线程的基本操作 一
一.线程
1.什么是线程
线程是进程中执行运算的最小单位,是进程中的一个实体,是被系统独立调度和分派的基本单位。线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。
简而言之,线程就是一个"轻量级的进程",但它与进程还是有一点区别的
2.线程与进程的比较
(1).一个进程至少包含一个线程,而线程是在进程内部的,所以一个线程只能对应一个进程,但是进程和线程都可以并发执行;
(2).进程与进程之间的资源是相互独立的,而一个进程中的多个线程,它们的资源是共用这个进程的,要注意的是,线程是不拥有系统资源的,但是它可以去访问隶属于进程的系统资源;
(3).进程是操作系统中资源分配的基本单位,而进程是操作系统中调度执行的基本单位;
(4).多个进程同时执行的时候,一个进程的崩溃一般不会影响到其他进程,而一个线程的崩溃可能会导致这个进程的崩溃,进而导致这个进程内部的其他线程崩溃;
(5)创建或撤销进程时的系统资源开销要明显大于创建或撤销线程时的开销
3.线程代码的初步实现及详解
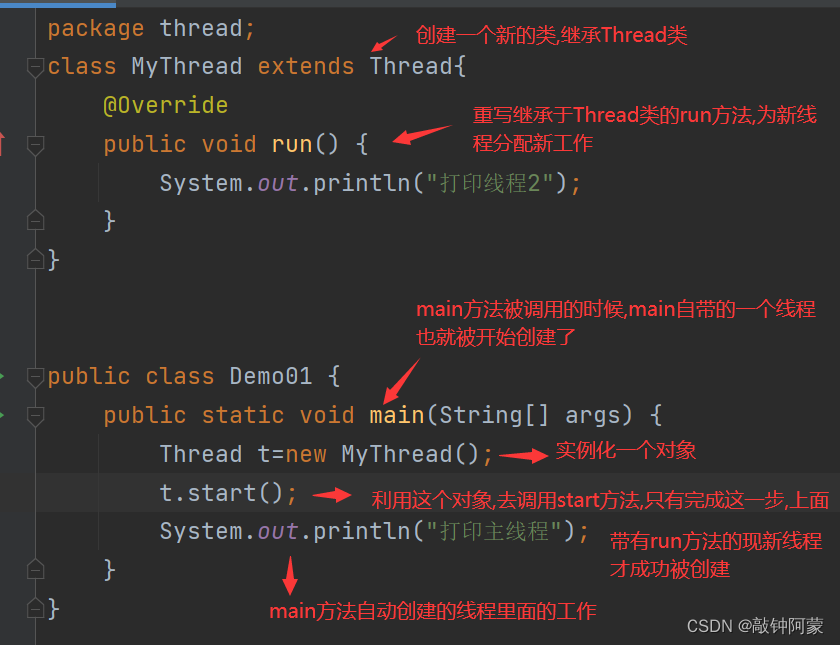
先创建一个类继承于Thread,然后重写run方法,再在主函数内实例化出来一个对象,利用这个对象调用start这个方法,就能简单得创建出一个新线程了
class MyThread extends Thread{
@Override
public void run() {
System.out.println("打印线程2");
}
}
public class Demo01 {
public static void main(String[] args) {
Thread t=new MyThread();
t.start();
System.out.println("打印主线程");
}
}
结果显示为
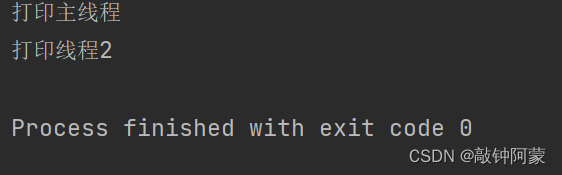
我们都知道,main方法在被创建的时候,系统就自动为main方法创建一个线程,我们暂称它为主线程,而我们利用上述的start方法之后,才能创建出另外的一个新线程,其他的操作是给这个线程准备一些工作,比如,让它打印"打印线程2".
调用start方法的时候,操作系统内核才开始创建线程的PCB,然后让这个PCB加入到系统链表中,参与调度,所以才说,只有完成这一步,才算开始创建线程
start和run的区别:
1.使用start,可以看到两个线程的并发执行,两组交替打印出现;
2.直接调用run,并没有创建新线程,而只是在之前的线程中,执行了run的内容;
3.使用start,是创建了一个新的线程,新的线程里面会调用run,新线程和旧线程之间是并发的关系
4.如何在计算机中看到线程的运行
那main函数能自带创建的线程,真的假的?如何得知?
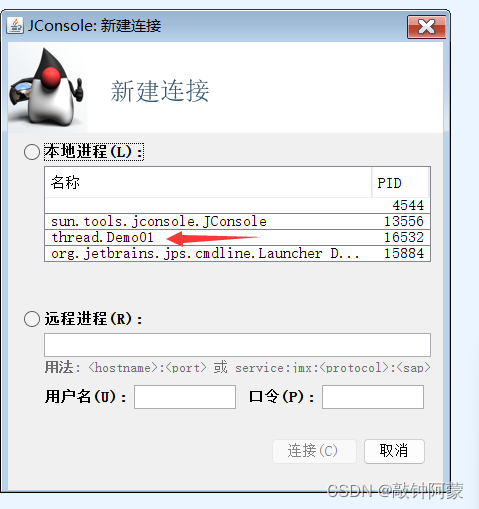
1.利用jconsole
2.打开界面
3.运行进程
只有进程被执行的时候,我们才能再jconsole上面看到对应的进程
所以,我们暂时将代码写成一个死循环
class MyThread extends Thread{
@Override
public void run() {
while(true)
System.out.println("打印线程2");
}
}
public class Demo01 {
public static void main(String[] args) {
Thread t=new MyThread();
t.start();
while(true){
System.out.println("打印主线程");
}
}
}
4.这时候,点击这个进入
5.我们再进入线程这一页面,就能在左下角看到相应的线程,main线程和thread-0线程
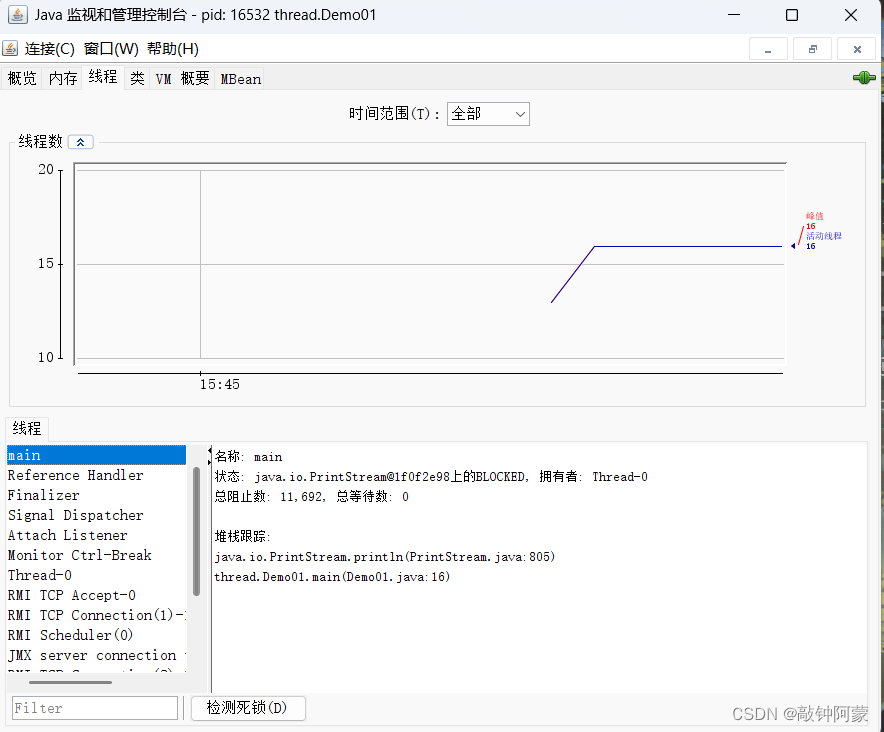
5.如何证明新旧线程是真的在并发运行的
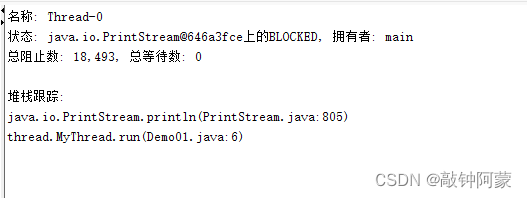
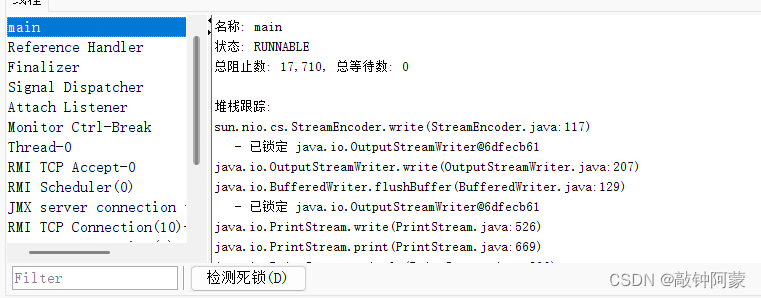
从这两张图就可以看出,main线程是在RUNNABLE,是在运行中,而Thread-0这个线程被main线程Blocked了,被阻塞了.也就说明,在这段时间内,两个线程是宏观上并行,微观上串行,也就是在并发进行中
6.如何证明线程真的被随机调度了
我们都知道,线程的调度是由系统调度器随机调度的,所以,上面的代码显示的结果的顺序是不一定的,那如何证明呢?
利用上述的循环代码就可以证明,但是不是特别优雅,我们可以在线程打印之前,让它每次执行前都等待一会,这样观察结果也就更为方便.可以.利用Thread.sleep这个静态的方法来操作
class MyThread extends Thread {
@Override
public void run() {
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("打印线程2");
}
}
}
public class Demo01 {
public static void main(String[] args) {
Thread t=new MyThread();
t.start();
while(true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("打印主线程");
}
}
}

这里就能很清楚得能看到不同,第二个红方框框住的结果的顺序显然跟其他的不一样,这确实证明了线程是被随机调度的
7.创建新线程的另外几种方式,技多不压身~
1.就是如上文中所述,创建一个类继承Thread,重写run
class MyThread extends Thread {
@Override
public void run() {
while(true){
System.out.println("Thread-0");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Demo01 {
public static void main(String[] args) {
Thread t=new MyThread();
t.start();
while(true){
System.out.println("main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
2.创建一个类,实现Runable接口,重写run.
class MyRunable implements Runnable{
@Override
public void run() {
while(true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread-0");
}
}
}
public class Test02 {
public static void main(String[] args) {
Runnable runnable=new MyRunable();
Thread t=new Thread(runnable);
t.start();
while(true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main");
}
}
}
3.仍然是使用继承Thread类,但是不再显示继承,而是使用匿名内部类
public class Test02 {
public static void main(String[] args) {
Thread t =new Thread(){
@Override
public void run() {
while(true){
System.out.println("Thread-0");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t.start();
while(true){
System.out.println("main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
4.使用Runable,匿名内部类
public class Test02 {
public static void main(String[] args) {
Thread t =new Thread(new Runnable() {
@Override
public void run() {
while(true){
System.out.println("Thread-0");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t.start();
while(true){
System.out.println("main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
5.使用lambda表达式
public class Test02 {
public static void main(String[] args) {
Thread t =new Thread(()->{
while(true){
System.out.println("Thread-0");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
while(true){
System.out.println("main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
其实,上面,它们的做法的本质都是一样的,为新线程里面分配工作,然后实例化Thread对象,再利用对象调用start方法
7.为何要多线程并发进行,更有效率?如何体现?
如何体现?对照试验
设置两组实验,一组直接是串行操作,记录开始和结束的时间,另一组是并发执行,记录时间
public class Test02 {
private static int count=2_000_000_000;
public static void serial(){
long beg=System.currentTimeMillis();
long a=0;
for (long i = 0; i <count ; i++) {
a++;
}
for (long i = 0; i <count ; i++) {
a++;
}
long end=System.currentTimeMillis();
System.out.println("串行时间为:"+(end-beg)+"ms");
}
public static void concurrency(){
long beg=System.currentTimeMillis();
Thread t1=new Thread(()->{
long a=0;
for (long i = 0; i <count ; i++) {
a++;
}
});
Thread t2=new Thread(()->{
long a=0;
for (long i = 0; i <count ; i++) {
a++;
}
});
t1.start();
t2.start();
long end =System.currentTimeMillis();
System.out.println("并行时间为:"+(end-beg)+"ms");
}
public static void main(String[] args) {
serial();
concurrency();
}
}
结果为:

看到这里,你是不是特别惊讶,这个并行的时间居然能有这么快!!!
直接快乐将近三十倍?!!!
当然,并行效率高那确实是高,但在这种情况下也没有高得这么离谱
主要还是因为线程的随机调度问题,
这个代码运行过程中,会有三个线程被创建
一个main线程,一个t1的线程,一个t2的线程
当线程被随机调度的时候,
它们三的运行顺序是不一致的,是随机的
并不是一个执行完,另一个才刚开始执行
可能t1,就只执行了几个指令,然后就调度t2执行几个指令,再调度main执行指令
然后可能是t2,t1,main,
main,t1,t2
有很多很多情况
所以,这些进程谁被先执行完就确定不了
但是这个代码中,
一旦随机调度器调度到main线程,相比于其他线程来说,main线程很快就被执行完了,
而main线程中,是包含有并发执行的方法的,在调用方法的时候,那个计时功能就直接越过另外两个线程
直接结束计时了
记住,线程之间是相对独立的,计时操作是在main线程中,而另外两个线程中,各有各的自增功能,互不干扰
所以,这种情况下,这种计时就非常不准,准确说,是不准得离谱
那如何实现只计时那两个线程呢,而不让main线程结束呢?**
这时候就要用到join
public class Test02 {
private static int count=2_000_000_000;
public static void serial(){
long beg=System.currentTimeMillis();
long a=0;
for (long i = 0; i <count ; i++) {
a++;
}
for (long i = 0; i <count ; i++) {
a++;
}
long end=System.currentTimeMillis();
System.out.println("串行时间为:"+(end-beg)+"ms");
}
public static void concurrency(){
long beg=System.currentTimeMillis();
Thread t1=new Thread(()->{
long a=0;
for (long i = 0; i <count ; i++) {
a++;
}
});
Thread t2=new Thread(()->{
long a=0;
for (long i = 0; i <count ; i++) {
a++;
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
long end =System.currentTimeMillis();
System.out.println("并行时间为:"+(end-beg)+"ms");
}
public static void main(String[] args) {
serial();
concurrency();
}
}
这时候显示的时间为:
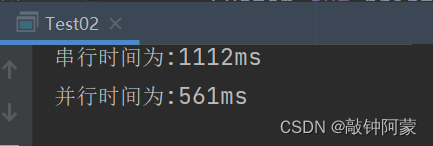
众所周知,代码每次计算的时间一般是不同的,要考虑多个因素的影响,但是大致稳定在一个区域内
这里面用了t1.join和t2.join,就是让main线程执行的时候,遇到了这两个,就得进入阻塞状态,要等待这两个线程的完成,它才能继续执行.
不论是t1先执行完还是t2先执行完,main总是要等待上面两个都执行完才可以执行
所以,随机调度器即使调度了main也执行不了,只能默默地执行完t1,t2
这就让计时的操作有了很大的可靠度
所以,到这一刻才能自信得说,并行的效率确实比串行要高!