引言
对于一个特定的领域而言,我们可能需要其相关的一些词语,这些词语可以用来进行分词、关键词提取、主题分析等。那么,如何去获得这些词语呢?本文接下来将通过斗破苍穹小说来介绍新词发现。
前言知识
词频:词频就是一个词语在语料库中出现的次数,词频越大,表明以下三个参数出现的置信度越大。
凝聚系数:表示两个单词同时出现的可能度,具体计算公式如下:
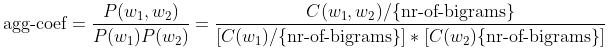
其中, C ( w 1 , w 2 ) C(w_1, w_2) C(w1,w2)表示 w 1 w_{1} w1后面的词语是 w 2 w_{2} w2的次数, C ( w 1 ) C(w_{1}) C(w1)和 C ( w 2 ) C(w_{2}) C(w2)是词 w 1 w_{1} w1和 w 2 w_{2} w2分别出现的次数。最小边界信息熵。
最大边界信息熵。
最小和最大边界信息熵分别是左边界信息熵和右边界信息熵二者的最小值和最大值。
左边界信息熵计算公式如下:
E n t w l = − ∑ w l P ( w l ∣ w ) ⋅ log ( P ( w l ∣ w ) ) Ent_{w_l}=-\sum_{w_l}P(w_l|w)\cdot\log(P(w_l|w)) Entwl=−∑wlP(wl∣w)⋅log(P(wl∣w))
其中 w l w_{l} wl是出现在w左边的所有unigram组成的集合,上面的公式同样适用于右边界信息熵的计算。
边界信息熵越大,表明一个词越能和更多词搭配,进而表明一个词是一个独立词。比如"我是"拥有大词频和大凝聚系数但是最小边界信息熵却很小,说明它不是一个词。举个例子:
考虑这么一句话"吃葡萄不吐葡萄皮不吃葡萄倒吐葡萄皮","葡萄"一词出现了四次,其中左邻字分别为 {吃, 吐, 吃, 吐} ,右邻字分别为 {不, 皮, 倒, 皮} .
根据公式,"葡萄"一词的左邻字的信息熵为:
− ( 1 / 2 ) ⋅ l o g ( 1 / 2 ) − ( 1 / 2 ) ⋅ l o g ( 1 / 2 ) ≈ 0.693 - (1/2) · log(1/2) - (1/2) · log(1/2) ≈ 0.693 −(1/2)⋅log(1/2)−(1/2)⋅log(1/2)≈0.693
它的右邻字的信息熵则为:
− ( 1 / 2 ) ⋅ l o g ( 1 / 2 ) − ( 1 / 4 ) ⋅ l o g ( 1 / 4 ) − ( 1 / 4 ) ⋅ l o g ( 1 / 4 ) ≈ 1.04 - (1/2) · log(1/2) - (1/4) · log(1/4) - \ (1/4) · log(1/4) ≈ 1.04 −(1/2)⋅log(1/2)−(1/4)⋅log(1/4)− (1/4)⋅log(1/4)≈1.04
可见,在这个句子中,"葡萄"一词的右邻字更加丰富一些。
实操
代码地址:https://github.com/taishan1994/dpcq_new_word_find
1、拷贝项目。
2、在data下新建一个文件夹,文件名可以任取,最好是和自己数据集相关的名字,这里是斗破苍穹。
3、在discover.py里面新建一个函数,用于读取数据,针对于斗破苍穹:
def get_dpcq(): with open('data/斗破苍穹/斗破苍穹.txt', 'r', encoding='utf-8') as fp: data = fp.read().strip() data = data.replace("===", "") data = data.split('\n') # 不要开头的'《斗破苍穹》来自: https://www.txt97.com/book/txt297.html' # 把===替换为空 data = data[1:] res = [] from tqdm import tqdm for d in tqdm(data, ncols=100): if d == "": continue res.append(d.strip()) return res返回的res中每一个元素是一个句子。
在run_discover.py里面导入刚才的函数并加载:
documents = get_dpcq() # 这里返回名为doucuments不能变。 corpus_name = "斗破苍穹"最后运行:
python run_discover.py "data/斗破苍穹/斗破苍穹.txt" "reports" --latin 50 0 0 0 --bigram 20 80 0 1.5 --unigram_2 20 40 0 1 --unigram_3 20 41 0 1 --iteration 2 --verbose 2这里说明一下每一个参数的作用:
- 第一个参数是数据的地址。
- 第二个参数是保存结果的地址。
- latin、bigram、unigram_2、unigram_3后面的四个参数分别是频率、凝聚系数、最小边界熵、最大边界熵。
- 四种类型的新词:
- 拉丁词,包括:纯数字 (2333, 12315, 12306)、纯字母 (iphone, vivo)、数字字母混合 (iphone7, mate9)
- 两个中文字符的unigram (unigrams被定义为分词器产生的元素):(萧炎,异火,紫研)
- 三个中文字符的unigram unigram:(小医仙,云岚宗,斗之气)
- bigrams, 每个bigram由两个unigram组成(灵魂力量,加玛帝国,纳兰嫣然)
结果
最后会在reports下生成以下文件:
以下显示部分的结果:
两个字的:
20.0 # 40.0 # 0.0 # 1.0 # 2 tf agg_coef max_entropy min_entropy left_entropy right_entropy
萧炎 44477 56.90328 8.34041 4.69988 4.69988 8.34041
令得 2154 66.94484 6.15161 4.03623 4.03623 6.15161
异火 2153 57.93440 6.18367 5.47363 6.18367 5.47363
听得 1970 60.18430 6.24338 2.21533 2.21533 6.24338
紫研 1419 701.13603 6.79713 4.91935 4.91935 6.79713
纳兰 1284 741.42784 4.58498 1.47031 4.58498 1.47031
韩枫 953 1315.95708 7.18807 5.08946 5.08946 7.18807
魂殿 897 103.97270 5.73556 5.54795 5.73556 5.54795
斗皇 892 94.79750 5.45420 3.16312 5.45420 3.16312
苏千 842 558.08755 6.47207 4.06888 4.06888 6.47207
药鼎 704 90.21435 5.00712 3.87745 5.00712 3.87745
斗尊 696 43.95327 5.33022 3.23932 5.33022 3.23932
三个字的:
20.0 # 41.0 # 0.0 # 1.0 # 2 tf agg_coef max_entropy min_entropy left_entropy right_entropy
小医仙 1346 173967.58092 6.96497 3.31052 3.31052 6.96497
云岚宗 1340 236637.51952 6.26222 6.15050 6.26222 6.15050
妖凰族 361 132785.11397 4.81515 1.47622 1.47622 4.81515
大斗师 325 2382.22258 5.67791 4.85402 5.67791 4.85402
焚炎谷 260 27615.13220 5.34474 4.38391 5.34474 4.38391
斗之气 256 301.44918 4.83565 4.00525 4.83565 4.00525
莫天行 241 23245.22139 6.26152 4.24955 4.24955 6.26152
乌坦城 219 5169614.68463 4.97398 4.61440 4.97398 4.61440
凤清儿 215 299254.34290 5.53344 4.35765 4.35765 5.53344
自萧炎 141 53.93642 4.29877 3.81674 4.29877 3.81674
慕青鸾 134 1772983.90008 5.51582 3.17790 3.17790 5.51582
天冥宗 132 17017.90161 4.85124 4.71653 4.85124 4.71653
东龙岛 130 262964.66995 5.09240 4.50574 5.09240 4.50574
总体的:
20.0 # 80.0 # 0.0 # 1.5 # 2 tf agg_coef max_entropy min_entropy left_entropy right_entropy
望着 6429 88.62492 5.76639 3.29693 3.29693 5.76639
让得 3282 158.42311 6.05628 5.00367 5.00367 6.05628
薰儿 2655 1075.93292 7.36769 4.51719 4.51719 7.36769
等人 2225 115.64243 6.58301 5.25368 5.25368 6.58301
炼药师 2011 1434.44947 5.70378 5.21238 5.70378 5.21238
盯着 1620 95.54733 5.73287 3.40279 3.40279 5.73287
脸庞上 1601 139.93660 4.99613 4.53856 4.99613 4.53856
天空上 1383 151.95689 4.15316 3.98112 4.15316 3.98112
瞧得 1221 221.02698 6.17956 3.80053 3.80053 6.17956
不知道 1217 136.84007 7.17930 4.82474 4.82474 7.17930
今曰 1162 789.58121 6.29225 3.81237 3.81237 6.29225
略微有些 977 170.57313 7.90198 5.99135 5.99135 7.90198
海波东 964 2441.88382 6.54657 4.26189 4.26189 6.54657
不可能 948 262.75909 6.60016 4.68069 4.68069 6.60016
曰后 927 136.89882 6.12798 3.93988 3.93988 6.12798
灵魂力量 927 351.64736 5.96322 4.66934 4.66934 5.96322
加玛帝国 919 1892.04722 5.86381 5.65998 5.65998 5.86381
纳兰嫣然 881 2016.11251 7.21520 4.36805 4.36805 7.21520
并没有 868 197.49401 7.48791 5.03779 5.03779 7.48791
感觉到 865 243.88611 5.36146 4.61834 4.61834 5.36146
章 846 1917.97647 9.09531 6.75345 6.75345 9.09531
小医仙 844 1443.15544 6.06024 3.63423 3.63423 6.06024\
参考
http://www.matrix67.com/blog/archives/5044
https://github.com/Rayarrow/New-Word-Discovery