这章我就来教大家使用百度翻译,当然不是简单的打开百度翻译的窗口来实现翻译而是通过js逆向去破解里面参数然后实现无需打开窗口也能翻译,相当于使用了其接口。
分析
首先我们先打开百度翻译窗口,f12进行分析。打开network,我们再输入一个你想翻译的单词。
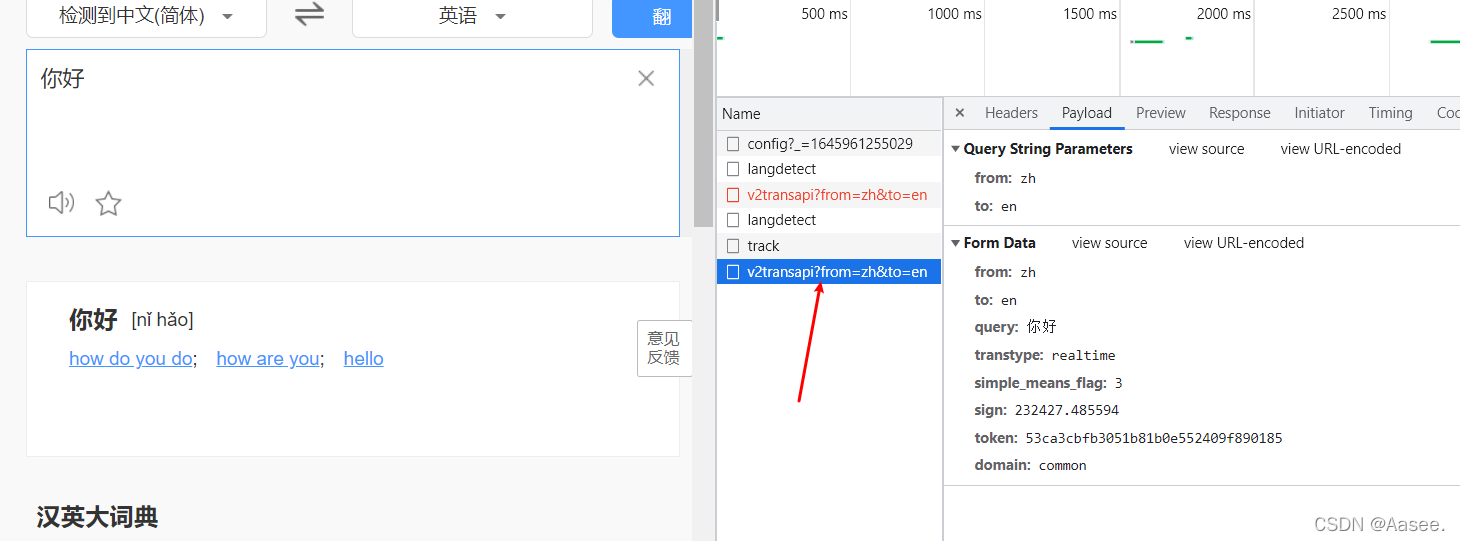
这时我们打开这几个看看哪个是我们所需要的内容,可以看到这里就是我们所需要的内容就在response里,payload就是我们所需要的请求参数,很明显我们如果需要得到我们所需要的内容只需要传入这几个参数到接口的地址上即可,这样想是不是觉得很简单,这时我们换个单词试试
断点
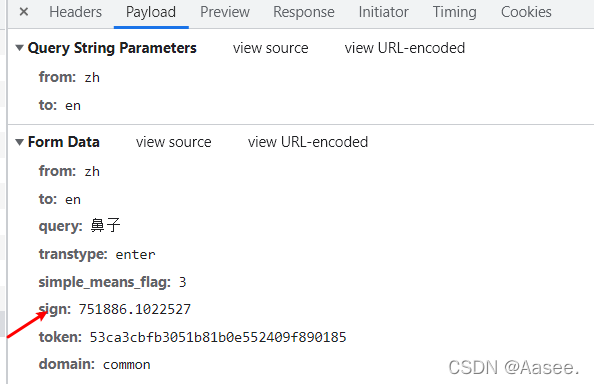
结果可以看到sign的值和query的值是会变化的,query的值好说只是我们需要翻译的单词,然而这个sign的值却是不确定的,那我就去看看他有规律或者说看他是怎么被生成的,我们全局搜索一下sign。

找到他之后给他断点debug一下
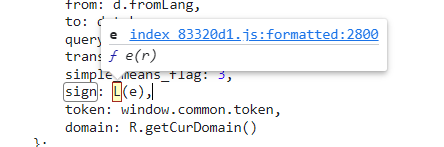
获取
从这里跳转过去看看实现sign的L方法。可以看到一整串的js代码

我们把function e()截取复制下来,放在一个新的js文件里
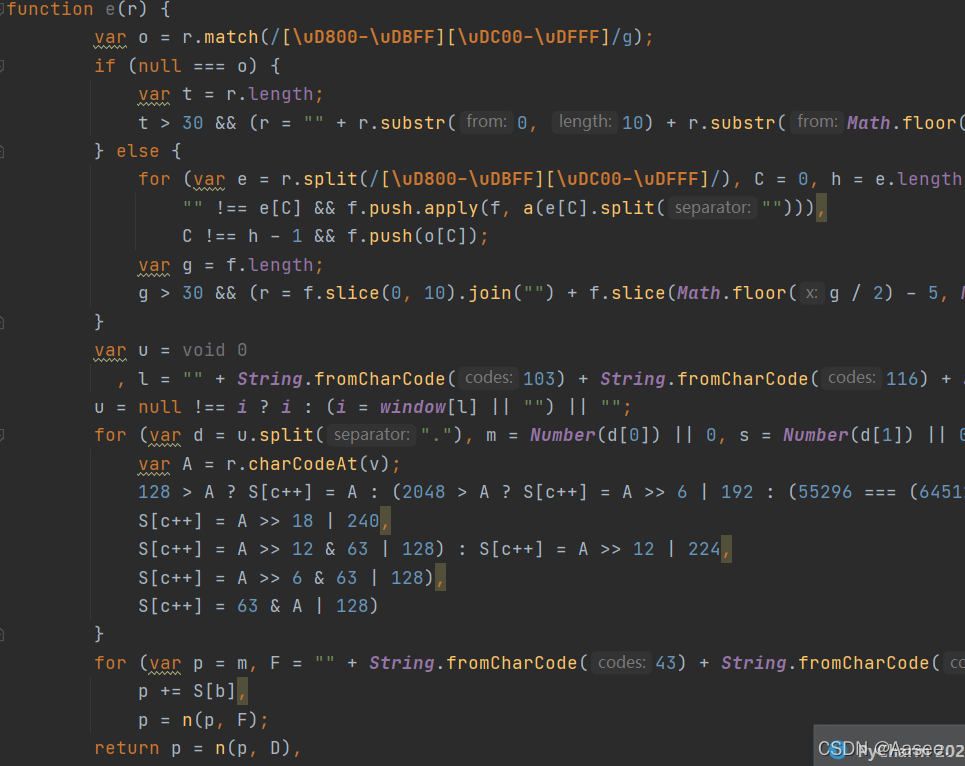
像这样,然后我们通过使用python来执行或者通过下载node插件直接执行,这里我是用python方法执行需要导入一个模块execjs,我没记错的话安装方法就是pip install execjs,因为很早前做的了已经记不太清了,如果不是请百度一波
测试
import execjs
def signGet(Query):
query = Query
with open('translata_js.js', 'r', encoding='utf-8')as f:
res = execjs.compile(f.read())
sign = res.call('e', query)
return sign
# print(sign)
# signGet("你好")
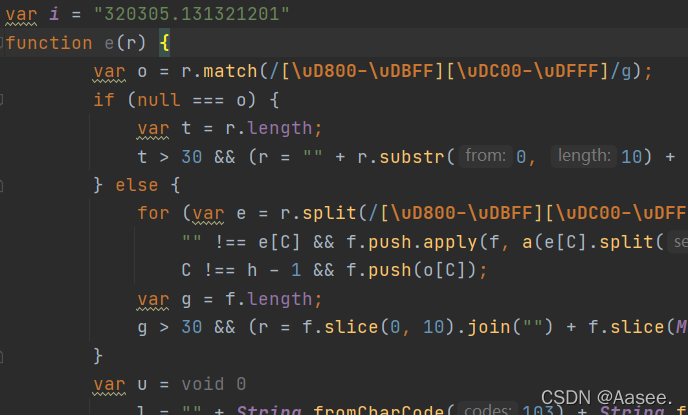
我们通过这个测试一下发现缺少了个 i.

我们返回网页上看一下 i 在哪

可以看到i就是一个固定的数值那我们只需要再js文件中声明一下i的值就行了,像这样
然后我们再执行一下看看是否能生成sign,结果他说找不到n

我们再回网页看看,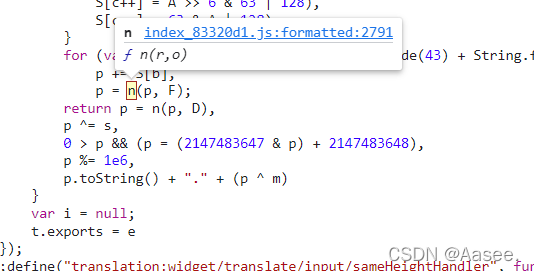
可以看到在这我们点进去看看,可以看到就是我们上面的function n() 方法,我们把他复制放进js文件看看,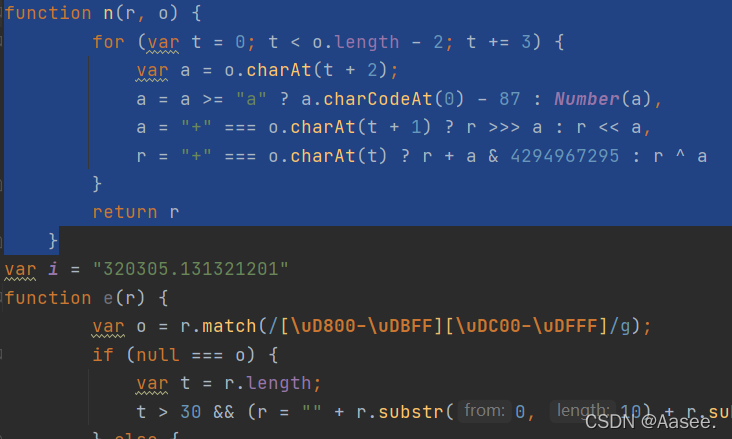
实现
再运行一下试试
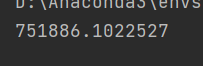
可以发现,现在我们所需要的sign值就获得了。那么接下来就可以开始写我们的爬虫代码了。因为官方不怎么允许爬虫文章所以为了这篇文章能发不在此处写爬虫部分,如果官方没禁大家可以看到我接下来的爬虫部分,要是禁了就看不到了。