前言:
在C语言中,我们知道程序从我们所写的代码到可执行执行的过程中经历了以下过程
1.预处理
2.编译
3.汇编
4.链接
可以通过下图来理解
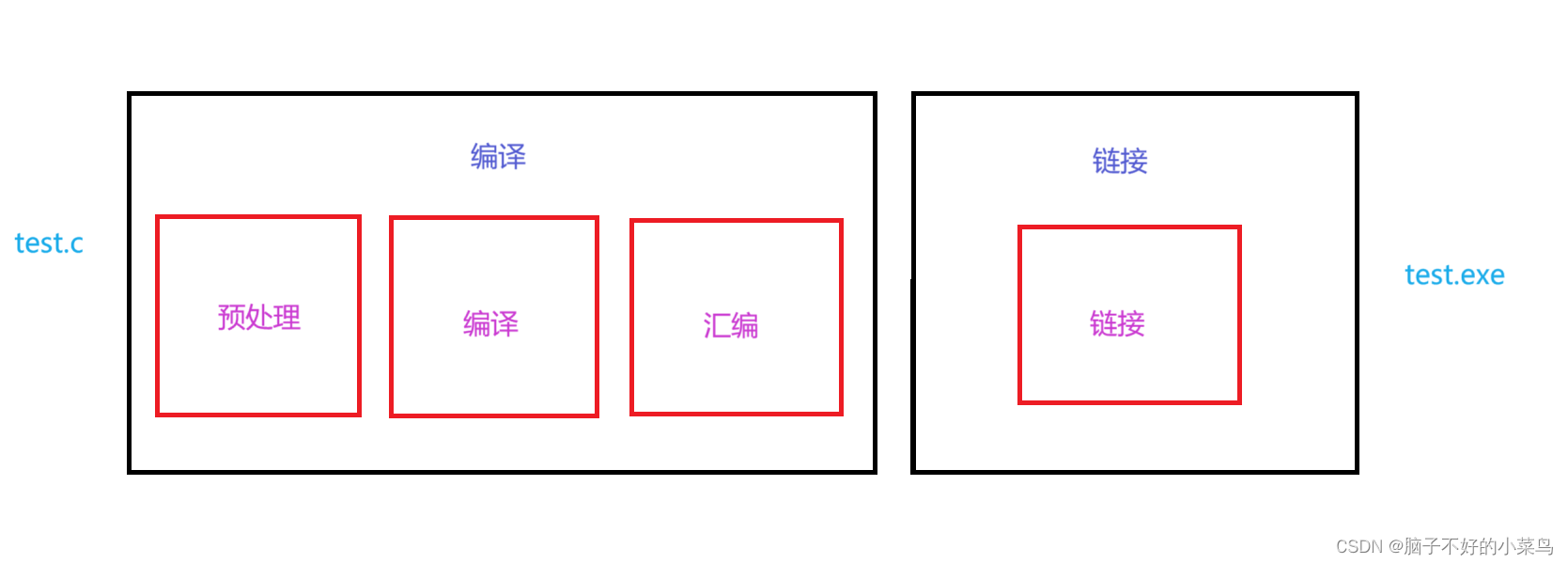
翻译过程
1.预处理
该过程主要进行以下操作:
(1)头文件的包含
(2)define定义符号的替换,删除定义的符号(也就是宏定义)
(3)注释的删除
(4)条件编译的处理(#ifdef, #else, #endif)
2.编译
(1)把C语言代码转化为汇编代码
3.汇编
(1)把汇编代码替换为机器指令(也可以说是机器指令,目标代码),形成符号表
(2)语法分析,此法分析,符号汇总,语义分析
4.链接
(1)合并段表
(2)符号表的合并和重定位
想知道程序的翻译环境和执行环境的详细过程,请移步:(暂未完成,敬请期待)
Linux下对其理解:
首先,我的codetest.c中的代码如下:
#include <stdio.h>
//宏定义
#define AC return
#define please 0
int main()
{
printf("hello Linux\n");
//注释部分
// printf("hello Linux1\n");
// printf("hello Linux2\n");
// printf("hello Linux3\n");
int* p = NULL;
printf("%d\n", sizeof(p));
//条件编译语句
#ifdef MAX
printf("MAX exist\n");
#else
printf("MAX cannot find\n");
#endif
//下面只是为了节目效果,请大家不要效仿,这是不好的编程习惯,我之前也从未这样子写过
AC please;
}
1.预处理
从那篇文章我们知道了预处理之后,我们的test.c会变成test.i文件
{
拓展:
要注意,这是在windows环境下,在Linux环境下并不以后缀区分文件类型,而是通过:ll 指令,会显示如下信息:

| 文件类型 | 文件权限 | 硬链接数 | 文件拥有者 | 文件所属组 | 文件大小(以字节为单位) | 文件创建时间或者最近更新使劲按 | 文件名 |
| - | rw-rw-r-- | 1 | xkjtx |
xkjtx | 627 | Apr 18 21:32 | codetest |
| d | rwxr-xr-x | 2 | xkjtx | xkjtx | 6 | Apr 13 19:42 | Desktop |
Linux下文件信息:
在Linux中,输入ll命令会显示文件和目录的详细信息。这些信息通常分为若干列,每列的含义如下:
文件类型:
第1个字符代表文件类型:
-:普通文件
d:目录
l:软链接(符号链接)
c:字符设备文件
b:块设备文件
s:本地套接字
p:命名管道(FIFO)
接下来的九个字符分为三组,每组三个字符,代表文件权限:
r:可读权限
w:可写权限
x:可执行权限
每组分别代表文件拥有者(user)、所属组(group)和其他用户(other)的权限。
硬链接数:
对于文件,这表示有多少个文件名指向该文件;对于目录,这表示该目录所含的子目录数(不包括.和..)。
文件拥有者:
显示文件的拥有者用户名。
文件所属组:
显示文件所属的用户组名称。
这个组存在的意义是:有时为了保护文件所属者的信息,文件只有自己可见,但这样子会有弊端:当文件所有者的同事或者上级想查看文件时,无法查看,只能打开other查看的权限,但是这样子所有人都可以看,而不只是上级和同事,因此设置了group(文件所属组)权限,设置了其他人可见,并保证了隐私
other:
不属于 文件拥有者 和 文件所属组 中的任何一者
}
因此当我们在Linux输入以下命令行:
其中:
-E:表示预处理
codetest.c:我们的代码所属文件
-o:理解为起别名
codetest.i:预处理后的文件名
gcc -E codetest.c -o codetest.i
// 代码文件名 预处理后的文件名在输入:ls后会发现列表中多了一个文件:codetest.i
![]()
我们再使用以下命令:
vim codetest.c进入codetest.c文件,再输入
:vs codetest.i使其分屏操作,我们平时也可以用这种方式对比两个源文件的不同之处(写题的人都懂这种操作有多么重要吧)
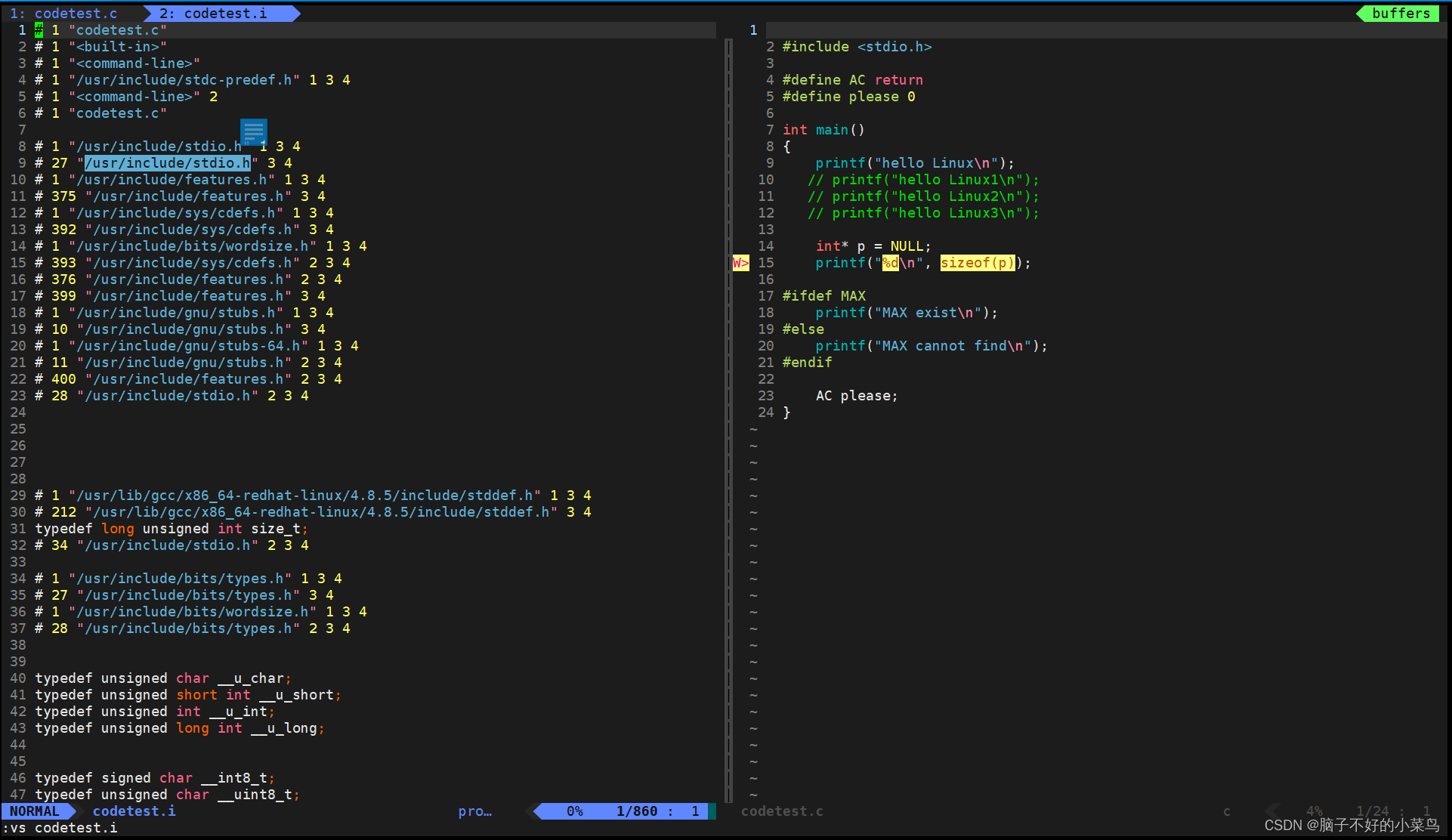
以下左半部分为codetest.i,右半部分为codetest.c
图一:注意左侧高亮部分,这是我们在codetest.c文件中对stdio.h的包含在预处理好的文件中的展示,其实codetest.i中前800多行都是包含了stdio.h文件里的内容,这也就是我们所说的预处理第一个步骤:头文件的包含
图二:
可以发现注释部分在codetest.i中消失了;
条件编译中,因为MAX我们没有在宏定义中定义,因此它不执行:printf("MAX exist\n");
而是执行: printf("MAX cannot find\n");
而codetest.c中的AC please;被替换为return 0;
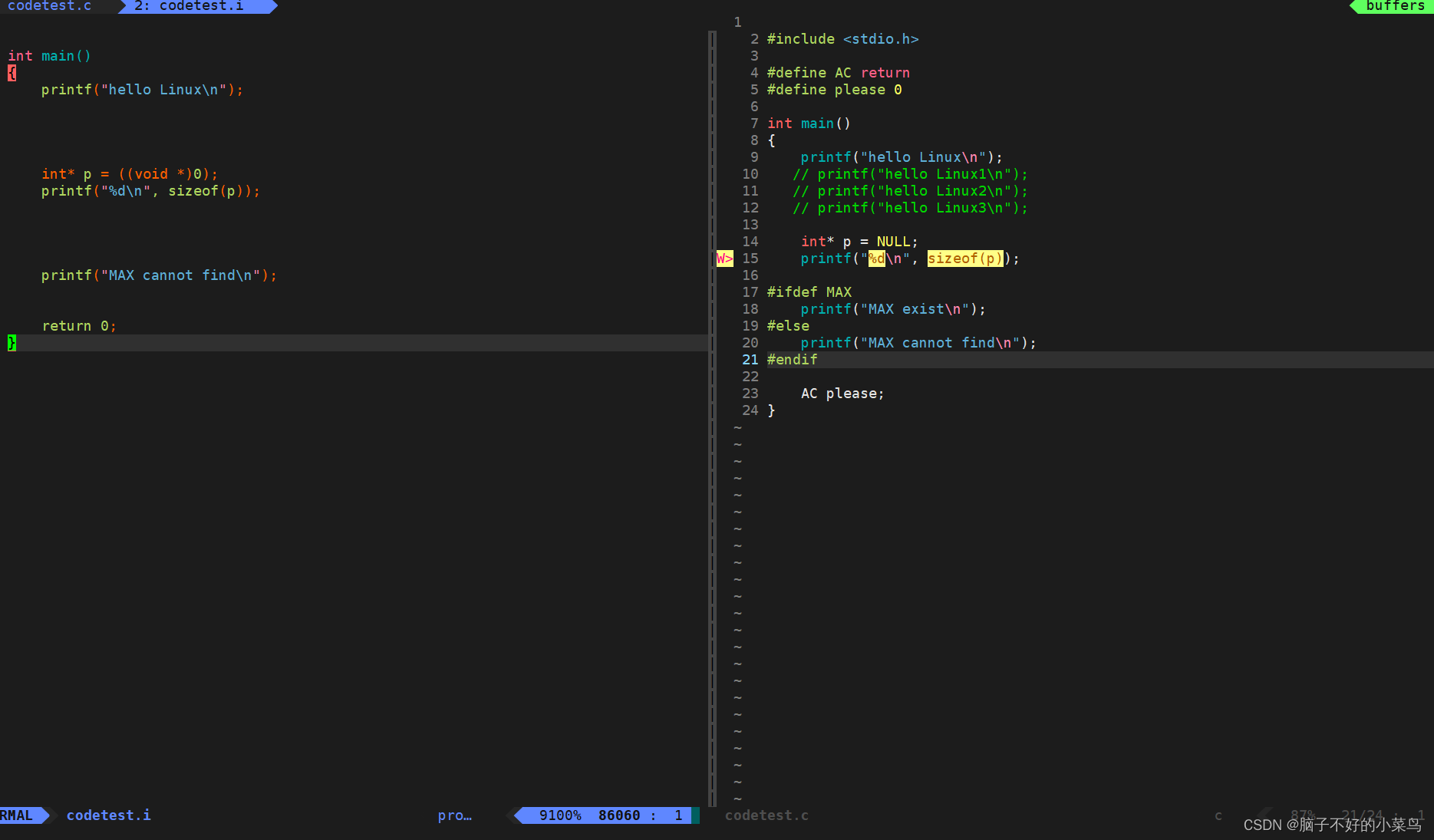
这里也就解释了 :
1.预处理
该过程主要进行以下操作:
(1)头文件的包含{codetest.i中前800多行都是包含了stdio.h文件里的内容}
(2)define定义符号的替换,删除定义的符号(也就是宏定义)
(3)注释的删除{注释部分在codetest.i中消失了;}
(4)条件编译的处理(#ifdef, #else, #endif)
{执行: printf("MAX cannot find\n");}
2.编译
从那篇文章我们知道了编译之后,我们的test.i会变成test.s文件
接下来,我们在Linux的命令行中输入:
gcc -S codetest.i -o codetest.s
//代码文件名(写成codetest.c也行,只是要再次预处理) 编译后的文件名其中:
-S:表示编译
codetest.i:我们的代码所属文件(写成codetest.c也行,只是要再次预处理)
-o:理解为起别名
codetest.s:生成的编译后的文件名
再次输入:ls,就会发现多了个codetest.s文件
![]()
使用以下命令:
vim codetest.s就会出现以下样子
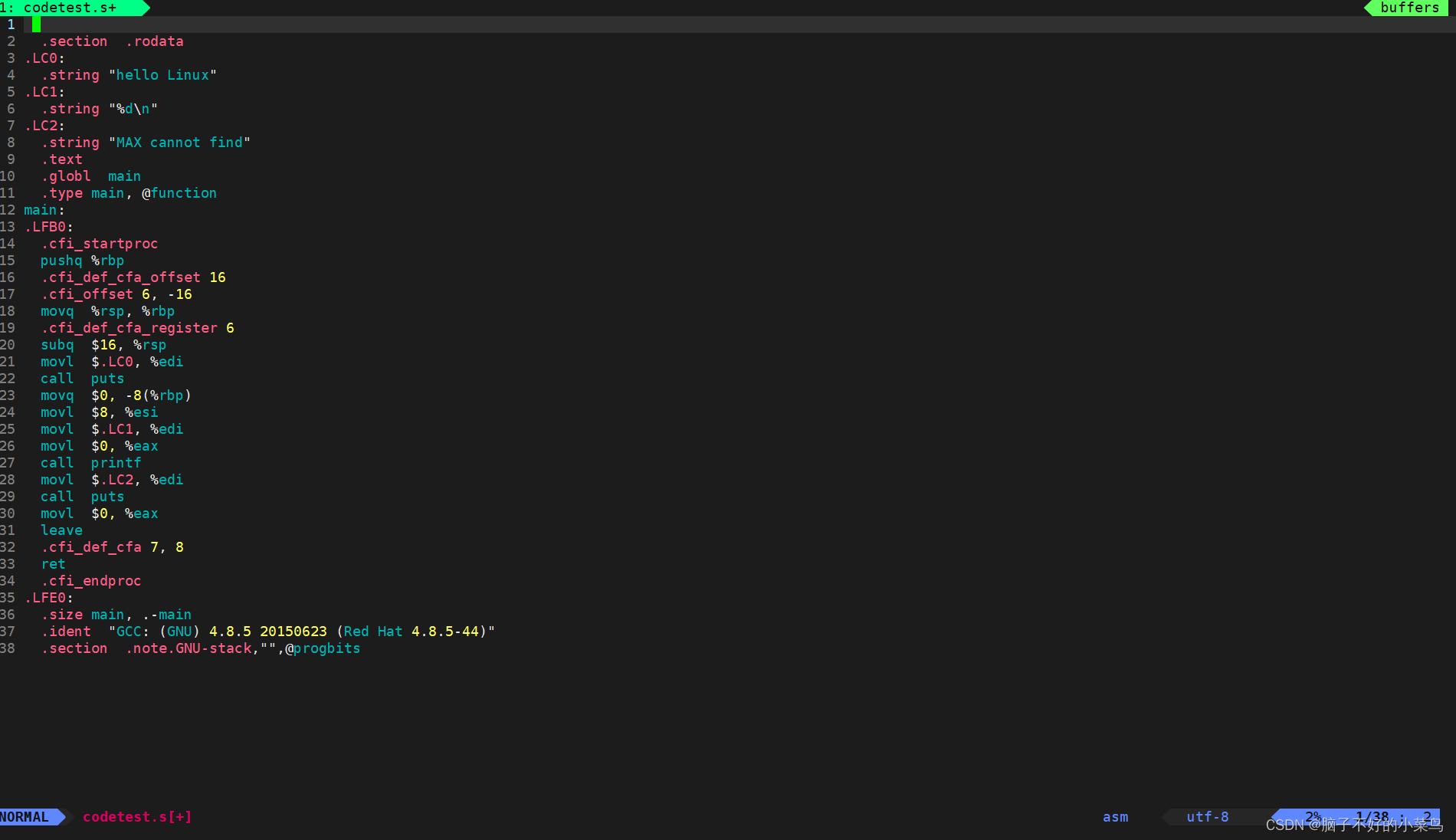
包括了movl这样的注记符,还有操作数,寄存器相关信息
这就是汇编代码,这也解释了:
2.编译
(1)把C语言代码转化为汇编代码
3.汇编
从那篇文章我们知道了汇编之后,我们的codetest.s会变成codetest.o文件
接下来,我们在Linux的命令行中输入:
gcc -c codetest.s -o codetest.o
//代码文件名(写成codetest.c,codetest.i,codetest.s也行,只是要再次进行之前的操作) 编译后的文件名其中:
-c:表示编译(注意是小写)
codetest.s:我们的代码所属文件
-o:理解为起别名
codetest.o:编译后的文件名
再次输入:ls,就会发现多了个codetest.o文件
![]()
再次进行以下操作:
使用以下命令:
vim codetest.o就会出现以下样子 
这就是二进制,这也解释了:
3.汇编
(1)把汇编代码替换为机器指令(就是2进制指令)
4.链接
这一步不用像之前一样写-E,-S,-c这样子的命令,因为gcc自带了链接功能,直接输入以下代码就好:
gcc codetest.o -o codetest
// 代码文件名 生成的可执行文件名输入ls,会发现多了个绿色的codetest文件
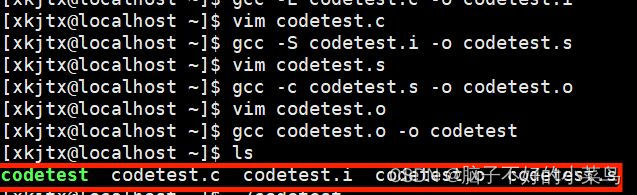
再次输入
./codetest执行codetest.c代码,输出以下部分
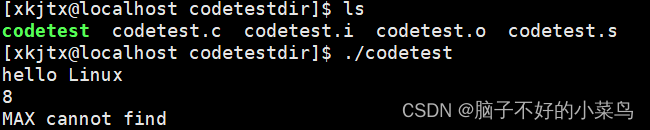
以上就是通过Linux查看C语言翻译环境的所有过程啦~~(预处理,编译,汇编,链接)
以下是识记小部分,
* 你是不是被什么-E,-S,-c指令搞蒙了?去掉-看看,是不是就算ESc啊?键盘左上角的键哦 *
* 是不是被.i .s .o 搞懵了?如果你装的是虚拟机,你就会发现iso就是你装在虚拟机上的镜像文件的后缀名哦,注意,这不是ios操作系统的ios,是iso,不要搞错了 ~~~ *
完结撒花~~哦吼吼~~
喜欢的给俺点点赞哦~
