Redis 可用于处理业务逻辑,作为系统的一部分。除此之外,Redis 还可以帮助和支持系统的其他部分,例如:用于记录日志,进行数据统计,实现配置自动化以及制作一些有趣的实用小程序等。
本实训将通过构建日志记录组件,统计网页访问数据以及 IP 地址库小工具三个实际应用场景展示如何使用 Redis 帮助和支持应用程序。
一、使用Redis记录日志
任务描述
本关任务:使用
Redis记录日志。相关知识
为了完成本关任务,你需要掌握:
1、redis相关命令,2、python相关命令。redis相关命令
lpush
: 将一个值插入到列表头部,保证后插入的在最前面。
conn = redis.Redis() pipe = conn.pipeline() pipe.lpush("testlist", "c")ltrim:
让列表只保留指定区间内的元素。
conn = redis.Redis() pipe = conn.pipeline() pipe.ltrim("testlist", 0, 1)multi:
事务块内的多条命令会按照先后顺序被放进一个队列当中,最后由
EXEC命令原子性(atomic)地执行队列里的命令。conn = redis.Redis() pipe = conn.pipeline() pipe.multi() # 标记事务开始 pipe.incr("user_id") pipe.incr("user_id") pipe.incr("user_id") pipe.EXEC() #执行watch:
用于监视一个 key ,如果在事务执行之前这个 key 的值被改动,那么事务将被打断。一般和
MULTI命令配合使用,解决并发过程中重复操作的问题。例子:商品下单时是需要对库存数
stock_count进行减库存操作,通过watch和multi来锁库存。conn = redis.Redis() pipe = conn.pipeline() try: pipe.watch('stock_count’) count = int(pipe.get('stock_count')) if count > 0: # 有库存 # 事务开始 pipe.multi() pipe.set('stock_count', count - 1) # 事务结束 pipe.execute() except redis.exceptions.WatchError: #抓取stock_count改变异常zincrby:
对有序集合中指定成员的分数加上增量
increment,用于统计。对
key:zset_name, 值:a1进行递增conn = redis.Redis() pipe = conn.pipeline() pipe.zincrby("zset_name","a1")执行后效果
zset_name:a11rename
命令用于修改
key的名称把
key:zset_name修改为zset_name1conn = redis.Redis() pipe = conn.pipeline() pipe.rename("zset_name", "zset_name1")执行后效果
zset_name1:a11python相关命令
返回当前时间的时间戳
time.time()返回时间格式化字符串
time.asctime()执行结果:
Tue Dec 11 15:07:14 2018获取当前小时数:例如当前时间
15:07:14time.localtime().tm_hour执行结果:
15编程要求
在
Begin-End区域编写log_to_redis(message, level=logging.INFO):函数,实现记录最新日志的功能,具体参数与要求如下:
- 方法参数
message为日记内容;- 定义一个
redis列表,列表key为log:recent:info, 列表value为时间加-加message,要求每次新的日记内容需存在列表头部,并只保留最新的5000个元素。注意:value中的时间取
time.asctime()编写
log_to_redis_by_frequency(message, level=logging.INFO):函数,实现统计常见日志次数及写入最新日记、并对历史日志记录进行迁移,具体参数与要求如下:
- 在方法
log_to_redis_by_frequency中,方法参数message为日记内容;- 定义一个
redis列表,列表key为log:count:info,列表value为message;- 定义一个
redis字符串,字符串key为log:count:info:start,字符串value为当前小时数;- 对历史日志记录进行迁移功能实现:当
value小于当前时间小时数,则重命名redis列表,修改列表key为log:count:info:lasthour,修改redis字符串值为当前时间小时数;- 统计常见日志次数及写入最新日记功能实现:存储
redis列表的成员为message,分数自增1,并调用log_to_redis方法存最新消息;- 考虑到历史日记记录迁移的并发问题,使用
swatch监控log:count:info,如果log:count:info已经修改,则捕获redis.exceptions.WatchError,从而退出。
```python
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import time
import redis
import logging
conn = redis.Redis()
LOGLEVEL = {
logging.DEBUG: "debug",
logging.INFO: "info",
logging.WARNING: "warning",
logging.ERROR: "error"
}
# 记录最新日志
def log_to_redis(message, level=logging.INFO):
log_list = "log:recent:" + LOGLEVEL[level]
# 将消息格式化为时间戳和消息内容
message = time.asctime() + ' - ' + message
# 创建 Redis pipeline
pipe = conn.pipeline()
# 将消息推入列表
pipe.lpush(log_list, message)
# 保留最新的5000条日志
pipe.ltrim(log_list, 0, 4999)
# 执行 pipeline
pipe.execute()
# 记录常见日志
def log_to_redis_by_frequency(message, level=logging.INFO):
log_key = "log:count:" + LOGLEVEL[level]
start_key = log_key + ":start"
# 创建 Redis pipeline
pipe = conn.pipeline()
end = time.time() + 10
while time.time() < end:
try:
# 监视 start_key
pipe.watch(start_key)
cur_hour = time.localtime(time.time()).tm_hour
start_hour = pipe.get(start_key)
pipe.multi()
# 检查是否跨小时
if start_hour and start_hour < cur_hour:
# 重命名键和更新起始时间
pipe.rename(log_key, log_key + ":lasthour")
pipe.set(start_key, cur_hour)
# 增加消息在有序集合中的计数
pipe.zincrby(log_key, 1, message)
# 执行 pipeline
pipe.execute()
# 同时将消息记录到最新日志
log_to_redis(message, level)
return True
except redis.exceptions.WatchError:
pass
```
二、使用Redis计数和统计数据
任务描述
本关任务:使用
Redis统计网站的每日PV和每日UV。相关知识
每日
PV(Page View)即一天的页面浏览量或点击量,衡量网站用户访问的网页数量。每日
UV(Unique Visitor)即一天的独立访客数,统计一天内访问某站点的用户数(一般以cookie为依据)。为了完成本关任务,你需要掌握:
1、redis相关命令,2、python相关命令。redis相关命令
hincrby:
为哈希中指定域的值增加增量
increment,用于统计。conn = redis.Redis() conn.hincrby("testhash", "field1", 1)zadd:
将成员加入到有序集合中,并确保其在正确的位置上。
conn = redis.Redis() conn.zadd("testzset", "member2", 3) conn.zadd("testzset", "member1", 2) conn.zadd("testzset", "member3", 1)hget:
从哈希中获取指定域的值。
conn = redis.Redis() conn.hget("testhash", "field1")zcount:
统计有序集合中分值在
min和max之间(包括等于min和max)的成员的数量。conn = redis.Redis() conn.zadd("testzset", "member1", 10) conn.zadd("testzset", "member2", 70) conn.zadd("testzset", "member3", 50) conn.zadd("testzset", "member4", 100) conn.zcount("testzset", 60, 100)python相关命令
返回当日日期:
time.strftime("%Y%m%d")执行结果:
20181212返回当日
0点时间元组:time.strptime('20181101', '%Y%m%d')执行结果为:
time.struct_time(tm_year=2018, tm_mon=11, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=305, tm_isdst=-1)返回时间元组对应的时间戳:
test_struck_time = time.strptime('20181101', '%Y%m%d') time.mktime(test_struck_time)执行结果为:
1541001600.0编程要求
在
Begin-End区域编写record_viewer(user_id)函数,实现累记PV和UV值的功能,具体参数与要求如下:
- 方法参数
user_id为访问用户ID- 累计
PV实现:为哈希键page_view中的当前日期域的值累加1,当前日期域格式为20181101- 累计
UV实现:将该访问用户ID加入到有序集合键unique_visitor中,并置分值为当前时间编写
stats_viewer(stats_day)函数,实现统计PV值和UV值并返回的功能,具体参数与要求如下:
- 方法参数
stats_day为需要统计的日期,格式为:20181101- 统计
PV实现:从哈希键page_view中得到该日期域的值,记为PV- 统计
UV实现:统计有序集合键unique_visitor中分值介于需要统计的日期的0点和24点时间戳之间的成员数量,记为UV- 返回
PV值和UV值,格式为[PV, UV]
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import time
import redis
conn = redis.Redis()
# 使用计数器记录 PV 和 UV
def record_viewer(user_id):
current_date = time.strftime('%Y%m%d', time.localtime())
timestamp = time.time()
pipe = conn.pipeline()
pipe.multi()
# 累计 PV
pipe.hincrby('page_view', current_date, 1)
# 累计 UV
pipe.zadd('unique_visitor',user_id ,timestamp)
pipe.execute()
# 使用计数器统计数据
def stats_viewer(stats_day):
pv_value = conn.hget('page_view', stats_day)
start_timestamp = int(time.mktime(time.strptime(stats_day, "%Y%m%d")))
end_timestamp = start_timestamp + 86400
uv_value = conn.zcount('unique_visitor', start_timestamp, end_timestamp)
return [pv_value, uv_value]三、使用Redis实现IP地址库
任务描述
本关任务:使用
Redis编写一个IP地址库。相关知识
为了完成本关任务,你需要掌握:
1、redis相关命令,2、python相关命令,3.IP如何转换为整数。redis相关命令
zadd:将成员加入到有序集合中,并确保其在正确的位置上。
conn = redis.Redis() conn.zadd("testzset", "member2", 3) conn.zadd("testzset", "member1", 2) conn.zadd("testzset", "member3", 1)zrevrangebyscore:返回有序集合中分值介于
max和min之间(包括等于max或min)的所有成员,并按分值递减(从大到小)的次序排列。conn = redis.Redis() conn.zadd("testzset", "member1", 10) conn.zadd("testzset", "member2", 70) conn.zadd("testzset", "member3", 50) conn.zadd("testzset", "member4", 100) conn.zrevrangebyscore("testzset", 100, 50)python相关命令
将字符串转换为十进制数:
int("110", 10)打开文件:
csv_file = open(filename)执行后得到一个文件对象。
获得
CSV文件的所有行:data = csv.reader(csv_file)执行后得到
CSV文件中所有行的列表。遍历
CSV文件中的所有行:for count, row in enumerate(data): print(count) print(row)执行结果:
0["第一行第一列", "第一行第二列", "第一行第三列"]1["第二行第一列", "第二行第二列", "第二行第三列"]...判断一个字符串是否为数值型字符串:
"123".isdigit() "123a".isdigit()执行结果:
TrueFalse使用分隔符拆分字符串:
"1.2.3.4".split(".")执行结果:
['1', '2', '3', '4']判断字符串是否包含指定字符:
'a' in 'apple' 'b' in 'apple'执行结果:
TrueFalseIP如何转换为整数
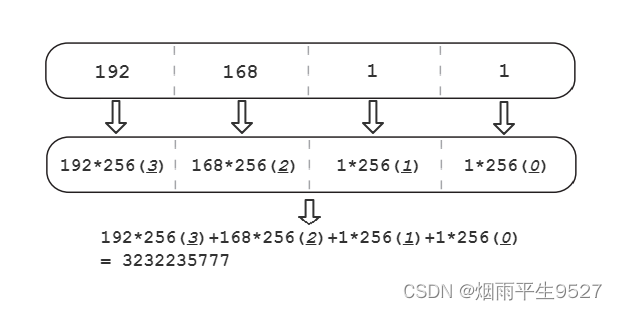
将
192.168.1.1转换为长整型数的过程如下:
编程要求
在
Begin-End区域编写ip2long(ip_address)函数,实现将IP转换成整数的功能,具体参数与要求如下:
- 方法参数
ip_address为待转换的IP地址;IP转换成长整型数实现:使用分隔符.将IP地址拆分为四段,将每一段转换为十进制数,并使用迭代的方法将整个IP地址转换为长整型数;- 返回转换好的整数值。
编写
import_ip_to_redis(filename)函数,实现将IP地址库导入Redis的功能,具体参数与要求如下:
- 方法参数
filename为IP地址库文件名;- 数据导入
Redis实现:打开并遍历该CSV文件,文件第一列为IP段的起始值,第二列为IP段的结束值,第三列为IP段所属的城市ID,例如
- 若`IP`段起始值包含英文字符或为空串,则不处理该行。 - 若`IP`段起始值是`IP`格式,则调用`ip2long`方法转换为整数。 - 若`IP`段起始值为数值型字符串,则转换为十进制数。 - 为保持有序集合中城市`ID`唯一,将城市`ID`加`_`加当前行索引值做为成员,经过上述处理的`IP`段起始值做为分值存入有序集合 `ip2city` 中。
编写
find_city_by_ip(ip_address)函数,实现根据输入的IP地址找到所属的城市ID的功能,具体参数与要求如下:
- 方法参数
ip_address为待查找的IP地址;- 调用
ip2long方法将待查找的IP地址转换成整数,便于在有序集合中查找;- 查找所属城市
ID实现:从有序集合ip2city中查找出分值小于等于上述整数的所有成员,其中分值最大的成员则为该IP地址所属的城市ID;- 还原城市
ID实现:去除上述城市ID中_字符及其之后的字符;- 返回城市
ID。

#!/usr/bin/env python
#-*- coding:utf-8 -*-
import csv
import time
import redis
conn = redis.Redis()
# 将 IP 转换为整型数据
def ip2long(ip_address):
# 将 IP 地址字符串转换为整型
ip_parts = ip_address.split('.')
ip_integer = 0
for part in ip_parts:
ip_integer = ip_integer * 256 + int(part, 10)
return ip_integer
# 将 IP 地址库导入 Redis
def import_ip_to_redis(filename):
# 从CSV文件中读取IP地址和城市信息,将IP转换为整型并存入Redis
csv_file = open(filename)
ori_data = csv.reader(csv_file)
for count, row in enumerate(ori_data):
start_ip = row[0] if row else ""
if 'i' in start_ip:
continue
if '.' in start_ip:
start_ip = ip2long(start_ip)
elif start_ip.isdigit():
start_ip = int(start_ip, 10)
else:
continue
city_id = row[2] + '_' + str(count)
conn.zadd("ip2city", city_id, start_ip)
# 查找 IP 所属城市 ID
def find_city_by_ip(ip_address):
# 查找给定IP地址所属的城市ID
ip_address = ip2long(ip_address)
city_id = conn.zrevrangebyscore("ip2city", ip_address, 0)
city_id = city_id[0].split("_")[0]
return city_id