基于距离的向量数据库检索在高维空间中嵌入(embedding)查询语句,并基于“距离”查找相似的嵌入文档。但是,存在这样一种情况,当人们对相同问题提问时,可能写出的查询语句各不相同,这样就会造成检索到的结果可能也存在差异,这对于非专业人员来说,往往会检索不到满意的答案,或者系统使用的文本嵌入(text embedding)模型不能很好地捕获文本的语义,这都会造成我们检索不到满意的答案。今天我们就来介绍一种多重查询的技术,它可以让非专业人士在做文档检索时可以得到满意的结果。
一,环境配置
我们需要安装如下python包:
pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain下面我们导入所需要的python包:
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.prompts import ChatPromptTemplate
from operator import itemgetter
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain_openai import ChatOpenAI二、传统检索方式
在Langchain框架中实现最基础的RAG方法是:1.加载文档,2.分割文档、3.创建监视器、4.创建chain。下面我们来实现一个最基本的RAG。我们会对百度百科上的一篇关于恐龙的文章进行检索,针对问题:恐龙是怎么灭绝的?我们来看看LLM会检索出什么样的结果:
# Load Documents
loader = WebBaseLoader("https://baike.baidu.com/item/恐龙/139019")
docs = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# Embed
vectorstore = Chroma.from_documents(documents=splits,
embedding=bge_embeddings)
retriever = vectorstore.as_retriever()
#### RETRIEVAL and GENERATION ####
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Question
response = rag_chain.invoke("恐龙是怎么灭绝的?")
print(response)
这里我们看到当我们使用传统的RAG方法可以从文档中检索出答案。但是这个答案是基于用户自己书写的查询语句检索而来的,如果当用户没有正确书写查询语句,或者LLM不能够正确理解用户查询语句的含义时,此时LLM生成的答案可能就不够完整和全面。如何解决这个问题呢,这就引出了下面我们要讨论的多重查询的基本思想:
二、多重查询基本思想
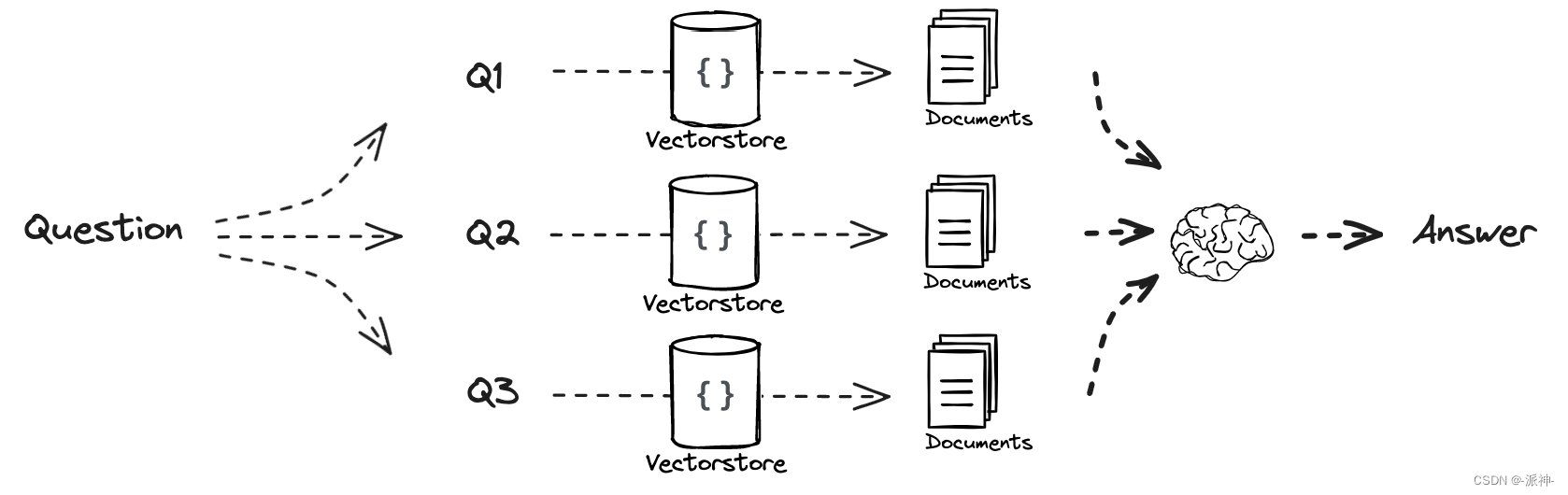
Multi Query的基本思想是当用户输入查询语句(自然语言)时,我们让大模型(LLM)基于用户的问题再生成多个查询语句,这些生成的查询语句是对用户查询语句的补充,它们是从不同的视角来补充用户的查询语句,然后每条查询语句都会从向量数据库中检索到一批相关文档,最后所有的相关文档都会被喂给LLM,这样LLM就会生成比较完整和全面的答案。这样就可以避免因为查询语句的差异而导致结果不正确。如下图所示:
三,文档加载
这里我们会加载百度百科上的一篇关于恐龙的文章,我们会对该篇文章的内容进行检索:
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://baike.baidu.com/item/恐龙/139019")
data = loader.load()
print(data[0].page_content)
四,定义embedding, LLM模型
这里我们选择是 BAAI/bge-small-zh-v1.5作为我们的embedding模型,因为它是开源的模型,而且体积较小,性能也不差,没有GPU算力的机器靠CPU也能跑得动该模型,另外我们使用的LLM是兼容Openai API的国产模型kimi,因为国外的大模型比如ChatGPT, Claude等对中国用户都不是很友好,因此选择那些能够与Openai API兼容的国产模型,这样我们就可以使LangChain框架来调用国产大模型了。关于Kimi我们需要去官网注册账号并申请api key。下面是Kimi官方文档中使用API的例子:

接下来我们就利用Changchain框架来创建bge_embeddings ,LLM:
api_key = "XXXXX"
base_url="https://api.moonshot.cn/v1"
model = "moonshot-v1-8k"
#创建BAAI的embedding
bge_embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
#创建llm
llm = ChatOpenAI(model_name=model,
api_key=api_key,
base_url=base_url,
temperature=0)五、创建检索器
使用Langchain创建检索器(retriever)的基本步骤是:1.加载文档,2.创建文档分割器,并分割文档, 3.创建向量数据库,4.创建检索器。
# 1.加载文档
loader = WebBaseLoader("https://baike.baidu.com/item/恐龙/139019")
docs = loader.load()
# 2.创建文档分割器,并分割文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 3.创建向量数据库
vectorstore = Chroma.from_documents(documents=splits,
embedding=bge_embeddings)
# 4.创建检索器
retriever = vectorstore.as_retriever()当创建完检索器以后,我们可以使用检索器来检索相关文档:
relevant_docs= retriever.get_relevant_documents('恐龙是怎么灭绝的?')
print(relevant_docs)
下面我们可以查看一下检索到的相关文档的数量:
len(relevant_docs) 
这里我们看到get_relevant_documents方法返回4个相关文档。
六、Prompt
当我们创建了检索器以后,我们就可以根据用户提出的查询语句来检索出相关文档,但是查询语句可能因人而异,每个人针对同一个问题写出的查询语句可能会各不相同,这样就会使一些非专业人士(对LLM不熟悉的人)写出的查询语句可能不会被LLM正确理解,因而得到不正确的答案,为了解决这个问题,我们可以让LLM在用户的查询语句的基础上再生成多个查询语句,这些LLM生成的查询语句是从不同角度,不同视角对用户查询语句的补充:
# Multi Query: Different Perspectives
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
generate_queries = (
prompt_perspectives
| llm
| StrOutputParser()
| (lambda x: x.split("\n"))
)
response = generate_queries.invoke({"question":'恐龙怎么灭绝的?'})
print(response)
这里我们看到用户提出的问题是:恐龙怎么灭绝的?LLM在此基础上又生成了5个问题:
- 恐龙灭绝的原因有哪些?
- 导致恐龙消失的科学解释是什么?
- 恐龙灭绝的科学理论有哪些?
- 哪些因素可能导致了恐龙的灭绝?
- 恐龙灭绝的科学证据和理论是什么?
我们看到这些LLM生成的问题比用户的问题更加合理,这样有助于LLM正确理解用户问题的真正含义。下面我们来看看LLM生成多重查询语句时的prompt:

我们将其翻译成中文,这样可以便于大家更好的理解:

七,多重查询
现在我们已经实现了让LLM根据用户问题生成多个查询语句的能力,接下来我们使用所有的查询语句(5条LLM生成的,1条用户的)去检索向量数据库,理论上每条查询语句都会检索出4个相关文档,那么总共6条查询语句可以检索出24个相关文档,但是由于这些查询语句含义相近,而已检索出来的相关文档可能出现重复,因此我们必须过滤掉重复的相关文档,只保留唯一的文档:
from langchain.load import dumps, loads
def get_unique_union(documents: list[list]):
""" Unique union of retrieved docs """
# Flatten list of lists, and convert each Document to string
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
# Get unique documents
unique_docs = list(set(flattened_docs))
# Return
return [loads(doc) for doc in unique_docs]
# Retrieve
question = "恐龙怎么灭绝的?"
retrieval_chain = generate_queries | retriever.map() | get_unique_union
docs = retrieval_chain.invoke({"question":question})
len(docs)
这里我们定义了一个 get_unique_union 方法它的功能是将检索到的相关文档集进行去重,只保留唯一的文档。这里我们可以看到针对用户的问题:恐龙是怎么灭绝的? 我们最终检索出来7个唯一文档,这是因为get_unique_union函数对检索结果进行了去重,只保留唯一文档,如果不去重应该会有24个相关文档,这将会增加使用成本,因为接下来我们需要将相关文档喂给LLM让它产生正确的答案。
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
{"context": retrieval_chain,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
question = "恐龙是怎么灭绝的?"
response = final_rag_chain.invoke({"question":question})
print(response)
这里我们看到LLM给出比较全面且正确的答案,这是因为LLM是在6个用户问题检索出来的7个相关文档的基础上生成的答案。这个答案要比由原先单一的用户问题生成的答案更为全面。下面我们再看一些问题:
question = "恐龙时冷血动物吗?"
response = final_rag_chain.invoke({"question":question})
print(response)
question = "恐龙是怎么繁殖的?"
response = final_rag_chain.invoke({"question":question})
print(response)
总结
今天我们学习了如何如何避免在做RAG检索时由于查询语句因人而异而导致检索结果不够全面和完整的问题。 我们的主要方法是当用户在做检索时,我们让LLM基于用户的查询语句再生成多个查询语句,这些由LLM生成的查询语句能够从多个视角用户的查询语句进行补充。这样可以使得LLM能够更加准确的理解用户查询语句的真正含义从而给出更加完整且全面的答案。