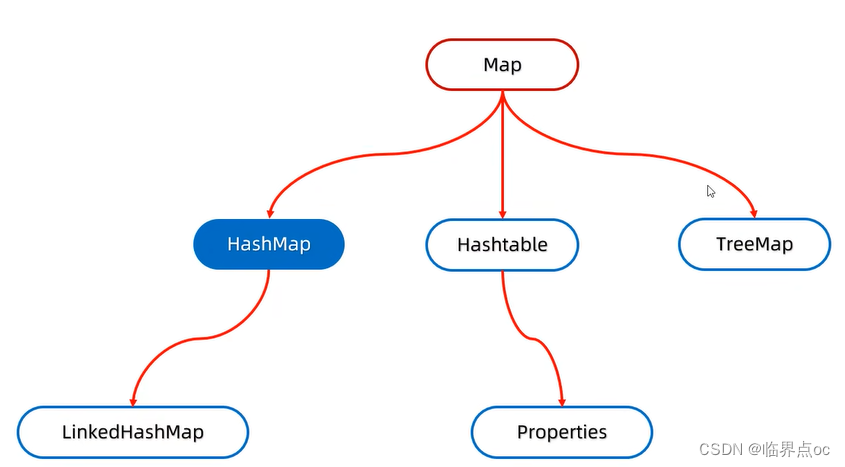
双列集合的特点
①双列集合一次需要存一堆数据,分别是键和值;
②键不能重复,值可以重复;
③键和值是一一对应的,每一个键只能找到自己对应的值;
④键 + 值这个整体我们称之为“键值对”或者“键值对对象”,在Java中叫做“Entry对象”。
Map的常见API
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的
| 方法名称 | 说明 |
| V put(K key, V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
练习一:
import java.util.HashMap;
import java.util.Map;
public class A01_MapDemo1 {
public static void main(String[] args) {
/*
V put(K key, V value) 添加元素
V remove(Object key) 根据键删除键值对元素
void clear() 移除所有的键值对元素
boolean containsKey(Object key) 判断集合是否包含指定的键
boolean containsValue(Object value) 判断集合是否包含指定的值
boolean isEmpty() 判断集合是否为空
int size() 集合的长度,也就是集合中键值对的个数
*/
// 1. 创建Map集合的对象
Map<String, String> m = new HashMap<>();
// 2. 添加元素
// put方法的细节:
// 添加/覆盖
// 在添加数据的时候,如果键不存在,那么直接把键值对添加到map集合中,方法返回null
// 在添加数据的时候,如果键是存在的,那么会把原有的键值对对象覆盖,会把覆盖的值进行返回
String value1 = m.put("郭靖", "黄蓉");
// System.out.println(value1);
m.put("韦小宝", "沐剑屏");
m.put("尹志平", "小龙女");
// String value2 = m.put("韦小宝", "双儿");
// System.out.println(value2);
// 3. 删除元素
// String result = m.remove("郭靖");
// System.out.println(result); // 黄蓉
// 4. 清空
// m.clear();
// 5. 判断是否包含键
// boolean keyResult = m.containsKey("郭靖");
// System.out.println(keyResult); // true
// 6. 判断是否包含值
// boolean valueResult = m.containsValue("小龙女");
// System.out.println(valueResult); // true
// 7. 判断集合是否为空
// boolean result = m.isEmpty();
// System.out.println(result); // false
// 集合的size
int size = m.size();
System.out.println(size); // 3
// 8. 打印集合
System.out.println(m);
}
}
Map的遍历方式
方式一:键找值
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class A02_MapDemo2 {
public static void main(String[] args) {
// Map集合的第一种遍历方式
// 1. 创建集合的对象
Map<String, String> map = new HashMap<>();
// 2. 添加元素
map.put("尹志平", "小龙女");
map.put("郭靖", "穆念慈");
map.put("欧阳克", "黄蓉");
// 3. 通过键找值
// 3.1 获取所有的键,把这些键放到一个单列集合当中
Set<String> keys = map.keySet();
// 3.2 遍历单列集合,得到每一个键
for (String key : keys) {
// System.out.println(key);
// 3.3 利用map集合中的键获取相对应的值 get
String value = map.get(key);
System.out.println(key + " = " + value);
}
}
}
方式二:键值对
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class A02_MapDemo3 {
public static void main(String[] args) {
// Map集合的第二中遍历方式
// 1. 创建Map集合的对象
Map<String, String> map = new HashMap<>();
// 2. 添加元素
// 键:人物的外号 值:人物的名字
map.put("标枪选手", "马超");
map.put("人物挂件", "明世隐");
map.put("御龙骑士", "尹志平");
// 3. Map集合的第二中遍历方式
// 通过键值对对象进行遍历
// 3.1 通过一个方法获取所有的键值对对象,返回一个Set集合
Set<Map.Entry<String, String>> entries = map.entrySet();
// 3.2 遍历entries这个集合,去得到里面的每一个键值对对象
for (Map.Entry<String, String> entry : entries) {
// 3.3 利用entry调用get方法获取键和值
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " = " + value);
}
}
}
方式三:forEach
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
public class A02_MapDemo4 {
public static void main(String[] args) {
// Map集合的第三种遍历方式
// 1. 创建Map集合的对象
Map<String, String> map = new HashMap<>();
// 2. 添加元素
// 键:人物的名字
// 值:名人名言
map.put("鲁迅", "这句话是我说的");
map.put("曹操", "不可能绝对不可能");
map.put("刘备", "接着奏乐接着舞");
map.put("柯镇恶", "看我眼色行事");
// 3. 利用lambda表达式进行遍历
// 底层:forEach其实就是利用第二种方式进行遍历,依次得到每一个键值对
/* map.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key + " = " + value);
}
});*/
map.forEach((key, value)-> System.out.println(key + " = " + value));
}
}
HashMap
特点:
①HashMap是Map里面的一个实现类;
②没有额外需要学习的特有方法,直接使用Map里面的方法就可以了;
③特点都是由键决定的:无序、不重复、无索引;
④HashMap跟HashSet底层原理是一模一样的,都是哈希表结构
⑤如果键存储的是自定义对象,需要重写hashCode和equals方法。如果值存储自定义对象,不需要重写hashCode和equals方法
练习一:
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.function.BiConsumer;
public class A05_HashMapDemo1 {
public static void main(String[] args) {
/*
需求:创建一个HashMap集合,键是学生对象(Student),值是籍贯(String)
存储三个键值对元素,并遍历
要求:同姓名、同年龄认为是同一个学生
核心点:HashMap的键位置如果存储的是自定义对象,需要重写hashCode和equals方法
*/
// 1. 创建HashMap对象
HashMap<Student, String> hm = new HashMap<>();
// 2. 创建三个学生对象
Student s1 = new Student("zhangsan", 23);
Student s2 = new Student("lisi", 24);
Student s3 = new Student("wangwu", 25);
Student s4 = new Student("wangwu", 25);
// 3. 添加元素
//
hm.put(s1, "江苏");
hm.put(s2, "浙江");
hm.put(s3, "福建");
hm.put(s4, "山东");
// 4. 遍历集合
Set<Student> keys = hm.keySet();
for (Student key : keys) {
String value = hm.get(key);
System.out.println(key + " = " + value);
}
System.out.println("---------------------------------");
Set<Map.Entry<Student, String>> entries = hm.entrySet();
for (Map.Entry<Student, String> entry : entries) {
Student key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " = " + value);
}
System.out.println("-------------------------------");
hm.forEach((student, s) -> System.out.println(student + " = " + s));
}
}
练习二:
import java.util.*;
public class A05_HashMapDemo2 {
public static void main(String[] args) {
/*
需求:某个班级80名学生,现在需要组织秋游活动,班长提供了四个景点依次是(A、B、C、D),
每个学生只能选择一个景点,请统计出最终哪个景点想去的人数最多
*/
// 1. 需要先让同学们投票
// 定义一个数组,存储4个景点
String[] arr = {"A", "B", "C", "D"};
// 利用随机数模拟80个同学的投票,并把投票的结果存储起来
ArrayList<String> list = new ArrayList<>();
Random r = new Random();
for (int i = 0; i < 80; i++) {
int index = r.nextInt(arr.length);
list.add(arr[index]);
}
// 2. 如果需要统计的东西比较多,不方便使用计数器思想
// 我们可以定义map集合,利用集合进行统计
HashMap<String, Integer> hm = new HashMap<>();
for (String name : list) {
// 判断当前的景点在map集合当中是否存在
if(hm.containsKey(name)) {
// 存在
// 先获取当前景点已经被投票的次数
int count = hm.get(name);
// 表示当前景点又被投了一次
count++;
// 把新的次数再次添加到集合当中(覆盖)
hm.put(name, count);
} else {
// 不存在
hm.put(name, 1);
}
}
System.out.println(hm);
// 3. 求最大值
int max = 0;
// 遍历
Set<Map.Entry<String, Integer>> entries = hm.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
Integer count = entry.getValue();
if(count > max) {
max = count;
}
}
System.out.println(max);
// 4. 判断哪个景点的次数跟最大值一样,如果一样,打印出来
for (Map.Entry<String, Integer> entry : entries) {
Integer count = entry.getValue();
if(count == max) {
System.out.println(entry.getKey());
}
}
}
}
练习三:
import java.util.*;
public class Test4 {
public static void main(String[] args) {
/*
定义一个Map集合,键表示省份名称province,值表示市city,但是市会有多个
添加完毕后,遍历结果如下:
江苏省 = 南京市,扬州市,苏州市,无锡市,常州市
湖北省 = 武汉市,孝感市,十堰市,宜昌市,鄂州市
河北省 = 石家庄市,唐山市,邢台市,保定市,张家口市
*/
// 1. 创建Map集合
HashMap<String , ArrayList<String>> hm = new HashMap<>();
// 2. 创建单列集合存储市
ArrayList<String> city1 = new ArrayList<>();
city1.add("南京市");
city1.add("扬州市");
city1.add("苏州市");
city1.add("无锡市");
city1.add("常州市");
ArrayList<String> city2 = new ArrayList<>();
city2.add("武汉市");
city2.add("孝感市");
city2.add("十堰市");
city2.add("宜昌市");
city2.add("鄂州市");
ArrayList<String> city3 = new ArrayList<>();
city3.add("石家庄市");
city3.add("唐山市");
city3.add("邢台市");
city3.add("保定市");
city3.add("张家口市");
// 3. 把省份和多个市添加到map集合中
hm.put("江苏省", city1);
hm.put("湖北省", city2);
hm.put("河北省", city3);
// 4. 遍历
Set<Map.Entry<String, ArrayList<String>>> entries = hm.entrySet();
for (Map.Entry<String, ArrayList<String>> entry : entries) {
// 每个entries依次表示每一个键值对对象
String key = entry.getKey();
ArrayList<String> value = entry.getValue();
StringJoiner sj = new StringJoiner(", ", "", "");
for (String city : value) {
sj.add(city);
}
System.out.println(key + " = " + sj);
}
}
}
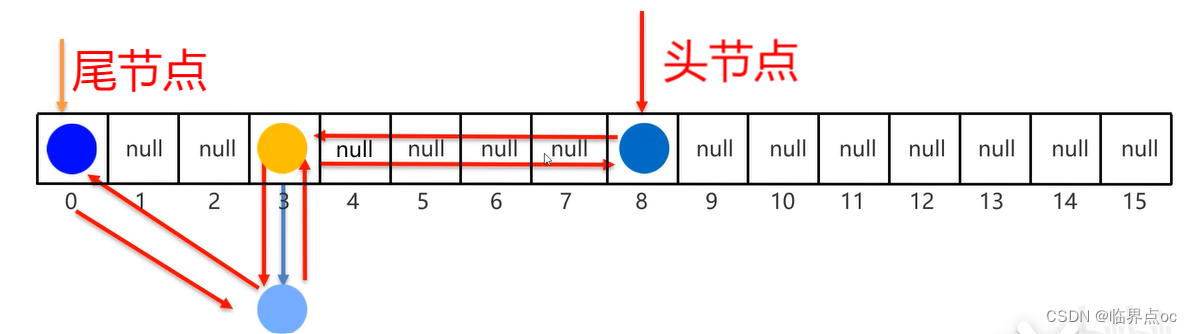
LinkedHashMap
特点:
- 由键决定:有序、不重复、无索引
- 这里的有序是指保证存储和取出的元素顺序一致
- 原理:底层数据结构是哈希表,只是每个键值对元素额外多了一个双链表的机制记录存储的顺序。
import java.util.LinkedHashMap;
public class A07_LinkedHashMapDemo3 {
public static void main(String[] args) {
/*
由键决定:有序、不重复、无索引
这里的有序是指保证存储和取出的元素顺序一致
原理:底层数据结构是哈希表,只是每个键值对元素额外多了一个双链表的机制记录存储的顺序。
*/
// 1. 创建集合
LinkedHashMap<String, Integer> lhm = new LinkedHashMap<>();
// 2. 添加元素
lhm.put("c", 789);
lhm.put("a", 123);
lhm.put("a", 111); // 覆盖
lhm.put("b", 456);
// 3. 打印集合
System.out.println(lhm); // {c=789, a=111, b=456}
}
}
TreeMap
特点:
- TreeMap跟TreeSet底层原理一样,都是红黑树结构的,增删改查性能较好
- 由键决定特性:不重复、无索引、可排序
- 可排序:对键进行排序
- 注意:默认按照键的从小到大进行排序,也可以自己规定键的排序规则
两种排序规则:
- 实现Comparable接口,指定比较规则
- 创建集合时传递Comparator比较器对象,指定比较规则
练习一:
import java.util.Comparator;
import java.util.TreeMap;
public class A01_TreeMapDemo1 {
public static void main(String[] args) {
/*
需求1:
键:整数表示id
值:字符串表示商品名称
要求:按照id的升序排列、按照id的降序排列
*/
// 1. 创建集合对象
// Integer Double默认情况下都是按照升序排列的
// String 按照字母在ASCII码表中对应的数字升序进行排列
TreeMap<Integer, String> tm = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
// o1表示当前要添加的元素
// o2表示已经在红黑树中存在的元素
return o2 - o1; // 降序
}
});
// 2. 添加元素
tm.put(4, "雷碧");
tm.put(1, "粤利粤");
tm.put(3, "九个核桃");
tm.put(2, "康师傅");
tm.put(5, "可恰可乐");
// 3. 打印集合
System.out.println(tm); // {5=可恰可乐, 4=雷碧, 3=九个核桃, 2=康师傅, 1=粤利粤}
}
}
练习二:
// Student类
import java.util.Objects;
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
@Override
public int compareTo(Student o) {
// 按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名年龄视为同一个人
// this:表示当前要添加的元素
// o:表示已经在红黑树中存在的元素
// 返回值:负数表示当前要添加的元素是小的,存左边
// 正数表示当前要添加的元素是大的,存左边
// 0:表示当前要添加的元素已经存在,舍弃
int i = this.getAge() - o.getAge();
i = i == 0 ? this.getName().compareTo(o.getName()) : i;
return i;
}
}
// 测试类
import java.util.TreeMap;
public class A02_TreeMapDemo2 {
public static void main(String[] args) {
/*
需求2:
键:学生对象
值:籍贯
要求:按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名年龄视为同一个人
*/
// 1. 创建集合
TreeMap<Student, String> tm = new TreeMap<>();
// 2. 创建3个学生对象
Student s1 = new Student("zhangsan", 23);
Student s2 = new Student("lisi", 24);
Student s3 = new Student("wangwu", 25);
// 3. 添加元素
tm.put(s1, "江苏");
tm.put(s2, "天津");
tm.put(s3, "福建");
// 4. 打印集合
System.out.println(tm); // {Student{name = zhangsan, age = 23}=江苏, Student{name = lisi, age = 24}=天津, Student{name = wangwu, age = 25}=福建}
}
}
练习三:
import java.util.StringJoiner;
import java.util.TreeMap;
public class A03_TreeMapDemo3 {
public static void main(String[] args) {
/*
需求:字符串”aababcabcdabcde"
请统计字符串中每一个字符出现的次数,并按照以下格式输出
输出结果:
a(5) b(4) c(3) d(2) e(1)
分析:统计 ----> 计数器思想
弊端:如果我们要统计的东西比较多,非常的不方便
新的思想:利用map集合进行统计
HashMap、TreeMap 键:表示要统计的内容 值:表示次数
如果题目没有要求对结果进行排序,默认使用HashMap;如果题目中敖犬对结果进行排序,使用TreeMap
*/
// 1. 定义字符串
String s = "aababcabcdabcde";
// 2. 创建集合
TreeMap<Character, Integer> tm = new TreeMap<>();
// 3. 遍历字符串得到里面的每一个字符
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
// 拿着c到集合中判断是否存在
// 存在,表示当前字符又出现了一次
// 不存在,表示当前字符是第一次出现
if(tm.containsKey(c)) {
// 存在
// 先把已经出现的次数拿出来
int count = tm.get(c);
// 当前字符又出现了一次
count++;
// 把自增之后的结果再添加到集合当中
tm.put(c, count);
} else {
// 不存在
tm.put(c, 1);
}
}
// 4. 遍历集合,并按照指定的格式进行拼接
// a(5) b(4) c(3) d(2) e(1)
StringBuilder sb = new StringBuilder();
tm.forEach((key, value)-> sb.append(key).append("(").append(value).append(")"));
System.out.println(sb);
// 或
StringJoiner sj = new StringJoiner("", "", "");
tm.forEach((key, value)-> sj.add(key + "").add("(").add(value + "").add(")"));
System.out.println(sj);
}
}
思考题:
1. TreeMap添加元素的时候,键是否需要重写hashCode和equals方法?
答:此时是不需要重写的。hashCode和equals方法和HashMap的键有关。
2. HashMap是哈希表结构的,JDK8开始由数组、链表、红黑树组成。既然有红黑树,是否需要利用Comparable指定排序规则?是否需要传递比较器Comparator指定比较规则?
答:不需要。因为在HashMap的底层,默认是利用哈希值的大小关系来创建红黑树的。
3. TreeMap和HashMap谁的效率更高?
答:如果是最坏情况,添加了8个元素,这8个元素形成了链表,此时TreeMap的效率更高。但是这种情况出现的几率非常的少。一般而言,还是HashMap的效率更高。
4. 你觉得在Map集合中,Java会提供一个如果键重复了,不会覆盖的put方法吗?
答:存在putIfAbsent方法。此时putIfAbsent方法本身不重要。传递一个思想:代码中的逻辑都有两面性,如果我们只知道了其中的A面,而且代码中还发现了变量可以控制两面性,那么该逻辑一定会有B面。
习惯:boolean类型的变量控制,一般只要AB两面,因为boolean只有两个值。int类型的变量控制,一般至少有三面,因为int可以取多个值。
5. 三种双列集合,以后如何选择?
答:默认情况下,选用HashMap,效率最高;
如果要保证存取有序,选用LinkedHashMap
如果要进行排序,选用TreeMap。