OneFlow深度框架
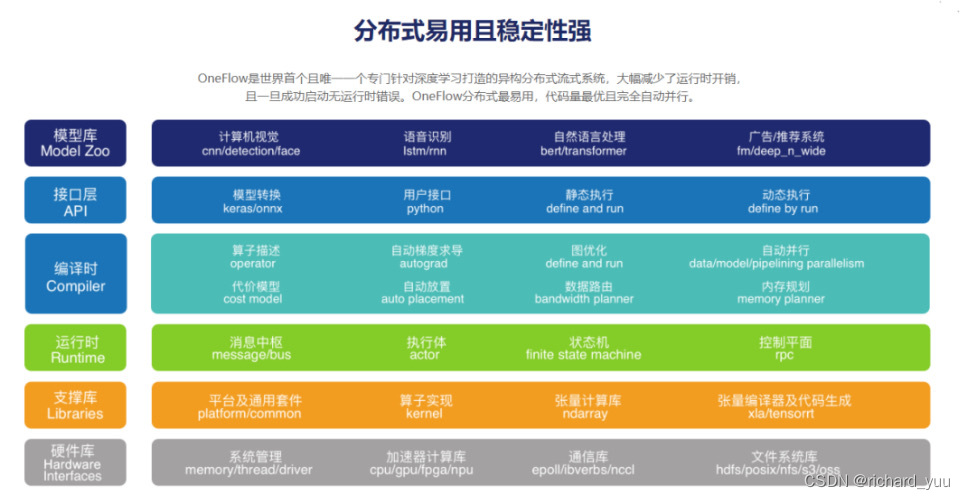
随着人工智能的浪潮席卷全球,深度学习作为其中的核心驱动力,正推动着各领域的技术革新。而在深度学习的实践中,一个高效、灵活且可扩展的深度学习框架对于模型的开发与训练至关重要。
一、理解OneFlow框架
OneFlow,作为新兴的开源深度学习框架,以其独特的设计理念和技术创新,正逐渐成为开发者与研究者的新宠。
OneFlow的出现,旨在解决大规模深度学习模型开发与部署过程中的复杂性,特别是在分布式训练场景下。它采用基于数据流图的编程模型,将复杂的深度学习任务抽象为直观的数据流图,通过高效的图编译和优化技术,实现模型计算的高效执行。
在实际应用中,数据流图的优势体现在其声明式的编程方式上。以图像识别任务为例,开发者只需定义数据输入、卷积层、池化层、全连接层等组件及其之间的连接关系,而无需关心底层计算细节。OneFlow会自动将模型转换为数据流图,并在底层进行高效的计算和优化。这种编程方式不仅简化了模型的开发过程,还使得模型更易于理解和调试。
二、分布式训练
除了数据流图执行引擎外,OneFlow还内置了强大的分布式训练能力。在分布式环境下,数据的并行处理、模型的并行计算以及流水线的并行执行是提升训练效率的关键。OneFlow通过内置多种并行策略,使得开发者能够轻松实现大规模分布式训练。
以自然语言处理任务为例,训练一个大型的语言模型需要处理海量的文本数据。在OneFlow中,开发者可以通过简单的配置,将数据分割到多个节点上进行并行处理,同时利用模型并行和流水线并行来加速模型的训练过程。这种无缝的分布式训练能力,极大地提升了训练效率和资源利用率,使得大型语言模型的训练变得更加可行。
三、编程能力
此外,OneFlow还提供了动态图与静态图混合编程的能力。动态图模式下,代码即刻执行,便于开发者在开发初期进行快速的迭代和调试。而在模型训练稳定后,开发者可以切换到静态图模式,经过编译优化后的模型能够获得更高的运行效率。这种混合编程范式兼顾了灵活性与性能,使得开发者能够根据不同的需求选择合适的编程模式。
四、其它
在硬件兼容性与性能优化方面,OneFlow也展现出了其强大的实力。它不仅支持CPU和GPU,还针对NVIDIA、AMD等厂商的最新GPU架构进行了深度优化。这使得OneFlow能够在各类硬件平台上发挥出色性能,为深度学习模型的训练提供了强大的硬件支持。
此外,OneFlow还集成了多种张量计算库,如cuDNN、MIOpen等,进一步提升了计算效率。这些计算库的集成使得OneFlow在进行大规模矩阵运算、卷积运算等复杂计算时能够发挥出更高的性能,从而加速了深度学习模型的训练过程。
尽管OneFlow相对较新,但其社区活跃度日益提升。官方文档详尽、用户问答与教程丰富,为开发者提供了良好的学习环境和支持。同时,OneFlow还与PyTorch、TensorFlow等主流框架实现了模型互转,为开发者提供了更多的选择和灵活性。此外,OneFlow还支持ONNX标准,这使得模型能够跨平台部署,为深度学习应用的推广提供了便利。
综上所述,OneFlow深度学习框架以其独特的设计理念和技术创新,为深度学习模型的开发与训练提供了高效、灵活且可扩展的解决方案。通过数据流图执行引擎、无缝分布式训练、动态图与静态图混合编程以及硬件兼容性与性能优化等技术亮点,OneFlow正成为深度学习领域的有力竞争者。随着其社区的不断发展和完善,相信OneFlow将在未来为更多的开发者带来便利和惊喜。