]
### 利用上面所声明的模型进行预测
random_train_predict = lrModel.predict(random_train)
random_train_predict
# out: array([9596.74924641, 17674.73014976,...,7920.61580275])
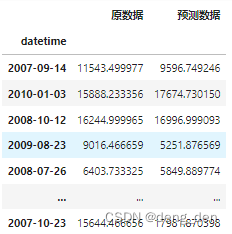
## 以表格形式展现
random_compare = pd.DataFrame({
"原数据":random_test,
"预测数据":random_train_predict
})
random_compare
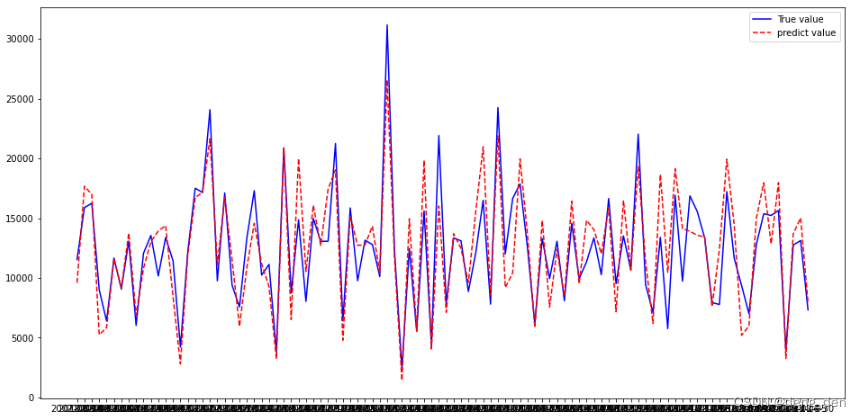
# 绘制 预测与真值结果
plt.figure(figsize=(16,8))
plt.plot(random_test, 'b-',label="True value")
plt.plot(random_train_predict, 'r--',label="predict value")
plt.legend(loc='best')
plt.show()
本文含有隐藏内容,请 开通VIP 后查看