Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision 论文阅读
Multimodal Violence Detection under Weak
Supervision 论文阅读)
文章信息:

原文链接:https://arxiv.org/abs/2007.04687
源码:https://roc-ng.github.io/XD-Violence/
发表于:ECCV 2020
Abstract
暴力检测在计算机视觉领域已经研究多年。然而,先前的工作要么是表面的,例如对短视频剪辑进行分类,并且只针对单一场景;要么是不足的,例如只使用单一模态,或者基于手工特征的多模态。为了解决这个问题,本文首先发布了一个名为XD-Violence的大规模多场景数据集,总时长为217小时,包含4754个未剪辑的视频,并带有音频信号和弱标签。然后,我们提出了一个神经网络,包含三个并行分支,用于捕获视频片段之间的不同关系并集成特征。其中,整体分支使用相似性先验捕获长距离依赖关系,局部分支使用接近先验捕获局部位置关系,得分分支动态捕获预测得分的接近程度。此外,我们的方法还包括一个逼近器,以满足在线检测的需求。我们的方法在我们发布的数据集和其他现有基准数据集上均优于其他最先进的方法。此外,大量的实验结果还显示了多模态(音频视觉)输入和建模关系的积极效果。
1 Introduction
每个人都希望过上和平的生活,我们的责任是维护和平,反对暴力。多年来,视频中的暴力检测已经成为计算机视觉领域的研究重点[25,15,4,24,35,36,13,30]。然而,由于应用有限且具有挑战性,与过去几十年中其他流行任务(例如视频分类[42]、动作识别[11]和时态动作检测[12])相比,这个特定任务受到的关注要少得多。随着近年来视频技术的进步,暴力检测的应用范围越来越广泛。例如,暴力检测不仅用于现实世界场景,如智能监控,还用于互联网,如视频内容审核(VCR)。暴力检测旨在以最小的人力资源成本及时定位暴力事件的开始和结束。
暴力检测的最早任务可以被视为视频分类[25,15]。在这种情况下,大多数方法假设视频已经经过了精修,其中暴力事件几乎持续了整个视频。然而,这些解决方案将范围限制在短视频片段上,并且不能推广到在未经修剪的视频中定位暴力事件,因此在实践中的应用受到了限制。解决暴力检测问题的一个小步骤是开发算法来专注于未经修剪的视频。例如,在MediaEval上的暴力场景检测(VSD)任务[4]和打斗检测器[30]。然而,为视频分配帧级别的标注是一项耗时的程序,这与构建大规模数据集是相悖的。
最近,一些研究[36,51]集中在弱监督暴力检测上,其中训练集中只提供视频级别的标签。与标注帧级别标签相比,分配视频级别标签更省力。因此,形成大规模的未经修剪视频数据集并训练一个数据驱动的、实用的系统不再是一个困难的挑战。在本文中,我们的目标是研究弱监督暴力检测。
此外,我们利用多模态线索来解决暴力检测问题,即将视觉和音频信息结合起来。与单模态输入相比,多模态输入对暴力检测有益。在大多数情况下,视觉线索可以准确地区分和定位事件。但有时,视觉信号无效,而音频信号可以分离视觉上模糊的事件。例如,在伴随爆炸声的剧烈摇晃的视频中,视觉信号很难弄清楚发生了什么,而在这种情况下,音频信号是主要的区分因素。因此,音频视觉融合可以充分利用互补信息,并成为计算机视觉和语音识别社区的一个广泛趋势。我们当然不是第一个尝试利用多模态信号来检测暴力的人,以前已经有过多模态暴力检测的先例,如[49,22,7,29]。然而,上述方法存在一些缺点,例如依赖小规模数据集、使用主观的手工特征和单一场景,这表明一个具有高泛化性的实用系统仍处于萌芽阶段。与这些方法不同的是,我们的目标是在大规模数据上设计一个可靠的基于神经网络的算法。
为了支持利用多模态信息(视觉和音频)在弱监督视角下检测暴力事件的研究,我们首先发布了一个包含4754个未修剪视频的大规模视频暴力数据集。与以前的数据集[25,15,4,36]不同,我们的数据集具有音频信号,并且是从电影和野外场景中收集而来的。有了这个数据集,我们将弱监督的暴力检测视为一个多示例学习(MIL)任务;也就是说,一个视频被看作是一个包,其中包含了几个实例(片段),通过包级别的标签来学习实例级别的注释。基于这一点,我们尝试学习更强大的表示以弥补弱标签。因此,我们提出了一个全局和局部网络(HL-Net),它明确利用片段之间的关系,并基于这些关系学习强大的表示,其中全局分支通过片段的相似性先验捕捉长距离依赖关系,局部分支模拟局部邻域内的短距离交互。此外,我们引入了一个全局和局部提示(HLC)逼近器,用于在线暴力检测,因为HL-Net需要整个视频来计算片段之间的关系。HLC逼近器仅处理局部邻域,并通过HL-Net引导的精确预测学习精确的预测。更好的是,HLC逼近器还带来了一个动态分数分支,与全局分支和局部分支并行,它通过所有特征的加权和计算位置上的响应,权重取决于预测分数。
综上所述,本文的贡献有三点:
- 我们发布了一个名为 XD-Violence 的音视频暴力数据集,包含 4754 个未修剪的视频,涵盖了六种常见的暴力类型。据我们所知,XD-Violence 是迄今为止规模最大的暴力数据集,总时长达 217 小时。与以前的数据集不同,XD-Violence 的视频是从多种场景中获取的,例如电影和YouTube。
- 我们引入了 HL-Net 来同时捕捉长距离关系和本地距离关系,其中这两种关系分别基于相似性先验和接近性先验。此外,我们还提出了一个用于在线检测的 HLC 近似器。基于此,我们使用一个分数分支动态地获取额外的整体关系。
- 我们进行了大量实验来验证我们提出的方法的有效性,结果表明我们的方法在两个基准测试数据集,即 XD-Violence(我们的数据集)和 UCF-Crime 上明显优于现有的基准方法。此外,实验结果还表明,与单模态相比,多模态信息具有明显的优势。
2 Related Work
Violence detection.在过去的几年中,许多研究人员提出了不同的暴力检测方法。例如,Bermejo等人[25]发布了两个知名的打斗数据集。Gao等人[15]提出了暴力流描述符来检测拥挤视频中的暴力事件。Mohammadi等人[24]提出了一种基于新行为启发式方法的方法来对暴力和非暴力视频进行分类。大多数先前的工作利用手工设计的特征来在小规模数据集上检测暴力事件。常见的特征包括尺度不变特征变换(SIFT)、时空兴趣点(STIP)、方向梯度直方图(HOG)、方向光流直方图(HOF)、运动强度等等。
随着深度卷积神经网络(CNN)的兴起,许多工作都致力于设计有效的深度卷积神经网络用于暴力检测。例如,Sudhakaran和Lanz[35]使用了卷积长短期记忆(LSTM)网络来识别暴力视频。类似地,Hanson等人[13]构建了一个双向卷积LSTM架构用于视频中的暴力检测。Peixoto等人[28]使用了两个深度神经网络框架来学习不同场景下的时空信息,然后通过训练一个浅层神经网络来描述暴力来整合它们。最近,一项有趣的研究[34]提出了使用散射网络混合深度学习网络进行无人机监控视频中的暴力检测。
有几种尝试使用多模态或音频来检测暴力的方法[49,22,7,29,8,9]。据我们所知,绝大多数方法使用手工特征来提取音频信息,例如,频谱图、能量熵、音频能量、色度、梅尔频率倒谱系数(MFCC)、过零率(ZCR)、音高等。手工特征易于提取,但是低级且不够健壮。与它们不同,我们的方法使用基于CNN的模型来提取高级特征。
Relation networks.图神经网络(GCNs)[20,39]已被许多工作应用于图模型中,以建模不同节点之间的关系并学习计算机视觉中的强大表示。例如,GCN被用于时间动作定位[50]、视频分类[37,41]、异常检测[51]、基于骨架的动作识别[33,45]、点云语义分割[21]、图像字幕生成[46]等领域。除了GCN,用于学习和推理视频帧之间时间依赖关系的时间关系网络[52]也被提出用于解决视频分类问题。最近,自注意力网络[40,47,5,18]已成功应用于视觉问题中。注意力操作可以通过聚合一组元素的信息来影响单个元素,其中聚合权重是自动学习的。
3 XD-Violence Dataset
3.1 Selecting Violence Categories
世界卫生组织(WHO)将暴力定义为“故意使用身体力量或权力,威胁或实际行使,针对自己、他人或针对群体或社区,其结果或可能导致伤害、死亡、心理伤害、恶化或剥夺”。由于暴力具有多重方面,即使限制在身体暴力范围内,也从未提出过一种普遍且足够通用的暴力事件定义。然而,确立清晰的暴力定义是一个关键问题,因为人类标注者可以依靠地面真实参考来减少歧义。为了缓解这个问题,我们考虑了六种身体暴力类别,即虐待、车祸、爆炸、打斗、暴乱和枪击。我们考虑这些暴力事件,是因为它们有明确的定义、频繁发生、广泛使用,并且对安全产生不良影响。
3.2 Collection and Annotation
Video collection.先前的暴力数据集要么来自电影,要么来自野外场景,几乎没有数据集同时来自两者。与它们不同,我们的数据集既来自电影,也来自 YouTube(野外场景)。总共有91部电影,其中暴力电影用于收集暴力和非暴力事件,而非暴力电影仅用于收集非暴力事件。我们还通过 YouTube 收集了野外视频。我们使用文本搜索查询搜索并下载了大量的视频候选项。为了防止暴力检测系统根据场景背景而不是事件发生来区分暴力,我们特别收集了大量背景与暴力视频一致的非暴力视频。经过数月的精心努力,我们完成了一个具有视频级标签的数据集。每个类别的一些示例视频如图1所示。更多细节请参阅补充材料。

Video annotation.
我们的数据集共有4754个视频,其中包括2405个暴力视频和2349个非暴力视频。我们将其分为两部分:包含3954个视频的训练集和包含800个视频的测试集,其中测试集包括500个暴力视频和300个非暴力视频。为了评估暴力检测方法的性能,我们需要对测试视频进行帧级别(时间)注释。具体来说,对于测试集中的每个暴力视频,我们标记暴力事件的开始和结束帧。与[36]类似,我们还将同一视频分配给多个注释者,以标记每个暴力事件的时间范围,并对不同注释者的注释进行平均,使最终的时间注释更加精确。训练集和测试集都包含视频中各种暴力事件的各种时间位置。
3.3 Dataset Statistics
多场景包括但不限于以下来源:电影、卡通、体育、游戏、音乐、健身、新闻、现场直播、闭路电视摄像头捕捉、手持摄像头捕捉、汽车行车记录仪捕捉等(其中一些可能重叠)。由于暴力事件的共同发生,我们还为每个暴力视频分配了多个暴力标签(1≤#标签≤3)。每个视频的标签顺序基于视频中不同暴力事件的重要性。暴力视频的标签数量分布如图2所示。此外,我们的数据集由未修剪的视频组成,因此,我们以视频长度的形式展示了视频的分布,如图3(a)所示。我们还在图3(b)中展示了每个测试视频中暴力的百分比。

Fig. 2. 数据集统计。(a) 按照多标签分类的每个类别视频数量的分布。(b) 按照第一个标签分类的每个类别视频数量的分布。
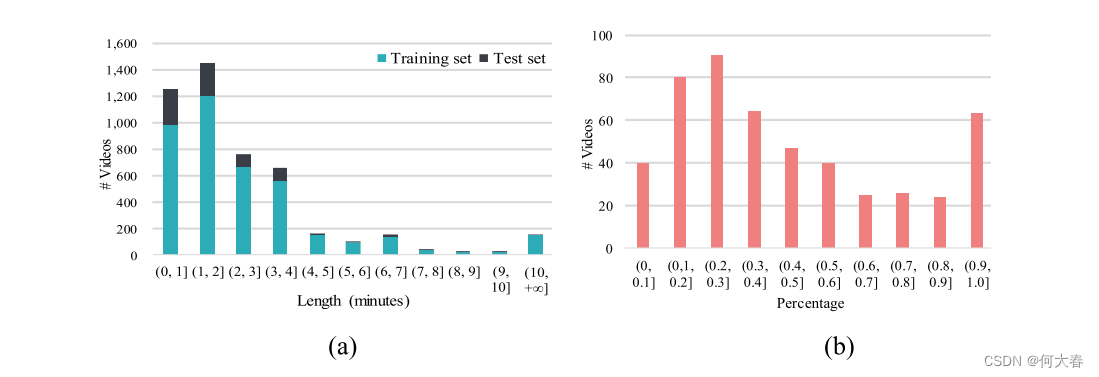
Fig. 3. 数据集统计。(a) 按照长度(分钟)分类的视频分布。(b) 测试集中暴力视频按照每个视频中暴力的百分比分布。
3.4 Dataset Comparisons
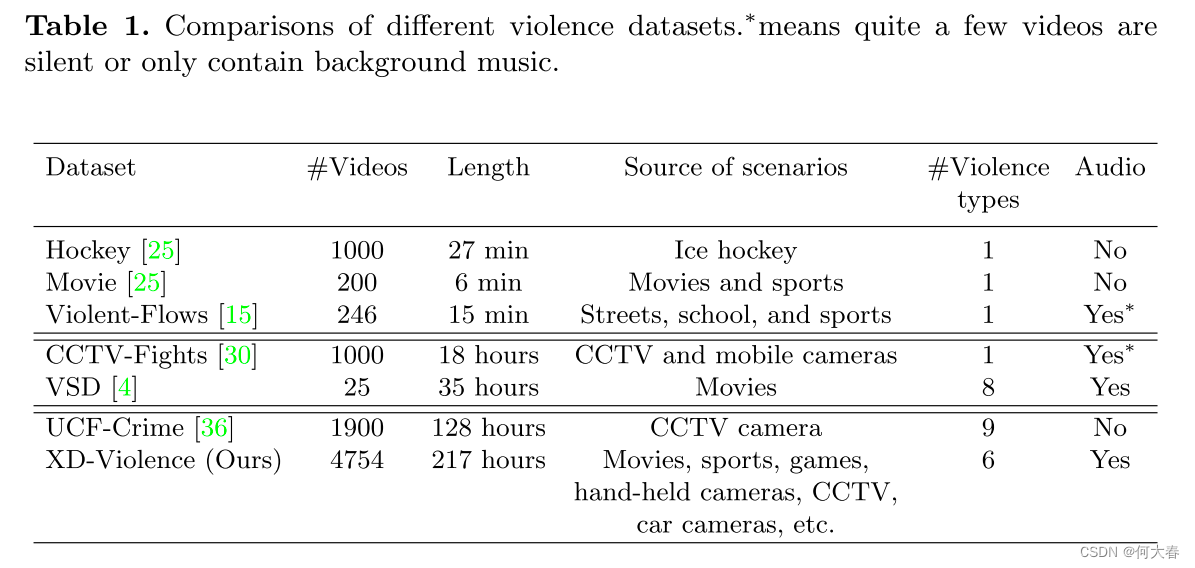
为突出我们数据集的特点,我们将其与其他广泛使用的暴力检测数据集进行了比较。这些数据集可以分为三种类型:小规模、中等规模和大规模,其中Hockey[25]、Movie[25]和Violent-Flows[15]属于小规模,VSD[4]和CCTV-Fights[30]属于中等规模,剩下的UCF-Crime[36]是大规模。表1比较了这些数据集的几个特征。我们的数据集是迄今为止最大的数据集,其视频数量是小型数据集总数的300多倍,中型数据集总数的4倍,几乎是UCF-Crime数据集的2倍。此外,先前数据集中场景的变化也很有限,相比之下,我们的数据集涵盖了各种各样的场景。此外,Hockey、Movie、Violent-Flows和CCTV-Fights仅用于战斗检测。有趣的是,尽管Violent-Flows和CCTV-Fights包含音频信号,实际上有相当多的视频是无声的或只包含背景音乐,这对于训练以多模态输入为输入的检测方法是无效的,甚至是有害的。UCF-Crime数据集用于在监控视频中检测暴力,但缺少音频。
总的来说,我们的数据集具有三个优点:
1)大规模,有利于训练暴力检测的通用方法;
2)场景多样性,使得暴力检测方法能够积极应对复杂多样的环境,更加稳健;
3)包含音视频信号,使算法能够利用多模态信息,更加自信。
4 Methodology
4.1 Multimodal Fusion
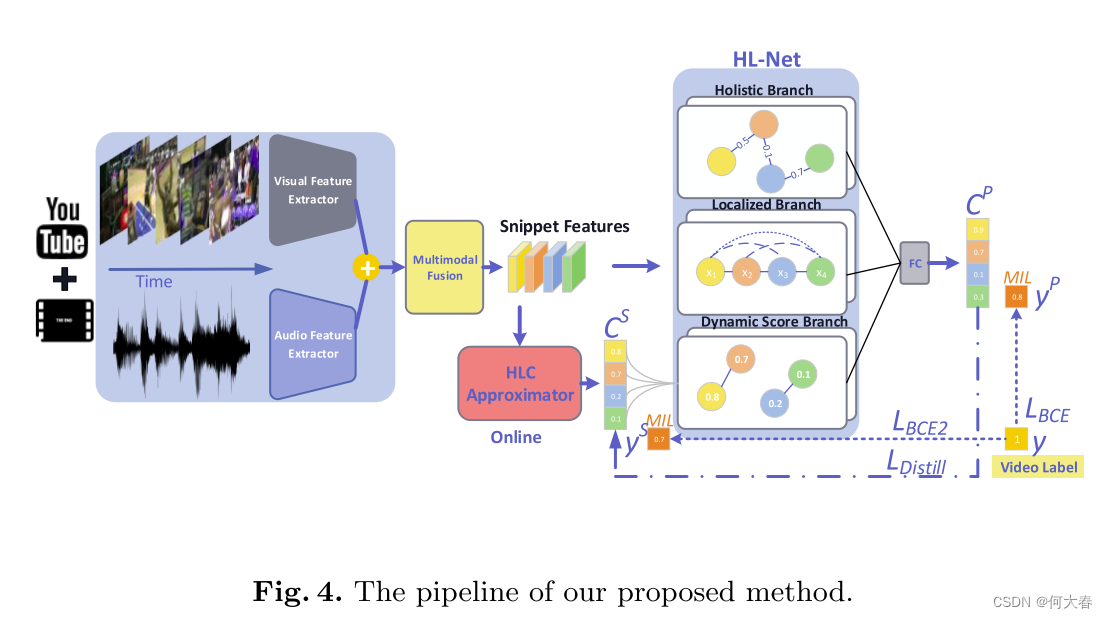
我们的提议方法总结如图4所示。假设我们有一个视频训练集,我们将一个未剪辑的视频和相应的标签表示为 V V V和 y y y,其中 y ∈ { 0 , 1 } y\in\{0,1\} y∈{0,1}, y = 1 y=1 y=1表示 V V V包含暴力事件。拿到一个视频 V V V后,我们使用特征提取器 F V F^V FV和 F A F^A FA利用滑动窗口机制提取视觉和音频特征矩阵 X V X^V XV和 X A X^A XA,其中 X V ∈ R T ′ × d V X^V\in\mathbb{R}^{T^{\prime}\times d^V} XV∈RT′×dV, X A ∈ R T ′ × d A X^A\in\mathbb{R}^{T^{\prime}\times d^A} XA∈RT′×dA, T ′ T^{\prime} T′是特征矩阵的长度, x i V x_i^V xiV和 x i A x_i^A xiA分别是第 i i i个片段的视觉和音频特征。
许多融合方式已经被提出用于多模态输入,我们选择了简单而有效的拼接融合。更具体地说,首先将 X V X^V XV和 X A X^A XA在通道上进行串联,然后将串联通过两个堆叠的全连接层(FC),分别具有512和128个节点,其中每个FC层后面跟着ReLU和dropout。最后,将输出作为融合特征,表示为 X F X^F XF。
4.2 Holistic and Localized Networks
Revisit relations.首先,我们回顾一下神经网络中的长距离依赖,这可以通过两种流行的网络类型获得,即图卷积网络(GCNs)和非局部网络(NL-Net,自注意力网络)。
一般的图卷积运算可表述如下[21]:
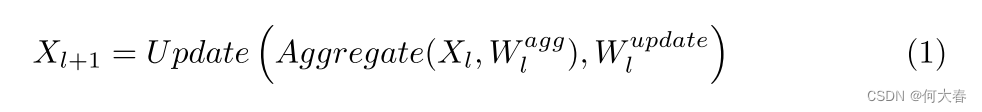
这包含两个基本操作,即聚合和更新,以及相应的可学习权重,聚合操作用于从全局顶点(长距离依赖)汇编信息,而更新函数执行非线性变换以计算新的表示。
一个实例化的非局部操作可以表述如下[40,47]:
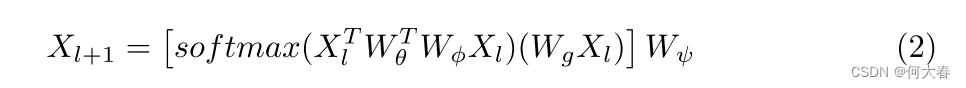
虽然它们有不同的原始意图(GCN主要用于解决非欧几里德数据的问题,而捕获长距离依赖则是一种嗜好),但它们在捕获长距离依赖方面是相似的。因为方程(2)中外部括号内的术语可以被视为基于特征相似性的聚合操作,其后是更新操作。
Holistic branch implementation.受到GCN用于视频理解的启发[51,41,50],我们通过特征相似性先验定义整体关系矩阵。在弱监督学习下学习多模态暴力检测。
如下所示:

其中, A H ∈ T ′ × T ′ A^H\in T^{^{\prime}}\times T^{^{\prime}} AH∈T′×T′, A i j H A_{ij}^H AijH衡量第 i i i个和第 j j j个特征之间的特征相似性。 g g g是归一化函数,函数 f f f计算一对特征的相似度,我们将 f f f定义如下: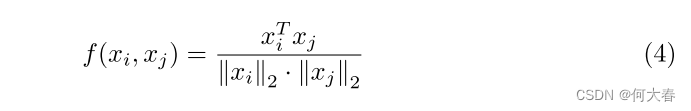
我们还定义了 f f f的其他版本,并将它们展示在补充材料中。为了阈值化操作过滤掉弱关系并加强更相似对的相关性, f f f将相似度限制在(0, 1]范围内。阈值化操作可以定义如下:
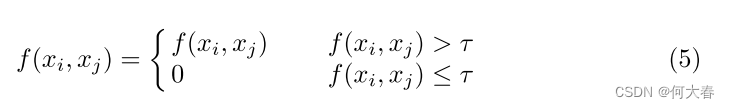
其中,τ是阈值。然后,我们采用softmax作为规范化函数g,以确保A的每一行的总和为1,如下所示:
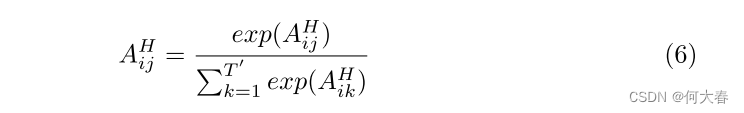
我们强调在公式(3)中使用的 X X X是原始特征 ( X A (X^{A} (XA和 X V ) X^{V}) XV)的串联,以捕获原始特征先验。
为了捕获长程依赖关系,我们遵循GCN范例并设计全局层为:

这使我们能够基于全局场而不是其邻居来计算基于相似性先验定义的位置的响应。
Localized branch implementation.全局分支通过计算任意两个位置之间的交互来直接捕获长程依赖性,而不考虑它们的位置距离。然而,位置距离对于时间事件的检测有积极的影响,为了保留这一点,我们根据接近性先验设计了基于局部关系矩阵如下:
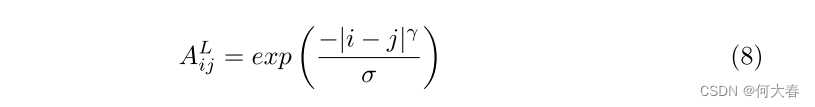
这只取决于第 i i i 个和第 j j j 个特征的时间位置,其中 γ \gamma γ 和 σ \sigma σ 是控制距离关系影响范围的超参数。同样, X l + 1 L X_{l+1}^L Xl+1L 是第 ( l + 1 ) (l+1) (l+1) 层局部层的输出。
4.3 Online Detection
正如我们之前提到的,暴力检测系统不仅适用于离线检测(互联网视频内容审核),还适用于在线检测(监控系统)。然而,以上的 HL-Net 在线检测受到一个主要障碍的阻碍:HL-Net 需要整个视频才能获得长距离依赖关系。为了摆脱这个困境,我们提出了一个 HLC 近似器,只需将之前的视频片段作为输入,即可生成由 HL-Net 引导的精确预测。两个堆叠的 FC 层后跟 ReLU,以及一个 1D 因果卷积层构成了 HLC 近似器。1D 因果卷积层在时间维度上的卷积核大小为 5,步长为 1,在时间上滑动卷积过滤器。1D 因果卷积层也充当分类器,其输出是形状为 T ′ T^{\prime} T′ 的暴力激活,表示为 C S C^S CS。更好的是,此操作引入了一个额外的分支,称为动态得分分支,以扩展 HL-Net,其依赖于 C S C^S CS。
Score branch implementation.该分支的主要作用是计算位置的响应,作为所有位置的特征的加权和,其中权重取决于得分的接近程度。与整体和本地分支的关系矩阵不同,分数分支的关系矩阵在每次迭代中更新,并且依赖于预测得分而不是先验。形式上,分数分支的关系矩阵设计如下:
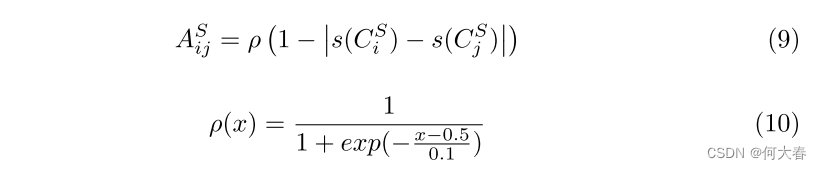
其中,函数 s s s是sigmoid函数,函数 ρ \rho ρ用于增强(或减弱)两两关系,其中得分的接近程度大于(或小于)0.5,并且softmax也用于归一化。
类似地, X l + 1 S X_{l+1}^{S} Xl+1S是第 ( l + 1 ) (l+1) (l+1)个得分层的输出,其中 X 0 S = ( X 0 H = X 0 L ) = X F X_{0}^{S} = (X_{0}^{H}=X_{0}^{L})=X^{F} X0S=(X0H=X0L)=XF。
4.4 Training Based on MIL
我们使用一个具有1个节点的全连接(FC)层将连接表示投影到标签空间(1D空间),在这个投影之后,我们获得的暴力激活可以表示为:
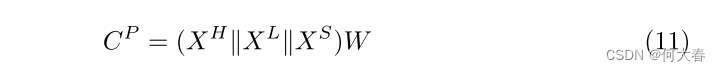
其中, ∥ \parallel ∥ 表示连接操作,而 C P ∈ R T ′ C^P \in \mathbb{R}^{T^{\prime}} CP∈RT′ 表示暴力激活。
根据MIL的原则,我们使用K-max激活( C P C^{P} CP和 C S C^{S} CS)在时间维度上的平均值来计算 y P y^{P} yP和 y S y^{S} yS,其中 K K K定义为 ⌊ T q + 1 ⌋ \left \lfloor \frac{T}{q} + 1 \right \rfloor ⌊qT+1⌋。正袋中K-max激活对应的实例很可能是真正的正实例(暴力)。负袋中K-max激活对应的实例是困难实例。我们希望这两种类型的实例尽可能远离。
我们定义分类损失 L B C E L_{BCE} LBCE和 L B C E 2 L_{BCE2} LBCE2为预测标签 ( y P (y^P (yP和 y S ) y^S) yS)与真实标签 y y y之间的二元交叉熵。此外,我们还使用知识蒸馏损失来鼓励HLC近似器的输出逼近HL-Net的输出。
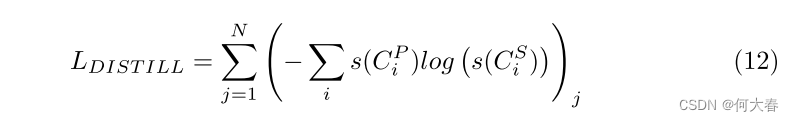
其中,N为批大小。最后,总损失是上述三个损失的加权和,如下所示:
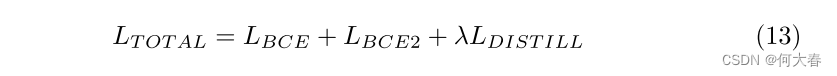
4.5 Inference
针对不同的需求,我们的方法可以选择离线或在线方式来高效地检测暴力事件。Sigmoid函数跟随暴力激活 C P C^{P} CP 和 C S C^{S} CS 并生成范围在 [0,1] 区间内的暴力置信度(分数)。需要注意的是,在在线推理中,只有HLC近似器起作用,HL-Net可以被移除。
5 Experiments
5.1 Evaluation Metric
我们利用帧级别的精确率-召回率曲线(PRC)及其曲线下面积(平均精度,AP)[30],而不是接收器操作特性曲线(ROC)及其曲线下面积(AUC)[44,43],因为当处理类别不平衡的数据时,AUC通常呈现乐观的结果,而PRC和AP则聚焦于正样本(暴力)。
5.2 Implementation Details
Visual features.视觉特征。我们利用两个主流网络作为我们的视觉特征提取器 F V F^V FV,即C3D[38]和I3D[3]网络。我们从在Sports-1M数据集上预训练的C3D中提取 f c 6 fc6 fc6特征,并从在Kinetics-400数据集上预训练的I3D中提取 g l o b a l _ p o o l global\_pool global_pool特征。I3D是一个双流模型,因此,视觉特征有两个版本,即RGB和光流。我们使用TV-L1[48]的GPU实现来计算光流。我们将所有视频的帧率固定为24 FPS,并将滑动窗口的长度设置为16帧。
Audio features.我们利用在大型YouTube数据集上预训练的VGGish[6,17]网络作为音频特征提取器 F A F^A FA,因为它在音频分类上表现出色。音频被分成重叠的960毫秒段,其中每个段都有与之对应的唯一视频片段,并具有对齐的结束时间。从这些段计算出的96×64个频段的对数梅尔频谱图形成了输入到VGGish的输入。除非另有说明,默认情况下我们使用I3D的RGB特征和VGGish特征的融合。
HL-Net architecture.Generalized HL-Net由整体分支、局部分支和额外的得分分支组成。每个分支都是两层堆叠,每层的输出通道数为32。此外,受到[16,33,21]的启发,我们为每一层添加了一个残差连接,这使得GCN在训练阶段能够可靠地收敛。
Training details.我们基于PyTorch实现了该网络。对于超参数,除非另有说明,我们将τ设置为0.7,AL的γ和σ设置为1,q设置为16,dropout率设置为0.7,λ设置为5。对于网络优化,我们使用Adam作为优化器。初始学习率设为10^-3,并在第10个和第30个epoch时除以10。网络总共训练50个epoch,批量大小为128。
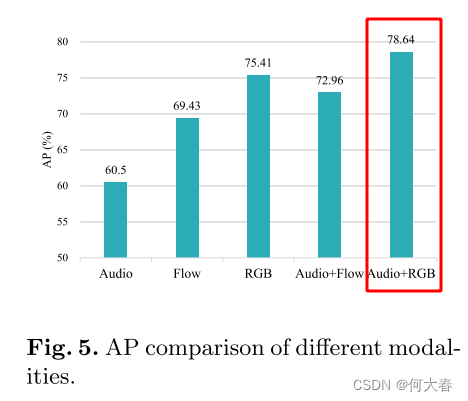
不同模态组合的实验结果(得出音频和图像效果最好):
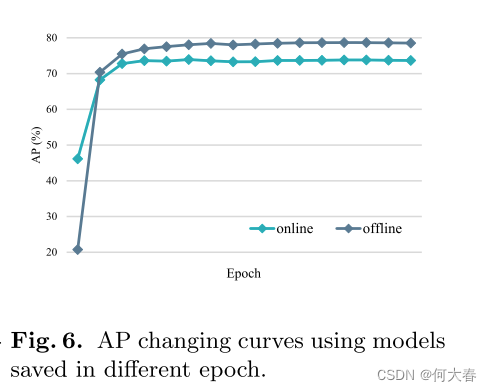
在线与离线分支二者的结果:
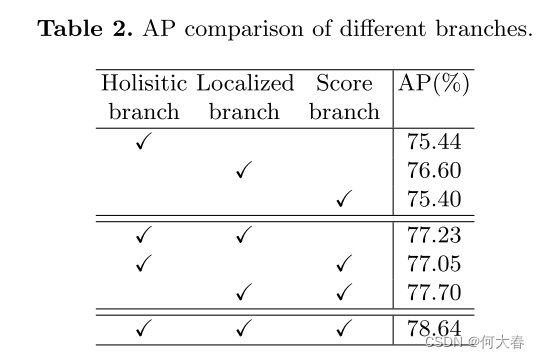
三个分支消融实验结果:
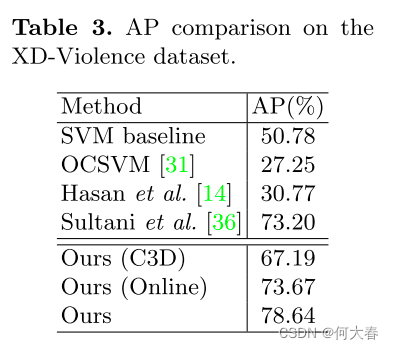
与sota结果比较:
6 Conclusions
在本文中,我们研究了基于弱监督下的大规模音视频模态暴力检测。由于缺乏适用的数据集,我们首先发布了一个大规模的暴力数据集来填补这一空白。然后,我们提出了一种方法来显式地建模视频片段之间的关系并学习强大的表示。大量实验表明:
1)我们的数据集是适用的;
2)多模态显著提高了性能;
3)显式利用关系是非常有效的。
在进一步的工作中,我们将添加一些以音频为主导的暴力类别(例如尖叫),而且我们的研究将自然扩展到多类别暴力检测,因为XD-Violence是一个多标签数据集。此外,更强大的在线检测仍有待进一步探索。
阅读总结
图卷积用来时间建模原来几年前就被他们玩烂了,并联串联已经变换好几种方式了,确实6。