前言
在Java中,序列化是指将java对象转换为字节流的过程,以便存储到文件、通过网络传输或在不同的Java虚拟机之间传递。
JDK自带的序列化
JDK 提供了用于序列化和反序列化对象的工具和类库,其中最核心的类是 java.io.Serializable 接口和 java.io.ObjectOutputStream、java.io.ObjectInputStream 类。静态字段和 transient 字段不会被序列化。
如何对对象进行序列化?
可以使用 ObjectOutputStream 类将对象序列化为字节流。ObjectOutputStream 类提供了 writeObject() 方法,用于将对象写入字节流。
如何反序列化对象?
可以使用 ObjectInputStream 类将字节流反序列化为对象。ObjectInputStream 类提供了 readObject() 方法,用于从字节流中读取对象。
JDK自带的序列化方式使用起来非常方便。只需让需要序列化的类实现Serializable接口即可。Serializable接口没有定义任何方法和属性,所以它只起到了标识的作用,表示这个类是可以被序列化的。
@Data
@AllArgsConstructor
public class Person implements Serializable {
private String name;
private int age;
}
序列化反序列化案例
来一个将java对象保存到本地例子:
public static void main(String[] args) throws IOException {
Person person = new Person("Tom", 32);
FileOutputStream fileOutputStream = new FileOutputStream(new File("D:/person.txt"));
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(person);
objectOutputStream.close();
fileOutputStream.close();
System.out.println("over");
}
字符串传输: 用Base64.getEncoder().encodeToString()转为字符串
public static void main(String[] args) throws IOException {
Person person = new Person("Tom", 32);
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(person);
byte[] byteArray = byteArrayOutputStream.toByteArray();
//Base64.getEncoder().encodeToString(byteArray) 将字节数组转换为 Base64 编码的字符串
//这样,我们可以将序列化后的对象以字符串的形式保存或传输。
//Base64 编码适用于需要在文本环境中传输数据的场景 而二进制传输适用于专用的二进制协议或需要直接传输字节流的场景。
String s = Base64.getEncoder().encodeToString(byteArray);
//处理结果 这里打印输出
System.out.println(s);
objectOutputStream.close();
System.out.println("over");
}
解释:ObjectOutputStream 需要一个输出流作为参数,以便将序列化后的对象写入到指定的目标(例如文件、网络连接等)。这个输出流可以是 FileOutputStream、ByteArrayOutputStream 或其他实现了 OutputStream 接口的类。通过传入不同的输出流,我们可以将序列化后的对象保存到不同的位置。
从本地文件中反序列化为java对象例子:
public static void main(String[] args) throws IOException, ClassNotFoundException {
FileInputStream fileInputStream = new FileInputStream(new File("D:/person.txt"));
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
Person person = (Person) objectInputStream.readObject();
System.out.println(person);
//结果:Person(name=Tom, age=32)
}
serialVersionUID作用
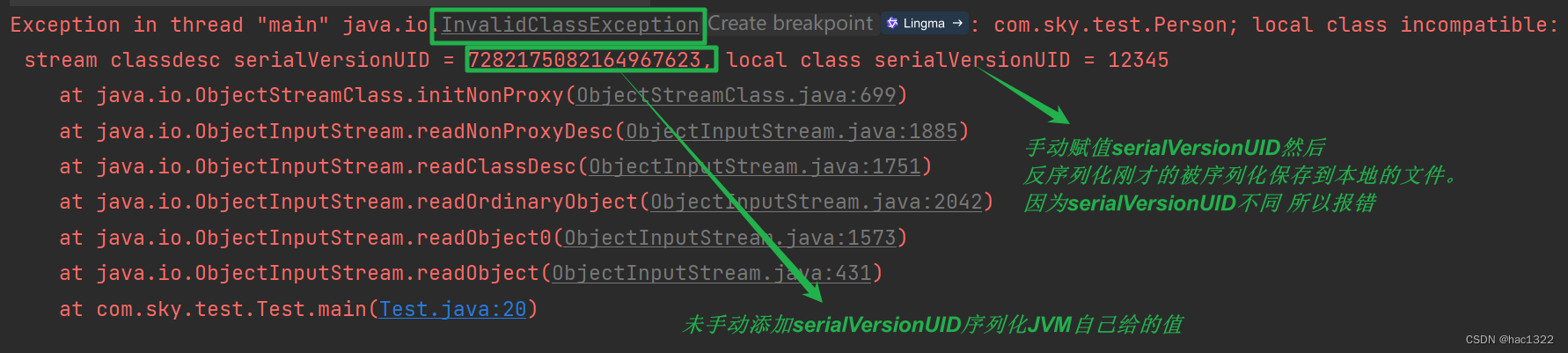
serialVersionUID在反序列化时,JVM需要知道所属的class文件。在序列化时,JVM会记录class文件的版本号,即serialVersionUID。该变量默认由JVM自动生成,也可以手动定义。反序列化时,JVM会按版本号找指定版本的class文件进行反序列化。如果class文件的版本号在序列化和反序列化时不一致,会导致反序列化失败。
@Data
@AllArgsConstructor
public class Person implements Serializable {
//手动设置
private static final long serialVersionUID = 12345L;
private String name;
private int age;
}
当你使用 ObjectOutputStream 将一个对象序列化时,Java 虚拟机会检查该类是否实现了 Serializable 接口,并查找类中是否定义了 serialVersionUID 字段。如果定义了 serialVersionUID 字段,则序列化时会将其值写入序列化数据中。
当你使用 ObjectInputStream 进行反序列化时,Java 虚拟机会检查序列化数据中的 serialVersionUID 值与正在加载的类的 serialVersionUID 值是否匹配。如果匹配,则可以成功反序列化对象;如果不匹配,则会抛出 InvalidClassException 异常,表示类的版本不兼容,反序列化失败。
缺点
安全性:由于序列化可以将对象转换为字节流,攻击者可以通过篡改序列化数据来进行恶意操作,比如注入恶意代码或者修改对象的字段值。
性能:JDK序列化会将对象的所有属性都转换为字节流,导致序列化后的字节流较大,占用存储空间较多。在网络传输中,大的序列化数据会影响系统的吞吐量。
通用性:JDK自带的序列化只支持Java语言实现的框架,无法在不同语言之间进行对象的序列化和反序列化。
替代方法
JSON序列化:JSON是一种轻量级的数据交换格式,支持多种编程语言。常用的JSON序列化库有Jackson、Gson(Google 提供的) 和Fastjson(阿里巴巴提供的)。
Protobuf(Protocol Buffers):Protobuf是Google开发的一种高效的二进制序列化格式,支持多语言。它生成的二进制数据较小,性能优越。
Kryo:这是一个小而快的Java序列化库,它比JDK自带的序列化更加快速和高效。
Hessian:这是一个基于二进制的轻量级远程调用协议,它支持跨语言的数据交换,并且序列化后的数据体积相对较小。
(这几种实现序列化方法网上教程很多,这里就不展开了)
觉得有用点个赞,谢谢