目录
一.数据库
1.数据库相关概念
数据库:存储特定格式数据的仓库。
数据库管理系统:用来管理数据库当中的数据的主要是增删改查方面的。
Sql语句:用来实现增删改查操作的语句命令
2.安装mysql数据库
推荐一款软件吧,现在很多操作用软件会更加的方便,学mysql主要是学习一些操作语句和概念
二.数据库的基本操作
1.数据库的常用命令
退出mysql
mysql> exit;show databases:查询数据库当中的有哪些数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+mysql自带了四个数据库
使用数据库
mysql> use sys
Database changed创建一个名为bjpowernode数据库
mysql> create database bjpowernode;
Query OK, 1 row affected (0.01 sec)注意:mysql是不见“;”不执行,“;”表示终止一条语句! 并且SQL语句是不严格要求大小写的
小技巧:
当出现下面的情况的时候
mysql> wq ih
->
->
->加个\c就退出去了
mysql> wq ih
->
->
-> \c
mysql>2.表的理解
字段与数据
数据库当中最基本的单元就是表,表当中存放到的是数据的信息,表由行和列组成,行被称为数据/记录 列被称为字段
字段是有规定的,规定者这一列数据的存储规范,例如:性别列只能写男女。
每一个字段都有约束,字段名,数据类型等规范
约束:其中有一个叫做唯一性约束,约束之后就列当中的数据就不能重复了
展示数据库当中的表
mysql> show tables;3.Sql的分类
数据查询语言DQL:带有select关键字的语句。。。
数据操作语言DML:比如基础的增删改,insert增减 delete删除 update修改
数据定义语言DDL:DDL主要是表的结构不是数据的数据,增create删drop该updae改alter
事务控制语言TCL:事务提交commit,事务回滚rollback
数据控制语言DCL:授权grdant撤销权限revoke
4.导入数据文件
注意:路径当中不要有中文,路径是你创建bjpowernode表的路径
mysql> source D:\course\03-MySQL\document\bjpowernode.sql
三.对数据进行查询
条件查询到的关键字是where
1.查询
select 指定字段 from 指定表格 where 筛选的条件;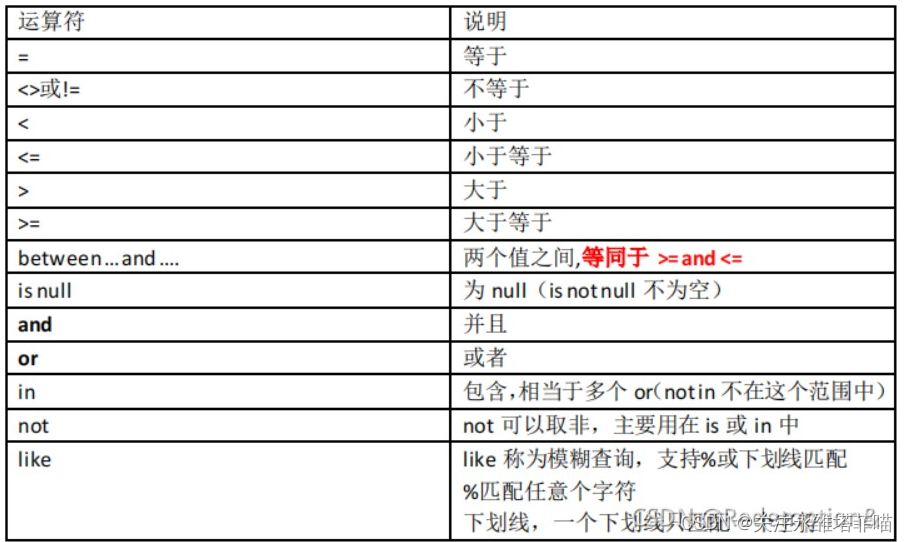
查询薪资在2450和3000之间的员工信息,包括2450和3000
select empno,ename,sal from emp where sal >= 2450 and sal <= 3000;可以指定多个字段,然后对其中一个或者多个进行筛选。
比如筛选条件
sal >= 2450 and sal <= 3000别名问题
select deptno,dname as deptname from dept; 注意:只是将显示的查询结果列名显示为deptname,原表列名还是叫:dname
记住:select语句是永远都不会进行修改操作的。(因为只负责查询
字段可以使用数学表达式(输出sal结果的值*12倍)
select ename,sal*12 from emp;找出名字中有“_”的数据
需要用到转义字符\
select name from t_student where name like '%\_%';一些关键字的注意事项:
null:在数据库当中null不能使用等号进行衡量。需要使用is null,因为数据库中的null代表什么也没有,它不是一个值,所以不能使用等号衡量。
in:in不是一个区间,in后面跟的是具体的值。
and和or的优先级:and和or同时出现,and优先级较高。如果想让or先执行,需要加“小括号”
以后在开发中,如果不确定优先级,就加小括号就行了。
找出工资大于2500并且部门编号为10的员工,或者20部门所有员工找出来。
select *from emp where sal > 2500 and (deptno = 10 or deptno = 20);
2.排序
排序的关键字是oder by
默认的是升序排序(工资由小到大)
select ename,sal from emp order by sal; 手动指定 加上desc为降序
order by sal descasc为升序
order by sal asc;多个字段排序的优先级问题
多个字段排序,优先级。
select ename,sal from emporder by sal asc, ename asc; // sal在前字段,起主导,只有sal相等的时候,才会考虑启用ename排序。查询时候如果是字符串的化,应当用英文' '标起来
查询SMIT的编号和薪资
select empno,sal from emp where ename = 'SMITH'; //字符串使用单引号注意:字母的顺序是按照Ascll排序的,数字,是按照数字大小排序的
3.应用案例
找出工资在1250到3000之间的员工信息,要求按照薪资降序排列。
select ename,sal from emp where sal between 1250 and 3000 rder by sal desc;查询与排序的顺序 :
书写顺序:select.....from.....where.....oder by.....
执行循序:from where select oder by 排序总是在最后面
四.数据处理函数
1.单行处理函数
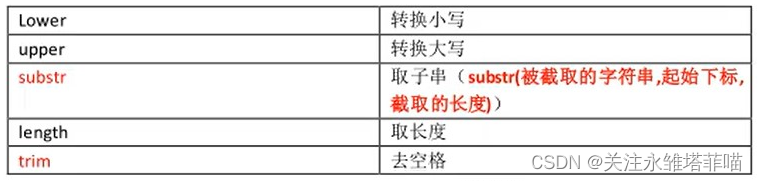
 如何使用处理函数
如何使用处理函数
将字段ename的所有字母小写
select lower(ename) as ename from emp;用法:函数名(要处理的字段名)
一个输入对应一个输出。
+--------+
| ename |
+--------+
| smith |
| allen |
| ward |
| jones |
| martin |
| blake |
| clark |
| scott |
| king |
| turner |
| adams |
| james |
| ford |
| miller |
+--------+
substr( 被截取的字符串, 起始下标,截取的长度)
select substr(ename, 1, 1) as ename from emp; 注意:起始下标从1开始,没有0。
找出员工名字第一个字母是A的员工信息
模糊查询
select ename from emp where ename like 'A%';
使用函数
select ename from emp where substr(ename,1,1) = ‘A’;concat函数进行字符串的拼接
select concat(empno,ename) from emp;将两个字段拼接成一个字段,默认名称为 concat(empno,ename)可以使用as创建别名
select concat(empno,ename) as noaddname from emp;length获取字符长度
select length(ename) as enamelength from emp;trim 会去首尾空格,不会去除中间的空格
没有除去空格自之前,搜索不到任何的信息
mysql> select * from emp where ename = ' KING';
Empty set (0.00 sec)除去空格之后获取到数据
mysql> select * from emp where ename = trim(' KING');
+-------+-------+-----------+------+------------+---------+------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+-------+-----------+------+------------+---------+------+--------+
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
+-------+-------+-----------+------+------------+---------+------+--------+
str_to_date 将字符串转换成日期
有两个参数,第一个参数为字符串,第二个参数为要转化的日期格式
查询 1981-02-20 入职的员工
第一种方法,直接字符串查询
select * from emp where HIREDATE='1981-02-20';
第二种方法,把字符串变成日期进行查询
第一种日期表达方式
select * from emp where HIREDATE=str_to_date('1981-02-20','%Y-%m-%d');
第二种种日期表达方式
select * from emp where HIREDATE=str_to_date('02-20-1981','%m-%d-%Y');
date_format 格式化日期
第一个 参数是合法的日期。第二个参数 规定日期/时间的输出格式。
将hiredata当中的数据以指定的格式输出
select empno, ename, date_format(hiredate, '%Y-%m-%d %H:%i:%s') as hiredate from emp;
now() 获得当前时间
select date_format(now(),'%Y-%m-%d %H %i %s');
日期格式的说明
%Y:代表 4 位的年份
%y:代表 2 位的年份
%m:代表月, 格式为(01……12)
%c:代表月, 格式为(1……12)
%H:代表小时,格式为(00……23)
%h: 代表小时,格式为(01……12)
%i: 代表分钟, 格式为(00……59)
%r:代表 时间,格式为 12 小时(hh:mm:ss [AP]M)
%T:代表 时间,格式为 24 小时(hh:mm:ss)
%S:代表 秒,格式为(00……59)
%s:代表秒,格式为(00……59)
日期函数详细解释![]() https://www.w3school.com.cn/sql/func_date_format.asp
https://www.w3school.com.cn/sql/func_date_format.asp
format 一般是用来格式化的
select empno, ename, Format(sal, 0) from emp;
将所有的工资数据变成0进行输出,当然,只改变输出的格式,不改变真实的数据库数据
case…when…then…when…then…else…end (else正常的字段)
当员工的工作岗位是MANAGER的时候,工资上调10%,当工作岗位是SALESMAN的时候,工资上调50%,其它正常
select job,sal as oldsal,
(case job when 'MANAGER' then sal*1.1 when 'SALESMAN' then sal*1.5 else sal end) as newsal
from emp;
round 函数用于把数值字段舍入为指定的小数位数
SELECT ProductName, ROUND(UnitPrice,0) as UnitPrice FROM Products将UnitPrice当中的数据以整数的形式进行输出
select round(1236.567, 2) as result from emp; //保留2个小数
select round(1236.567, -1) as result from emp; // 保留到十位。 select 字面量/字面值 from 表名;
数据库当中有多少条数据就会生成多少字面值,然后打印显示
rand() 生成随机数范围是0-1之间
输出0-100之间的随机数
mysql> select round(rand()*100,0) from emp; // 100以内的随机数ifnull可以将 null 转换成一个具体值
所有null参与的数学运算最终结果都为null
mysql> select ename, sal + comm as salcomm from emp;sal或comm当中有一个为null的话,相加结果就为空
年薪 = (月薪 + 月补助) * 12
select ename, (sal + ifnull(comm,0)) * 12 as yearsal from emp;2.多行处理函数(分组函数)
多个输入对应一个输出。用来筛选数据,求特殊值(最大值/最小值)
五个:
- count 计数
- sum 求和
- avg 平均值
- max 最大值
- min 最小值
注意:在函数使用之前必须先进行分组,不进行分组整张表被认为是一组函数,一个字段为一组。
找出最高工资?
mysql> select max(sal) from emp;找出最低工资?
mysql> select min(sal) from emp;计算工资和:
mysql> select sum(sal) from emp;计算平均工资:
mysql> select avg(sal) from emp;计算员工数量?
mysql> select sum(enname) from emp;注意:分组函数自动忽略NULL,你不需要提前对NULL进行处理,如果想计算null值
mysql> select count(*) from emp;count(*)不会忽略null值。
count(*):统计表当中的总行数。(只要有一行数据count则++
分组函数不能直接使用在where子句当中
运行下面的代码会报错
select ename,sal from emp where sal > min(sal);
所有的分组函数可以组合起来一起用。
select sum(sal),min(sal),max(sal),avg(sal),count(*) from emp;五.分组查询(非常重要)
会将代码的执行顺序,计算机语言当中代码的执行顺序是十分重要的
1.实际的需求
在实际的应用中,可能有这样的需求,需要先进行分组,然后对每一组的数据进行操作。
这个时候我们需要使用分组查询,怎么进行分组查询呢?
select
…
from
…
group by
…
计算每个部门的工资和?
计算每个工作岗位的平均薪资?
找出每个工作岗位的最高薪资?
…
2.分组查询的执行和书写顺序
书写顺序
select
…
from
…
where
…
group by
…
order by
…
执行顺序
- from
where
- group by
- select
- order by
注意:先进行分组,分组之后再查询
重点:由于执行顺序的关系,分组函数不能在where后面。因为where在执行他后面的条件语句的时候,分组还没有执行,冲突了。因为select在group by之后执行,所以select后面可以使用分组函数
3.用分组来实现需求
找出每个岗位的工资和
根据岗位进行分组,再使用分组函数进行求和
select job,sum(sal) from emp group by job;以上这个语句的执行顺序?
先从emp表中查询数据。
根据job字段进行分组。
然后对每一组的数据进行sum(sal)
毫无意义的查询输出代码
select ename,job,sum(sal) from emp group by job;MYSQL语法通过,但是没有这种需求
以上语句在oracle中执行报错。 oracle的语法比mysql的语法严格。(mysql的语法相对来说松散一些!)
重点结论: 在一条select语句当中,如果有group by语句的话,select后面只能跟:参加分组的字段,以及分组函数(5个)。其它的一律不能跟。
找出每个部门的最该薪资
按照部门编号分组,求每一组的最大值。
select后面添加ename字段没有意义,另外oracle会报错。
mysql> select ename,deptno,max(sal) from emp group by deptno;但是我认为还是有可能有这种需求的,比如需求:每个部门工资最高的人是谁
正确答案
mysql> select deptno,max(sal) from emp group by deptno;每个部门,不同岗位里边的最高薪资(其实是每个岗位,每个部门)
技巧:两个字段联合成1个字段看。
select deptno, job, max(sal) from emp group by deptno, job;找出每个部门最高薪资,要求显示最高薪资大于3000的
第一步:找出每个部门最高薪资
select deptno,max(sal) from emp group by deptno;第二步:要求显示最高薪资大于3000
select deptno,max(sal) from emp group by deptno having max(sal) > 3000;where先筛选后分组,having先分组在筛选,having不能单独使用,having不能代替where单独使用,having必须和group by联合使用。
执行效率比较低
select deptno,max(sal) from emp where sal > 3000 group by deptno;优化策略:where和having,优先选择where,where实在完成不了了,再选择having。
没有办法使用where进行优化
找出每个部门平均薪资,要求显示平均薪资高于2500的。
第一步:找出每个部门平均薪资
select deptno,avg(sal) from emp group by deptno; 第二步:要求显示平均薪资高于2500的
select deptno,avg(sal) from emp group by deptno having avg(sal) > 2500;六.最后总结
1.书写顺序与执行顺序
书写顺序
select … from … where … group by … having (就是为了过滤分组后的数据而存在的—不可以单独的出现)…order by…
执行顺序
from
where 过滤原始数据
group by 进行分组
having 对分组数据进行过滤
select 选出数据
order by 排序输出
如何使用:从某张表中查询数据,先经过where条件筛选出有价值的数据。对这些有价值的数据进行分组。分组之后可以使用having继续筛选。select查询出来。最后排序输出!
having和where使用原则:能在 where 中过滤的数据,尽量在 where 中过滤,效率较高。having 的过滤是专门对分组之后的数据进行过滤的。
找出每个岗位的平均薪资,要求显示平均薪资大于1500的,除MANAGER岗位之外,要求按照平均薪资降序排
select job, avg(sal) as avgsal from emp where job <> 'MANAGER' group by job having avg(sal) > 1500 order by avgsal desc;order by为什么可以使用avgsal?是因为先执行select后执行order by。
逗号的使用:字段与字段之间,调用函数当中的值
2.引出视图
假设有一条非常复杂的SQL语句,而这条SQL语句需要在不同的位置上反复使用。
每一次使用这个sql语句的时候都需要重新编写,很长,很麻烦,怎么办?
可以把这条复杂的SQL语句以视图对象的形式新建。
在需要编写这条SQL语句的位置直接使用视图对象,可以大大简化开发。
并且利于后期的维护,因为修改的时候也只需要修改一个位置就行,只需要修改视图对象所映射的SQL语句。
我们以后面向视图开发的时候,使用视图的时候可以像使用table一样。
可以对视图进行增删改查等操作。视图不是在内存当中,视图对象也是存储在硬盘上的,不会消失。
再提醒一下:
视图对应的语句只能是DQL查询语句。
但是视图对象创建完成之后,可以对视图进行增删改查等操作。
3.小知识点
增删改查,又叫做:CRUD。
CRUD是在公司中程序员之间沟通的术语。一般我们很少说增删改查。
一般都说CRUD。
C:Create(增)
R:Retrive(查:检索)
U:Update(改)
D:Delete(删)