如何生成一个pd
import pandas as pd
df = pd.DataFrame([[1,2,3],[4,5,6]],index=['A','B'],columns=['C1','C2','C3'])
df
---------------------------------------------------------------------------
C1 C2 C3
A 1 2 3
B 4 5 6
df.T
---------------------------------------------------------------------------
A B
C1 1 4
C2 2 5
C3 3 6
df.values
---------------------------------------------------------------------------
array([[1, 2, 3],
[4, 5, 6]], dtype=int64)
df.index
---------------------------------------------------------------------------
Index(['A', 'B'], dtype='object')
df.columns
---------------------------------------------------------------------------
Index(['C1', 'C2', 'C3'], dtype='object')
df.shape
---------------------------------------------------------------------------
(3, 2)
#第一行
df.head(1)
---------------------------------------------------------------------------
C1 C2 C3
A 1 2 3
#最后一行
df.tail(1)
---------------------------------------------------------------------------
C1 C2 C3
B 4 5 6
#取出index列标识的所有值,比如这里取B列
df.loc['B']
---------------------------------------------------------------------------
C1 4
C2 5
C3 6
Name: B, dtype: int64
一、如何进行数据分析,我自己建了一个csv文件来解释数据长这样
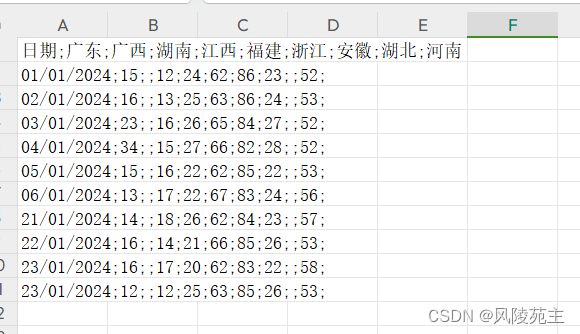
通过pd来获取数据
broken_df = pd.read_csv('./data.csv')
broken_df
得到的数据长这样,这样的数据没法正常看。

通过数据分析,我们发现是以“;”为数分隔的,
我们可以增加参数来处理
broken_df = pd.read_csv('./data.csv',sep=';', encoding='utf-8',parse_dates=['日期'],dayfirst=True,index_col='日期')
broken_df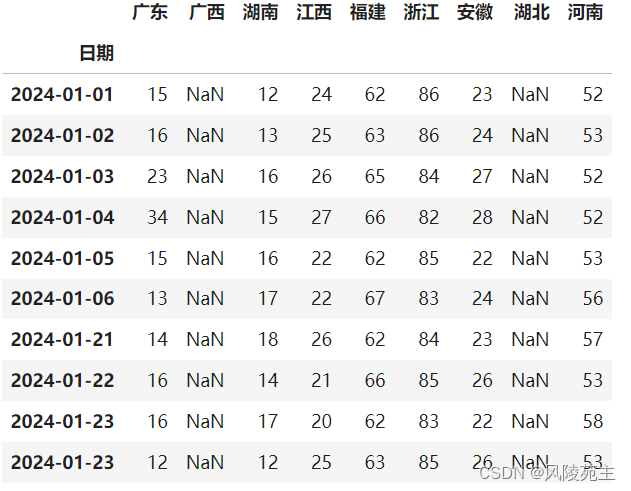
选择某一列--广东
broken_df = pd.read_csv('./data.csv',sep=';', encoding='utf-8',parse_dates=['日期'],dayfirst=True,index_col='日期')
broken_df['广东']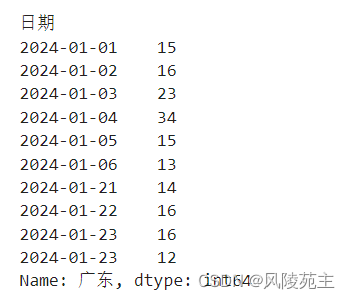
选择前三列
broken_df.head(3)
broken_df[:3]
#这两个都可以用
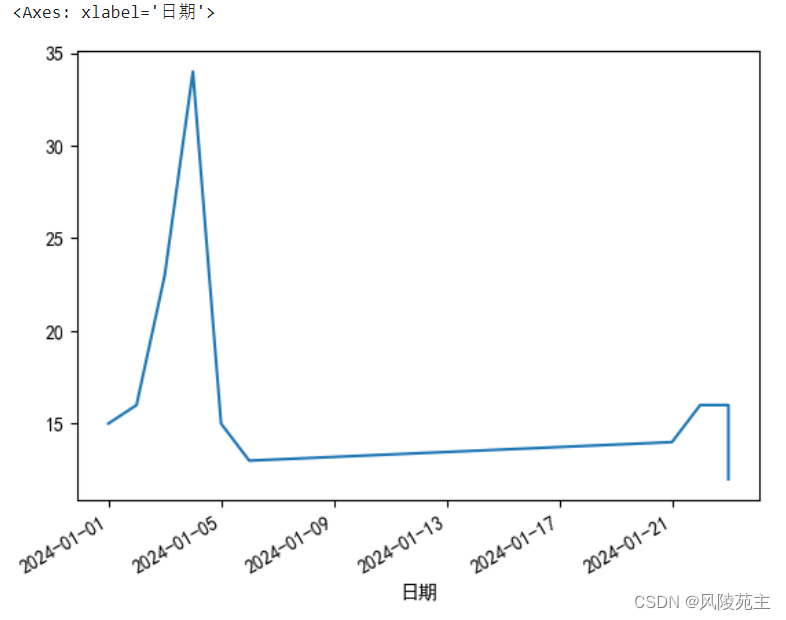
broken_df = pd.read_csv('./data.csv',sep=';', encoding='utf-8',parse_dates=['日期'],dayfirst=True,index_col='日期')
broken_df['广东'].plot()
#在使用中,你可能会遇到missing from current font错误警告问题,处理方式给程序增加看得懂的编码
plt.rcParams['font.sans-serif'] = ['SimHei']