概念
分析数据
加入倒排索引之前,es在其主体上进行的操作:
字符过滤 转变为字符 / 文本切分单|多个分词 / 分词过滤转变分词 / 分词索引存储到索引
节点:node es实例
cluster.name 相同 集群,承担数据 负载压力
- 主节点:集群范围内all变更
- 数据节点:存储数据和对应倒排索引,默认都是,node.data设置
- 协调节点:node.master和node.data=false则为协调节点,响应请求,均衡负载
分片:水平分表 一个分片lucene实例
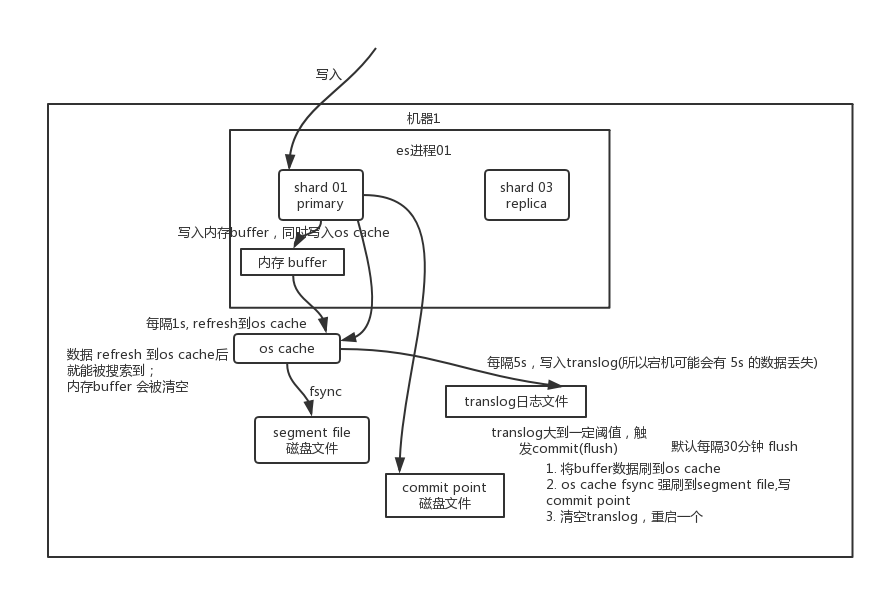
写入:
分段存:索引文件被分成段,不变性 本身是倒排索引,写入不可改
文件系统缓存
段写入到磁盘生成提交点,记录all提交后段信息的文件,只读
段在内存,只写的权限,不能被检索
新增:新增段就ok
删除:新增.del文件,列出被删段信息,可被查到 最终结果被返回前从结果集中移除
更新:删除+新增,旧的文件标记del文件,新版索引到新段
冲刷:refresh
新数据先写入内存
文件系统缓存:1s 内存达到一定量 触发刷新refresh 新段 存储到 文件缓存系统
磁盘:提交点 刷盘
冲刷 flush
内存分段提交到磁盘
translog 事务日志,记录每次es的操作
flush 事务被清空,段全量提交到磁盘
内存缓存满了/flush超过一定时间/事务日志达到阈值
段合并merge
提升搜索性能 均衡I/O CPU计算能力
分段总量保持可控范围内,每个搜索请求轮流检查每个段 段多检索慢
真正的删除文档
数据查询
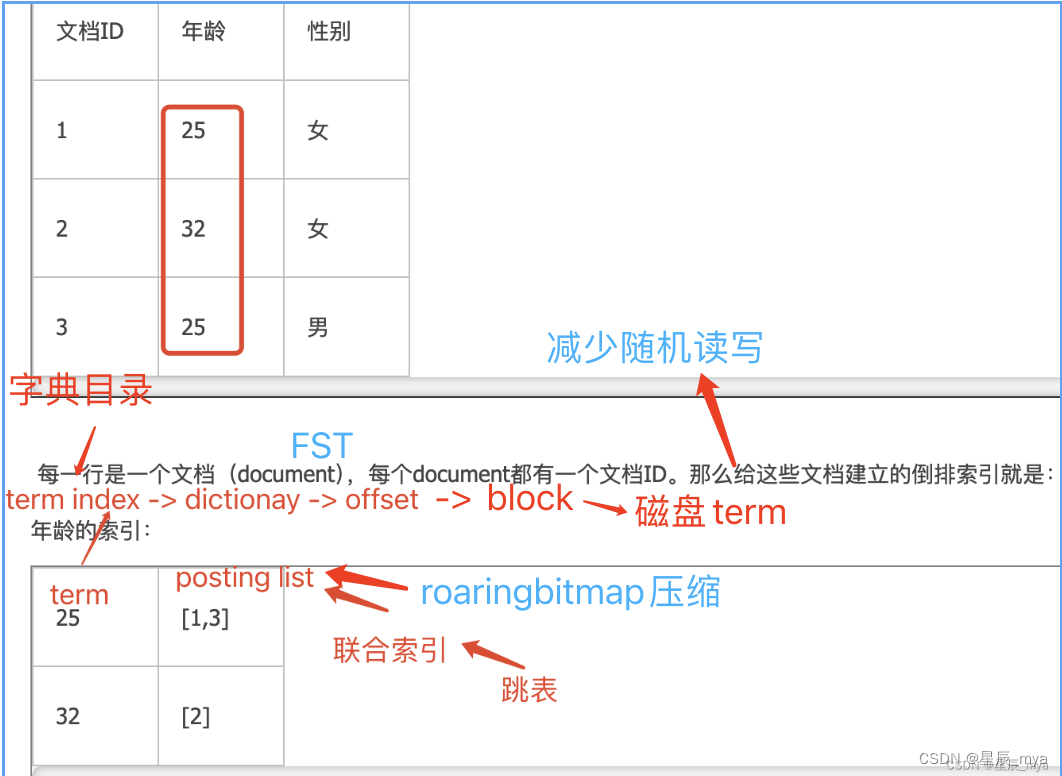
索引优化: 给term排序 二分查找 logN
term index:A开头的有哪些term 分别在哪页
含term的前缀,通过term index快速定位到term dictionary的某个offset 磁盘顺序查找
filter执行原理
query之前执行,过滤掉多的数据
倒排索引中查找搜索串, 文档id bitset 过滤 追踪query,近256个query中超过次数 缓存bitset,小的segemtn不需要缓存,提升性能
bitset由es自动更新
倒排索引
每个字段都有自己的倒排索引
联合索引:
skip list
跳表 同时遍历多个term的posting list 互相skip
跳表:多层有序链表组成 最低层level1含all元素,含指针
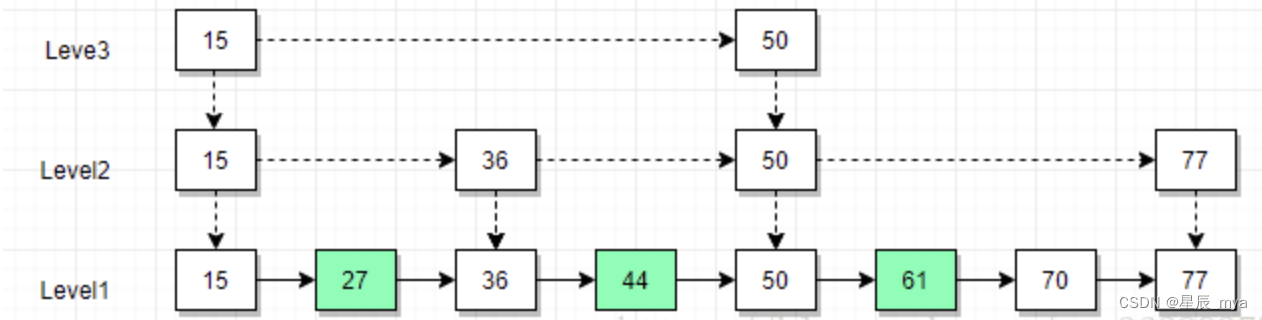
多数据量使用跳表 效果显著
少的使用bitset 压缩 按位与 得到最后的交集
使用bitset数据结构,多个term求出bitset,对bitset做AN操作
FST压缩
内存 存 more数据,内存FST压缩term index (内存里)
- 空间占用小,对词典中单词前缀和后缀重复利用 压缩了存储空间
- 查询块,O(len(str))
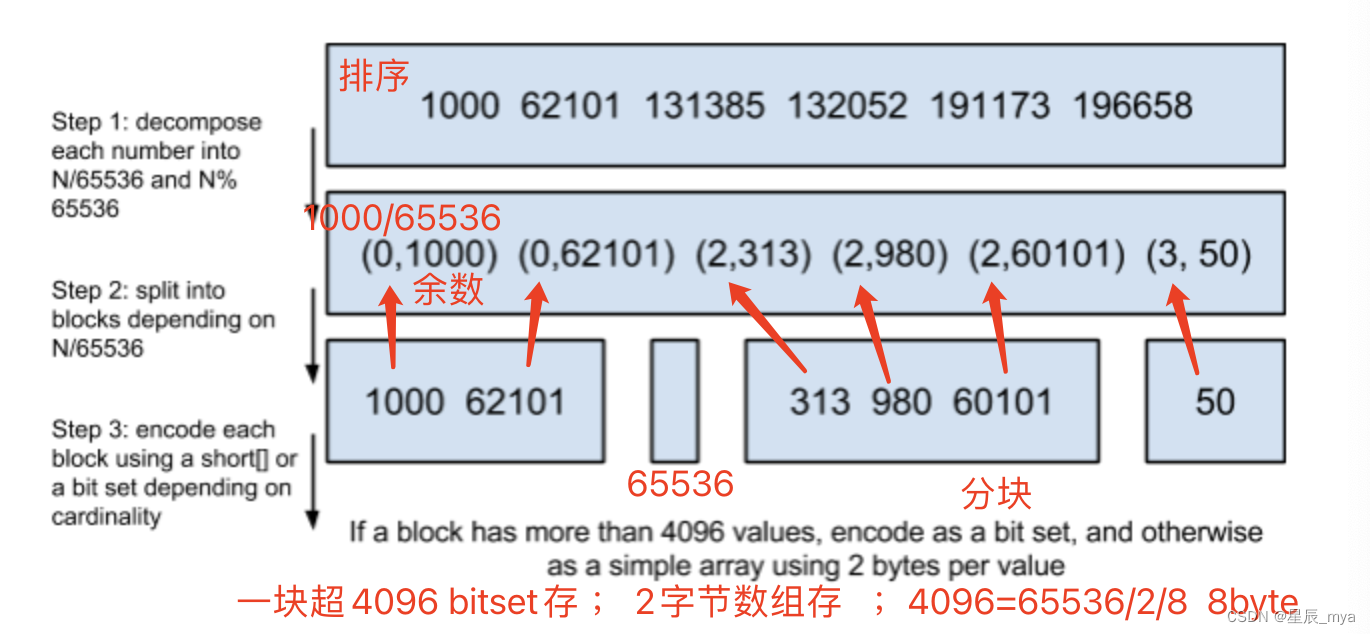
Roaring Bitmap
posting list存储文档id,id很大的时候压缩,排序和大数变小数
打分机制
得分:搜索词条的频率以及它有多常见(一个文档中)
TF-IDF,多个文档中越多越不相关,and you,and 出现的次数多不重要
master选举
多个node当选master,脑裂 破坏数据一致性,导致集群不可控
分布式 投票,master被多节点认可,保证只有一个
discovery.zen.minimum_master_nodes=sum(node)/2+1 多半
- 先根据clusterStateVersion比较,大 优先级高 相同 进入compareNodes,内部按节点的id比较
master候选等待多数节点join后才能成为master,保证master得到认可
raft算法,选举周期term 每周期只能投一票 再投就是下一周期,如最后两个节点都认为自己是master,两个term都收集到了多数派的选票,多数节点的term是较大的那个
集群
平衡算法 扩容 减容 导入数据
待续
这个网速 写了很多没保持
ES7基础篇-10-SpringBoot集成ES操作-CSDN博客
https://www.cnblogs.com/acestart/p/14884380.html
https://www.cnblogs.com/lxcmyf/p/14276974.html
elasticsearch高可用 原理 (图解+秒懂+史上最全)-CSDN博客
https://so.csdn.net/so/search?q=elasticsearch&t=blog&u=ma15732625261&urw= 之前17年18年写的水文 别看这么多 其实挺简单