问题1:longchain 关键词在中间容易被忽略掉
论文对大模型在长文本情况下的性能做了一系列实验研究,发现了一个有趣的“Lost in the middle”现象:
在处理需要识别相关上下文的信息的任务(文档问答、键值对索引)时,大模型对相关信息的位置很敏感
- 当相关的信息在输入prompt的开头或者结尾时,能够取得较好的效果
而当相关的信息在prompt中间部分时,性能会显著下降。- 此外,研究者还发现,当上下文更长时,模型性能会稳步下降;
而且配备有上下文扩展的模型并不一定就更善于使用自己的上下文。- 当评估时的序列长度在训练时所用的序列长度范围内时,对于输入上下文中相关信息位置的变化,编码器 - 解码器模型是相对稳健的;
但如果评估时的序列长度长于训练时的,那么模型性能会呈现出 U 型特征。
- 最后,为了更好地理解「向输入上下文添加更多信息」与「增多模型推理所用的内容量」之间的权衡,研究者进行了一个案例研究。该研究基于检索器 - 阅读器模型在开放域问答任务上的表现。相较于对照式的多文档问答任务实验(上下文总是会包含刚好一个用于问答问题的文档),在开放域问答任务中,可能会有多个或零个文档包含答案。
研究者发现,当通过检索维基百科来回答 NaturalQuestions-Open 中的查询时,模型性能在检索器召回率趋于稳定之前很久就已经饱和,这表明模型无法有效地使用额外的检索文档 —— 使用超过 20 个检索文档仅能略微提高性能(对于 GPT-3.5-Turbo 是 ∼1.5%,对于 claude-1.3 为 ∼1%)。
整体来说,这份研究能帮助人们更好地理解语言模型是如何使用输入上下文的,并为未来的长上下文模型引入了新的评估协议。为了促进未来的相关研究,研究者放出了代码和评估数据,请访问:https://github.com/nelson-liu/lost-in-the-middle
1.1 为什么语言模型难以完整使用其输入上下文?
模型架构的影响
为了更好地理解模型架构的潜在影响,研究者比较了仅解码器模型和编码器 - 解码器语言模型。
实验中使用的具体模型为 Flan-T5-XXL 和 Flan-UL2。Flan-T5-XXL 的训练使用了序列长度为 512 token 的序列(编码器和解码器)。Flan-UL2 一开始使用 512 token 长度的序列训练(编码器和解码器),但之后又在 1024 token 长度的序列上预训练了额外 10 万步(编码器和解码器),然后进行了指令微调 —— 其编码器在 2048 token 长度的序列上微调,解码器的序列长度则为 512 token。但是,由于这些模型使用相对位置嵌入,因此它们的推断能力(原则上)可以超出这些最大上下文长度 ——Shaham et al. (2023) 发现当序列长度为 8000 token 时,这两个模型都能取得不错的表现。
查询感知型上下文化的影响
实验中,研究者的做法是将查询(即要回答的问题或要检索的键)放在数据(即文档或键 - 值对)之后来处理。由此,当对文档或键 - 值对进行上下文化时,仅解码器模型无法顾及查询 token,因为查询只会出现在 prompt 末尾而仅解码器模型在每个时间步骤只能关注之前的 token。
另一方面,编码器 - 解码器模型使用了双向编码器来上下文化输入上下文,这似乎能更加稳健地应对相关信息的位置变化 —— 研究者猜想这一直观结论或许也能用于提升仅解码器模型的性能,做法是将查询同时放在数据的前面和后面,从而实现文档或键 - 值对的查询感知型上下文化。
指令微调的影响
指令微调是指在初始的预训练之后,语言模型还会使用一个指令和响应数据集进行监督式微调。在这种监督式的指令微调数据中,任务规范和 / 或指令通常放置在输入上下文的开头,这可能会导致经过指令微调的语言模型为输入上下文的开头赋予更多权重。
1.2 上下文更多就总是更好吗?一个基于开放域问答的案例研究
就算一个语言模型可以处理 1.6 万个 token,那么如果真的为其提供这么多 token,那会真的有用吗?这个问题的答案是:由下游任务决定。因为这取决于所添加上下文的边际价值以及模型有效使用长输入上下文的能力。为了更好地理解这一权衡,研究者在 NaturalQuestions-Open 上进行了开放域问答的案例研究。
他们使用的模型采用了标准的检索器 - 阅读器设置。一个检索系统(Contriever,基于 MS-MARCO 微调得到)从 NaturalQuestions-Open 取用一个输入查询,然后返回 k 个维基百科文档。为了在这些检索到的文档上调节经过指令微调的语言模型,研究者将它们包含到了 prompt 中。他们评估了检索器召回率和阅读器准确度(任何带注释的答案是否出现在预测输出中)随检索出的文档数 k 的变化情况。研究者使用了 NaturalQuestions-Open 的一个子集,其中长答案是一个段落(而不是表格或列表)。
可以看到,在检索器性能趋于稳定之前很久,阅读器模型的性能就早已饱和,这表明阅读器没有有效地使用额外的上下文。使用超过 20 个检索文档只能略微提升阅读器性能(对于 GPT-3.5-Turbo 是 ∼1.5%,对于 Claude 为 ∼1%),但却显著提升了输入上下文长度(由此延迟和成本都大幅提升)。
这些结果表明,如果能有效地对检索文档排序(让相关信息与输入上下文的起始处更近)或对已排序的列表进行截断处理(必要时返回更少的文档),那么也许可以提升基于语言模型的阅读器使用检索上下文的能力。
1.3 解决方案
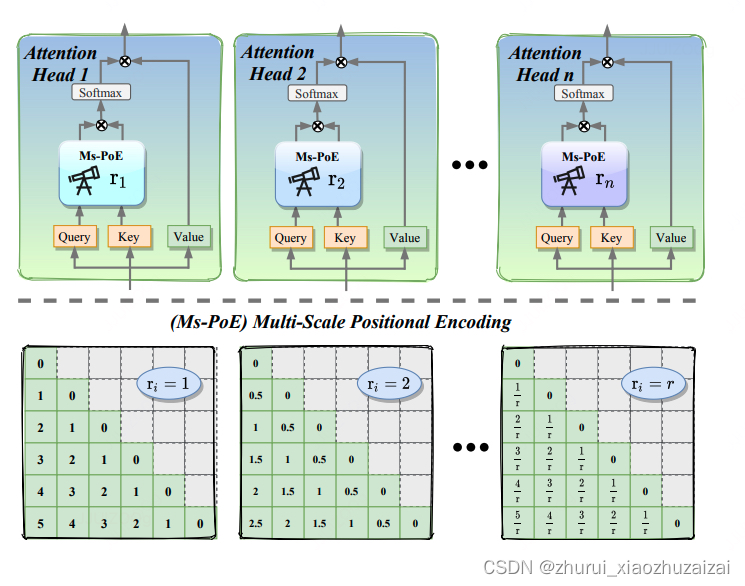
介绍了一种名为多尺度位置编码(Ms-PoE)的技术,一种插件式方法,通过重新调整位置编码索引来增强LLM处理上下文中间部分信息的能力,无需进行微调或添加任何额外开销。Ms-PoE通过对位置索引进行重新缩放来缓解由相对位置编码(RoPE)引入的长期衰减效应,同时精心为不同的注意力头分配不同的缩放比例,以保留在预训练阶段学习到的关键知识。这样形成了从短距离到长距离的多尺度上下文融合。广泛的实验显示了该方法的有效性,特别是在Zero-SCROLLS基准测试中,Ms-PoE实现了平均准确率高达3.8的提升。
优势:Ms-PoE是一种无需额外微调或增加内存使用的插件式方法。通过简单地重新映射位置嵌入,能有效地检测到上下文中间的重要信息。该方法通过对不同的注意力头使用不同的缩放比例,能够保留预训练过程中学到的知识,同时缓解了RoPE引入的长期衰减效应。此外,Ms-PoE在多种LLM上的广泛实验表明,该方法具有明显的效果提升。