import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.preprocessing import image_dataset_from_directory
"""
下载并解压缩包含图像的 zip 文件,
然后使用tf.keras.preprocessing.image_dataset_from_directory 效用函数
创建一个 tf.data.Dataset 进行训练和验证。
"""
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
validation_dataset = image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
#使用缓冲预提取从磁盘加载图像,以免造成 I/O 阻塞
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
"""
当您没有较大的图像数据集时,最好将随机但现实的转换应用于训练图像(例如旋转或水平翻转,
来人为引入样本多样性。这有助于使模型暴露于训练数据的不同方面并减少过拟合
"""
data_augmentation = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'),
tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),
])
#重新缩放像素值
rescale = tf.keras.layers.experimental.preprocessing.Rescaling(1./127.5, offset= -1)
#创建卷积网络模型
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = rescale(x)
x = layers.Conv2D(16, 3, padding='same', activation='relu')(x)
x = layers.MaxPooling2D()(x)
x = layers.Conv2D(32, 3, padding='same', activation='relu')(x)
x = layers.MaxPooling2D()(x)
x = layers.Conv2D(64, 3, padding='same', activation='relu')(x)
x = layers.MaxPooling2D()(x)
x = layers.Flatten()(x)
x = layers.Dense(128, activation='relu')(x)
outputs = layers.Dense(2)(x)
model = tf.keras.Model(inputs, outputs)
model.summary()
#在训练模型前,需要先编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
#经过 10 个周期的训练后,您应该在验证集上看到约 72% 的准确率
history = model.fit(train_dataset, epochs=10,
validation_data=validation_dataset)
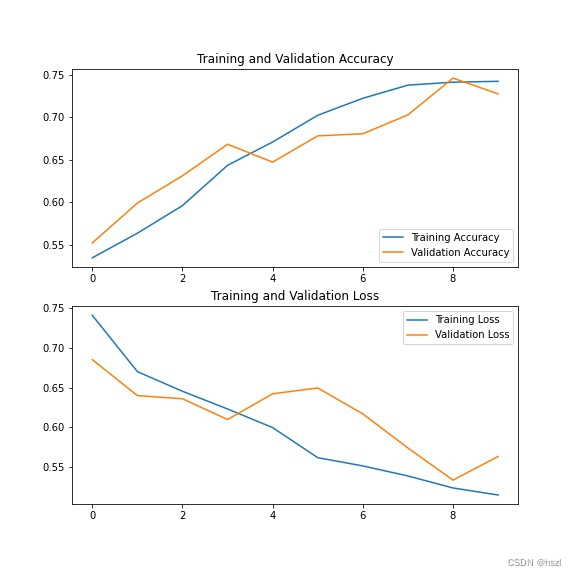
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(10)
%config InlineBackend.figure_format = 'retina'
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
rescaling (Rescaling) (None, 160, 160, 3) 0
conv2d_3 (Conv2D) (None, 160, 160, 16) 448
max_pooling2d_3 (MaxPooling (None, 80, 80, 16) 0
2D)
conv2d_4 (Conv2D) (None, 80, 80, 32) 4640
max_pooling2d_4 (MaxPooling (None, 40, 40, 32) 0
2D)
conv2d_5 (Conv2D) (None, 40, 40, 64) 18496
max_pooling2d_5 (MaxPooling (None, 20, 20, 64) 0
2D)
flatten_1 (Flatten) (None, 25600) 0
dense_2 (Dense) (None, 128) 3276928
dense_3 (Dense) (None, 2) 258
=================================================================
Total params: 3,300,770
Trainable params: 3,300,770
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10 63/63 [==============================] - 21s 321ms/step - loss: 0.7412 - accuracy: 0.5345 - val_loss: 0.6853 - val_accuracy: 0.5520 Epoch 2/10 63/63 [==============================] - 21s 332ms/step - loss: 0.6702 - accuracy: 0.5635 - val_loss: 0.6400 - val_accuracy: 0.5990 Epoch 3/10 63/63 [==============================] - 22s 355ms/step - loss: 0.6454 - accuracy: 0.5960 - val_loss: 0.6359 - val_accuracy: 0.6312 Epoch 4/10 63/63 [==============================] - 24s 373ms/step - loss: 0.6231 - accuracy: 0.6435 - val_loss: 0.6098 - val_accuracy: 0.6683 Epoch 5/10 63/63 [==============================] - 24s 384ms/step - loss: 0.5996 - accuracy: 0.6710 - val_loss: 0.6422 - val_accuracy: 0.6473 Epoch 6/10 63/63 [==============================] - 24s 374ms/step - loss: 0.5617 - accuracy: 0.7025 - val_loss: 0.6496 - val_accuracy: 0.6782 Epoch 7/10 63/63 [==============================] - 25s 390ms/step - loss: 0.5513 - accuracy: 0.7225 - val_loss: 0.6169 - val_accuracy: 0.6807 Epoch 8/10 63/63 [==============================] - 26s 411ms/step - loss: 0.5386 - accuracy: 0.7380 - val_loss: 0.5739 - val_accuracy: 0.7030 Epoch 9/10 63/63 [==============================] - 27s 420ms/step - loss: 0.5235 - accuracy: 0.7415 - val_loss: 0.5334 - val_accuracy: 0.7463 Epoch 10/10 63/63 [==============================] - 25s 403ms/step - loss: 0.5146 - accuracy: 0.7425 - val_loss: 0.5632 - val_accuracy: 0.7277
本文含有隐藏内容,请 开通VIP 后查看