之前使用过XPath爬虫、正则表达式爬虫获取我们想要的内容,Beautiful Soup也是一种爬虫,解析HTML/XML文档,但是使用方法会比之前的简单。
首先还是安装库,这里安装的是 bs4 ,Beautiful Soup类就在这个模块里面。
目录
标签获取
首先看一看类方法获取到的文本样式:
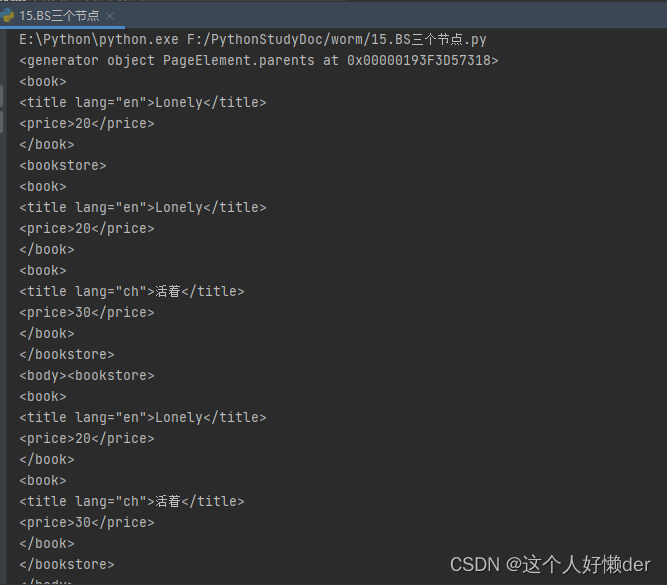
from bs4 import BeautifulSoup text = ''' <?xml version="1.0" encoding="utf-8"?> <bookstore> <book> <title lang="en">Lonely</title> <price>20</price> </book> <book> <title lang="ch">活着</title> <price>30</price> </book> </bookstore> ''' soup=BeautifulSoup(text) #创建一个BeautifulSoup对象 print(soup.prettify()) #按照缩进格式进行输出
将获得的文本使用类方法进行输出,便于直观的看到里面的内容以及从属关系。
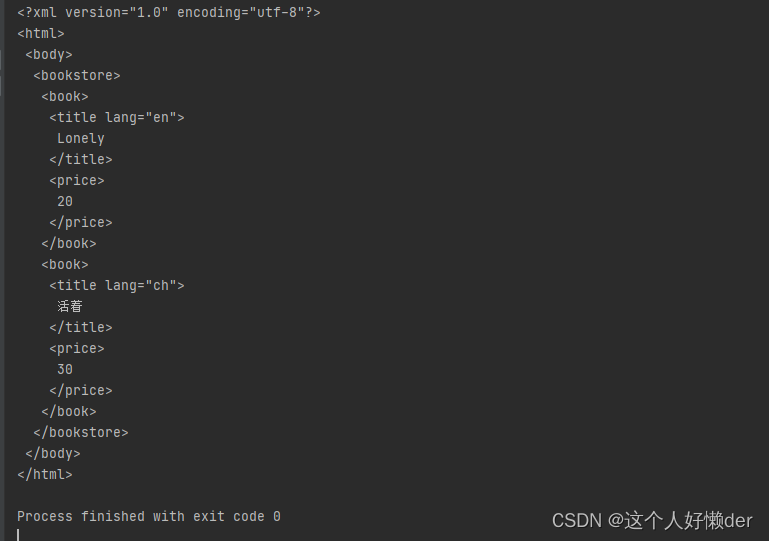
获取XML文档中的文本内容:
print(soup.getText()) #获取文本内容

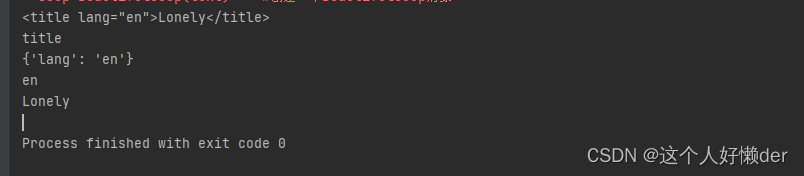
获取文档里面的标签以及各种内容(以title标签举例):
print(soup.title) #获取一个标签 print(soup.title.name) #获取标签名字 print(soup.title.attrs) #获取标签属性,返回值是字典 print(soup.title['lang']) #获取属性的值 print(soup.title.string) #获取标签里的文本
在运行的结果中会提示你一些关于编译器的警告,可以忽略不计。
find( )与find_all( )函数
find('name')函数:查询里面的一个标签,有多个也只返回一个。
find_all('name')函数:查询所有这个标签名的标签。
还是上面的text:
print(soup.find_all('title')) #查询所有title标签 print(soup.find_all('title')[0]) #查询所有title标签的第一个(从0开始的)

根据属性查找标签,有两种方法,一种表达式,一种字典形式:
print(soup.find_all('title',lang='ch')) #查询指定title标签,属性相同可以查询到多个 print(soup.find_all('title',{'lang':'ch'})) #字典形式

查询多个标签时一次查询,然后放在列表里:
print(soup.find_all(['title','price']) ) #多个标签中的第一个的文本
获取这个列表中的文本:
print(soup.find_all(['title','price'])[0].get_text()) #多个标签中的第一个的文本


三个常见节点
子节点、父节点、兄弟节点。
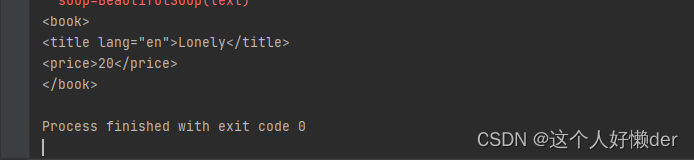
查询里面的一个节点:
print(soup.book)
book节点以及里面的子节点都被找到。

contents节点:查询某个节点里面的子节点:
print(soup.book.contents)
可以看到子节点放在了列表中,包括了换行符,选取里面的内容使用.contents[num]即可。

childdren生成器:使用该方法后可以对其进行遍历。
for child in soup.children: print(child)
一级一级的输出,最后获得全部内容。
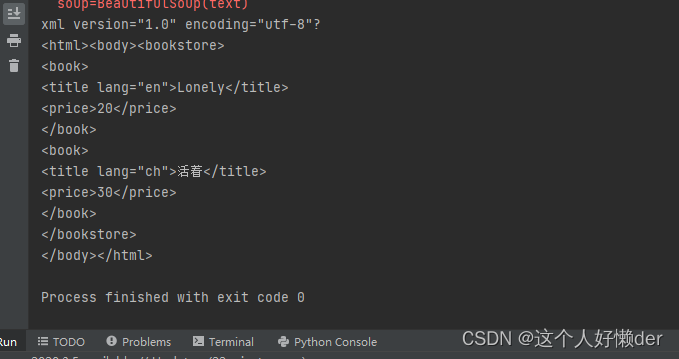
parent节点:查找某个节点的父节点
print(soup.title.parent)
将父节点以及里面的子节点都会显示出来。
parents节点:查询某个节点的父节点,然后查询父节点的父节点,依次向上知道查询完所有内容,parents方法输出的是生成器,调用里面的内容要进行遍历:
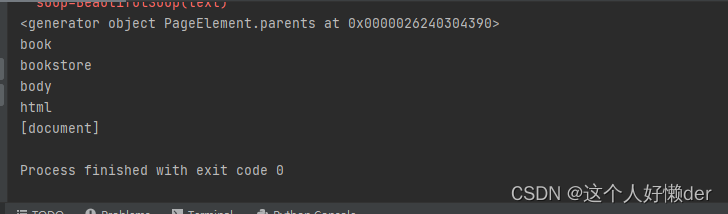
print(soup.title.parents) for i in soup.title.parents: print(i)
查看节点的名字:
print(i.name)
从节点名字可以看出关系是层层递进,依次向上寻找。
兄弟节点:从contents可以查找到某个节点的子节点,这些子节点之间就是兄弟节点,一般的节点上一个或者写一个兄弟节点都是换行符。
print(soup.title.next_sibling) #获取下一个兄弟节点 print(soup.title.previous_sibling) #获取上一个兄弟节点获取所有节点得到的是一个生成器,获取里面的内容要进行遍历:
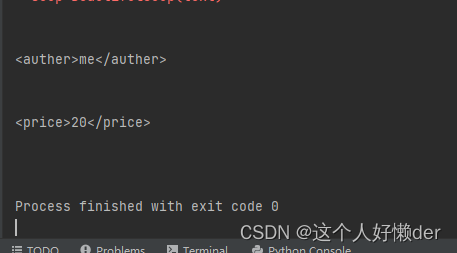
for i in soup.title.next_siblings: #获取所有的兄弟节点 print(i)
看到title中的所有兄弟节点都被获取(为了看到结果加入了一个<auther>标签作为兄弟节点),每两个之间几乎都会有换行符。
BeautifulSoup爬虫
使用BeautifulSoup爬虫获取网上的招聘信息:
 查看网页源代码可以看到职位信息放在<span>标签里,使用class属性就可以找到。
查看网页源代码可以看到职位信息放在<span>标签里,使用class属性就可以找到。
from bs4 import BeautifulSoup
import requests
url='http://www.nowcoder.com/jobs/intern/center'
res=requests.get(url)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser') #创建soup对象
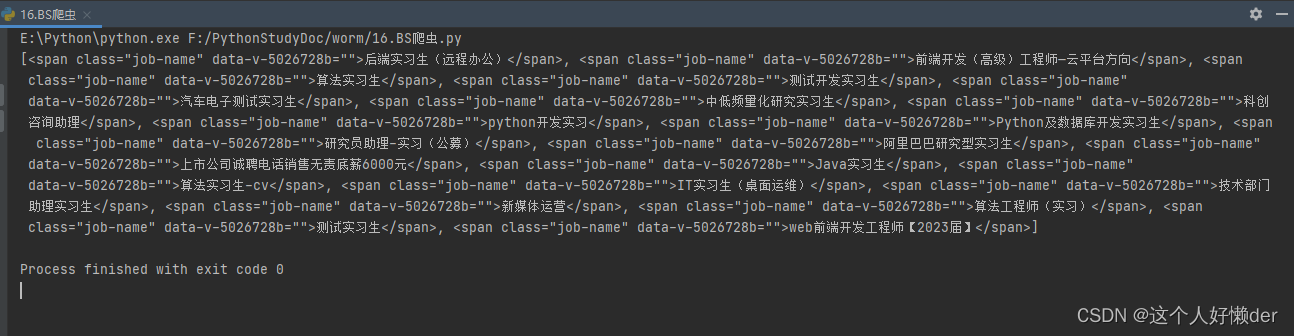
job_name=soup.find_all('span',class_="job-name") #class属性作为关键字,添加下划线使用
print(job_name)
获取的所有span1标签都放在列表里,现在获取里面的文本,将文本再放在列表里:
JobName=[] #创建一个获取的文本列表
for i in range(len(job_name)):
JobName.append(job_name[i].get_text())
print(JobName)
同理可以获取里面别的信息,那么将获取的信息使用pandas模块放入二维数组里,导出为一个表格:
from bs4 import BeautifulSoup
import requests
from pandas import DataFrame
import pandas as pd
JobName = [] # 创建一个获取的文本列表
JobCompany = []
JobSalary = []
url='http://www.nowcoder.com/jobs/intern/center'
res = requests.get(url)
res.encoding = 'utf-8'
print(res)
soup = BeautifulSoup(res.text, 'html.parser') # 创建soup对象
job_name = soup.find_all('span', class_="job-name") # class属性作为关键字,添加下划线使用
job_company = soup.find_all('div', class_="company-name") # 获取公司名
job_salary = soup.find_all('span', class_="job-salary tw-flex-shrink-0") # 获取薪资
for i in range(len(job_name)):
JobName.append(job_name[i].get_text()) # 选择文本添加进列表中,这样就有一个纯文本列表
JobCompany.append(job_company[i].get_text())
JobSalary.append(job_salary[i].get_text())
job = DataFrame([JobName, JobCompany, JobSalary], index=['工作', '公司', '工资']).T #数据放入表格
job.to_csv('niuke.csv') #导出csv文件
