1 删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
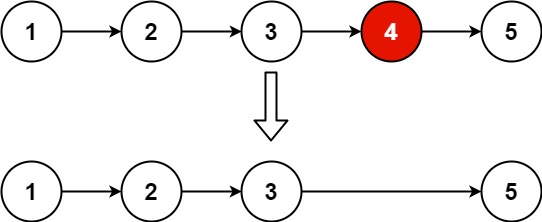
输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1 输出:[]
示例 3:
输入:head = [1,2], n = 1 输出:[1]
提示:
- 链表中结点的数目为
sz 1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
1 双指针建立虚拟头节点思路:
建立虚拟头节点的目的通常是为了简化链表操作的逻辑,并且更方便地处理边界情况。在链表操作中,有时需要对链表头部进行插入、删除或者其他操作,而这些操作可能会导致需要特别处理头部指针的情况,特别是当链表为空时。使用虚拟头节点可以使得链表的头部始终存在,即使链表为空,也可以通过虚拟头节点来进行操作,这样就避免了对头指针进行特殊处理的情况,简化了代码逻辑。
虚拟头节点并不存储实际的数据,它只是一个辅助节点,用于指向链表的真实头节点,这样操作链表时就不需要对头指针是否为空进行判断。此外,虚拟头节点还可以避免对头节点进行特殊处理,从而提高代码的可读性和可维护性。
双指针的经典应用,如果要删除倒数第n个节点,让fast移动n步,然后让fast和slow同时移动,直到fast指向链表末尾。删掉slow所指向的节点就可以了。
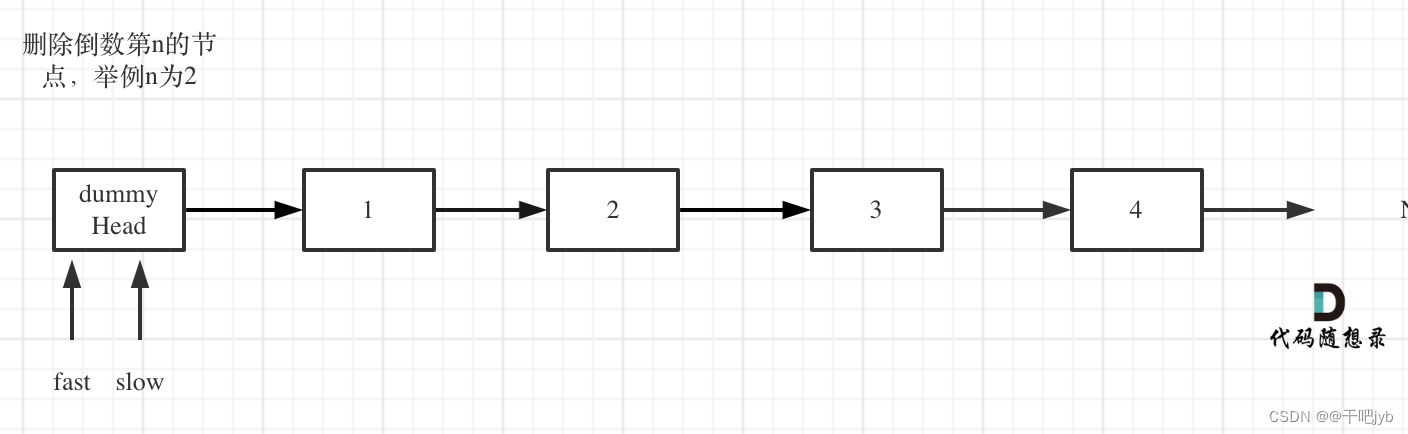
1定义fast指针和slow指针,初始值为虚拟头结点,如图:
2fast和slow同时移动,直到fast指向末尾,如图: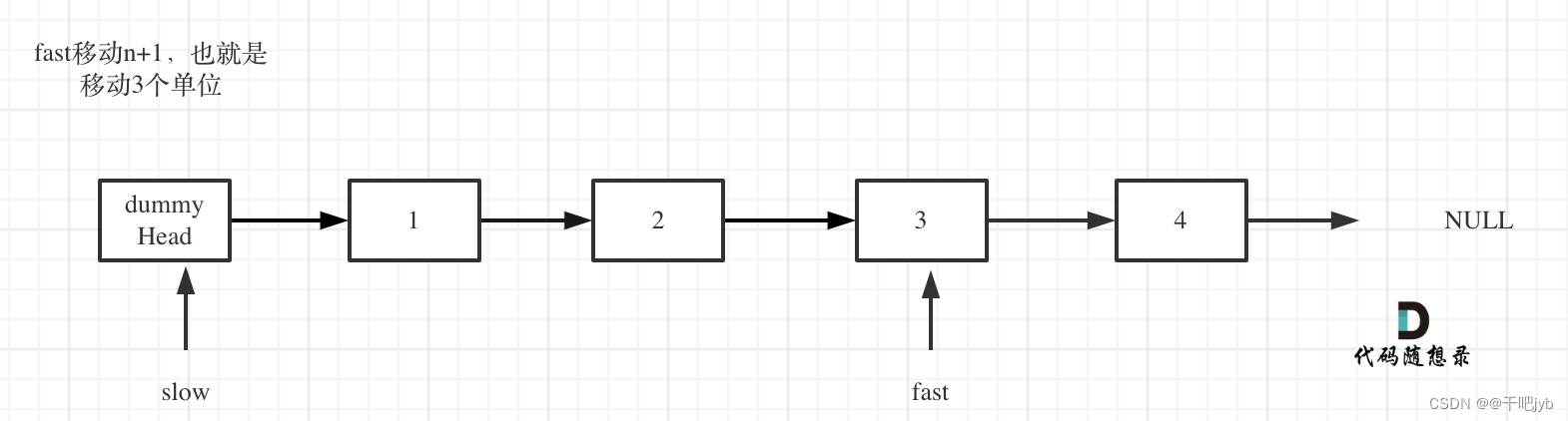
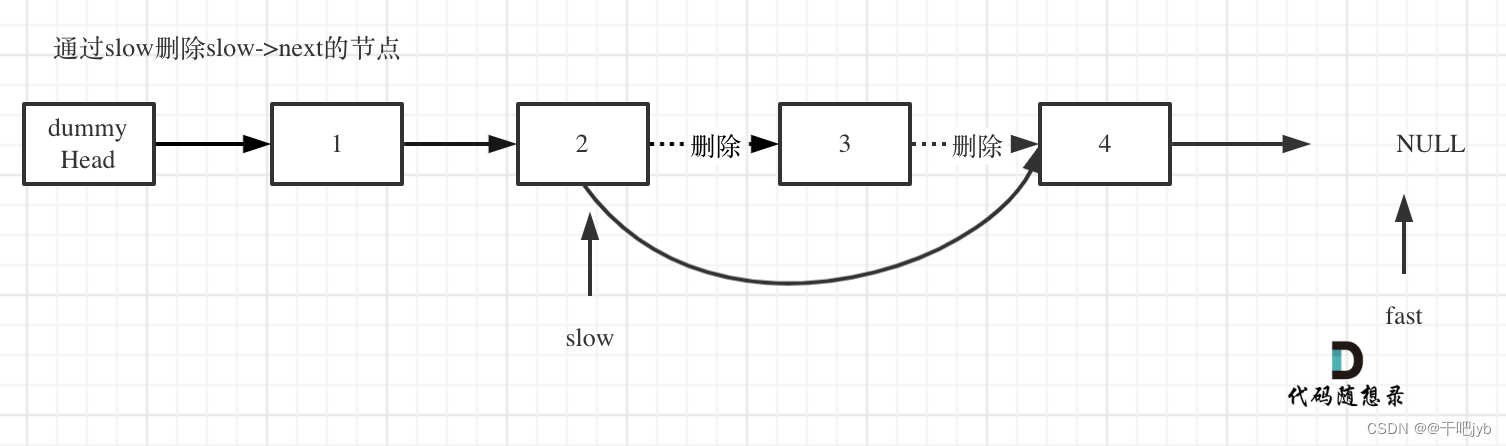
3删除slow指向的下一个节点,如图:
代码:
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
// 创建虚拟头节点
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head; // 虚拟头节点指向真实头节点
ListNode* slow = dummyHead; // 慢指针从虚拟头节点开始
ListNode* fast = dummyHead; // 快指针从虚拟头节点开始
while(n-- && fast != NULL) {
fast = fast->next; // 快指针先走n步
}
fast = fast->next; // 快指针再提前走一步,因为需要让慢指针指向删除节点的上一个节点
while (fast != NULL) {
fast = fast->next;
slow = slow->next; // 快慢指针同时向后移动,直到快指针到达链表末尾
}
slow->next = slow->next->next; // 删除第n个节点
// 释放被删除节点的内存,C++释放内存的逻辑
// ListNode *tmp = slow->next;
// slow->next = tmp->next;
// delete tmp;
return dummyHead->next; // 返回真实头节点
}
};2 栈思想:
我们也可以在遍历链表的同时将所有节点依次入栈。根据栈「先进后出」的原则,我们弹出栈的第 nnn 个节点就是需要删除的节点,并且目前栈顶的节点就是待删除节点的前驱节点。这样一来,删除操作就变得十分方便了。
代码:
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
// 创建虚拟头节点
ListNode* dummyhead = new ListNode(0, head);
stack<ListNode*> stk; // 使用栈来存储节点,以便找到倒数第n个节点的前一个节点
ListNode* cur = dummy; // 当前指针从虚拟头节点开始
while (cur) {
stk.push(cur); // 将当前节点压入栈中
cur = cur->next; // 移动到下一个节点
}
for (int i = 0; i < n; ++i) {
stk.pop(); // 弹出前n个节点
}
ListNode* prev = stk.top(); // 获取倒数第n个节点的前一个节点
prev->next = prev->next->next; // 删除第n个节点
ListNode* ans = dummy->next; // 获取真实头节点
delete dummy; // 释放虚拟头节点的内存
return ans; // 返回真实头节点
}
};2有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = "()" 输出:true
示例 2:
输入:s = "()[]{}"s
输出:true
示例 3:
输入:s = "(]" 输出:false
提示:
1 <= s.length <= 104s仅由括号'()[]{}'组成
栈思路:
先来分析一下 这里有三种不匹配的情况,
第一种情况,字符串里左方向的括号多余了 ,所以不匹配。
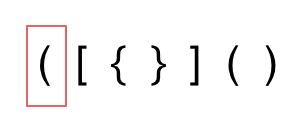
第二种情况,括号没有多余,但是 括号的类型没有匹配上。
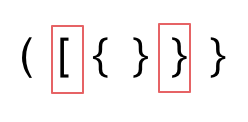
第三种情况,字符串里右方向的括号多余了,所以不匹配
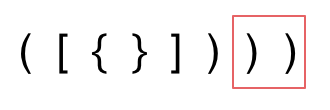
第一种情况:已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false
第二种情况:遍历字符串匹配的过程中,发现栈里没有要匹配的字符。所以return false
第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号return false
那么什么时候说明左括号和右括号全都匹配了呢,就是字符串遍历完之后,栈是空的,就说明全都匹配了。
代码:
class Solution {
public:
bool isValid(string s) {
if (s.size() % 2 != 0) return false; // 如果字符串长度为奇数,一定不符合要求
stack<char> st; // 使用栈来匹配括号
for (int i = 0; i < s.size(); i++) {
if (s[i] == '(') st.push(')'); // 左括号入栈对应的右括号
else if (s[i] == '{') st.push('}'); // 左括号入栈对应的右括号
else if (s[i] == '[') st.push(']'); // 左括号入栈对应的右括号
// 如果栈为空或者栈顶字符与当前字符不匹配,则返回false
// // 第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号 return false
// 第二种情况:遍历字符串匹配的过程中,发现栈里没有我们要匹配的字符。所以return false
else if (st.empty() || st.top() != s[i]) return false;
else st.pop(); // 匹配到一对括号,弹出栈顶元素
}
// 字符串遍历完成后,栈为空表示所有括号匹配成功,否则返回false
// 第一种情况:此时我们已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false,否则就return true
return st.empty();
}
};3合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
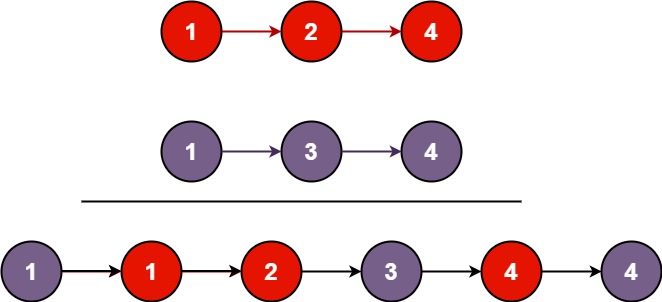
输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = [] 输出:[]
示例 3:
输入:l1 = [], l2 = [0] 输出:[0]
提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
- 递归思路方法:
- 首先处理边界情况,即其中一个链表为空时,直接返回另一个链表。
- 接着比较两个链表的头节点,将值较小的节点作为合并后链表的头节点。
- 然后递归地将较小节点的下一个节点与另一个链表进行合并,直到其中一个链表为空。
- 最后返回合并后的头节点即可。
代码:
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
if(list1 ==nullptr){ // 如果list1为空,直接返回list2
return list2;
}
if(list2==nullptr){ // 如果list2为空,直接返回list1
return list1;
}
if(list1->val <=list2->val){ // 如果list1的值小于等于list2的值
list1->next=mergeTwoLists(list1->next,list2); // 递归地将list1的下一个节点与list2合并
return list1; // 返回合并后的list1
}
// 如果list2的值小于list1的值或者list1为空,则将list1与list2的下一个节点进行合并
list2->next=mergeTwoLists(list1,list2->next);
return list2; // 返回合并后的list2
}
};4 寻找用户推荐人
表: Customer
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | name | varchar | | referee_id | int | +-------------+---------+ 在 SQL 中,id 是该表的主键列。 该表的每一行表示一个客户的 id、姓名以及推荐他们的客户的 id。
找出那些 没有被 id = 2 的客户 推荐 的客户的姓名。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入: Customer 表: +----+------+------------+ | id | name | referee_id | +----+------+------------+ | 1 | Will | null | | 2 | Jane | null | | 3 | Alex | 2 | | 4 | Bill | null | | 5 | Zack | 1 | | 6 | Mark | 2 | +----+------+------------+ 输出: +------+ | name | +------+ | Will | | Jane | | Bill | | Zack | +------+
思路
使用子查询:
- 使用子查询来查找目标用户的推荐人ID。
- 将子查询结果作为条件,从"Customer"表中选择推荐人的信息。
代码:
select name
from Customer
where referee_id is null or referee_id !=2;5. 2016年的投资
Insurance 表:
+-------------+-------+ | Column Name | Type | +-------------+-------+ | pid | int | | tiv_2015 | float | | tiv_2016 | float | | lat | float | | lon | float | +-------------+-------+ pid 是这张表的主键(具有唯一值的列)。 表中的每一行都包含一条保险信息,其中: pid 是投保人的投保编号。 tiv_2015 是该投保人在 2015 年的总投保金额,tiv_2016 是该投保人在 2016 年的总投保金额。 lat 是投保人所在城市的纬度。题目数据确保 lat 不为空。 lon 是投保人所在城市的经度。题目数据确保 lon 不为空。
编写解决方案报告 2016 年 (tiv_2016) 所有满足下述条件的投保人的投保金额之和:
- 他在 2015 年的投保额 (
tiv_2015) 至少跟一个其他投保人在 2015 年的投保额相同。 - 他所在的城市必须与其他投保人都不同(也就是说 (
lat, lon) 不能跟其他任何一个投保人完全相同)。
tiv_2016 四舍五入的 两位小数 。
查询结果格式如下例所示。
示例 1:
输入: Insurance 表: +-----+----------+----------+-----+-----+ | pid | tiv_2015 | tiv_2016 | lat | lon | +-----+----------+----------+-----+-----+ | 1 | 10 | 5 | 10 | 10 | | 2 | 20 | 20 | 20 | 20 | | 3 | 10 | 30 | 20 | 20 | | 4 | 10 | 40 | 40 | 40 | +-----+----------+----------+-----+-----+ 输出: +----------+ | tiv_2016 | +----------+ | 45.00 | +----------+ 解释: 表中的第一条记录和最后一条记录都满足两个条件。 tiv_2015 值为 10 与第三条和第四条记录相同,且其位置是唯一的。 第二条记录不符合任何一个条件。其 tiv_2015 与其他投保人不同,并且位置与第三条记录相同,这也导致了第三条记录不符合题目要求。 因此,结果是第一条记录和最后一条记录的 tiv_2016 之和,即 45 。
思路:
- 首先,我们需要找到满足条件一的投保人,也就是在 2015 年的投保额至少跟另一个投保人的投保额相同的投保人。
- 其次,我们需要找到满足条件二的投保人,也就是他们所在的城市必须与其他投保人都不同,即在纬度和经度上都没有完全相同的。
- 然后,我们将这两个条件组合起来,在满足这两个条件的投保人中,计算他们在 2016 年的投保金额之和,并对结果进行四舍五入,保留两位小数。
代码:
-- 查询满足条件的投保人的投保金额之和
select round(sum(tiv_2016), 2) as tiv_2016
from Insurance
-- 条件1: 他在 2015 年的投保额 (tiv_2015) 至少跟一个其他投保人在 2015 年的投保额相同
where tiv_2015 in (
-- 子查询1:找到在 2015 年有重复投保额的投保人
select tiv_2015
from Insurance
group by tiv_2015
having count(*) > 1
)
-- 条件2: 他所在的城市必须与其他投保人都不同(也就是说 (lat, lon) 不能跟其他任何一个投保人完全相同)
and (lat, lon) not in (
-- 子查询2:找到在 (lat, lon) 上有重复值的投保人
select lat, lon
from Insurance
group by lat, lon
having count(*) > 1
);6订单最多的客户
表: Orders
+-----------------+----------+ | Column Name | Type | +-----------------+----------+ | order_number | int | | customer_number | int | +-----------------+----------+ 在 SQL 中,Order_number是该表的主键。 此表包含关于订单ID和客户ID的信息。
查找下了 最多订单 的客户的 customer_number 。
测试用例生成后, 恰好有一个客户 比任何其他客户下了更多的订单。
查询结果格式如下所示。
示例 1:
输入: Orders 表: +--------------+-----------------+ | order_number | customer_number | +--------------+-----------------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | | 4 | 3 | +--------------+-----------------+ 输出: +-----------------+ | customer_number | +-----------------+ | 3 | +-----------------+ 解释: customer_number 为 '3' 的顾客有两个订单,比顾客 '1' 或者 '2' 都要多,因为他们只有一个订单。 所以结果是该顾客的 customer_number ,也就是 3 。
思路:
- 首先,我们需要按照客户编号将订单表进行分组,这样每个客户的订单都会被分到相应的组中。
- 然后,我们对每个客户的订单数量进行统计,使用
count(*)函数来计算每个客户的订单数量。 - 接下来,我们按照订单数量降序排序,这样订单数量最多的客户会排在前面。
- 最后,我们使用
limit 1语句来限制结果集只返回第一个结果,即订单数量最多的客户的客户编号。
代码:
select customer_number
from Orders
group by customer_number
order by count(*) desc
limit 1;