RK3588是一款低功耗、高性能的处理器,适用于基于arm的PC和Edge计算设备、个人移动互联网设备等数字多媒体应用,RK3588支持8K视频编解码,内置GPU可以完全兼容OpenGLES 1.1、2.0和3.2。RK3588引入了新一代完全基于硬件的最大4800万像素ISP,内置NPU,支持INT4/INT8/INT16/FP16混合运算能力,支持安卓12和、Debian11、Build root、Ubuntu20和22版本登系统。了解更多信息可点击迅为官网
【粉丝群】824412014
【实验平台】:迅为RK3588开发板
【内容来源】《iTOP-3588开发板系统编程手册》
【全套资料及网盘获取方式】联系淘宝客服加入售后技术支持群内下载
【视频介绍】:【强者之芯】 新一代AIOT高端应用芯片 iTOP -3588人工智能工业AI主板
第5章 文件IO缓存
经过前面三个章节的学习之后,相信大家已经可以十分熟练的进行文件读写等操作,使用系统调用read和write可以分别从磁盘读取和向磁盘写入数据,但众所周知,CPU对数据的处理速度远远大于磁盘的读写速度,这一矛盾将极大的降低系统运行的效率,而缓存的出现正是为了解决这一矛盾的(当然这里只是列举了缓存的一种作用,事实上缓存无处不再),在本章节中将对缓存进行详细讲解。
5.1 缓存的分类
缓存可以分为CPU级别的缓存、操作系统的缓存以及应用层的缓存,下面对上述三种类型的缓存进行详细的叙述。
1.CPU级别的缓存:
CPU级别的缓存:是指集成在CPU芯片上的缓存,通常分为三级缓存(L1、L2、L3)。L1缓存位于CPU内部,速度最快但容量最小;L2缓存也位于CPU内部,速度略慢但容量较大;L3缓存位于CPU芯片之外,速度最慢但容量最大。CPU级别的缓存主要用于存储CPU中需要使用的数据和指令,减少CPU访问内存的次数,从而提高CPU的处理效率。
2. 操作系统的缓存:
在Linux操作系统中,缓存是一种内存管理机制,主要用于缓存磁盘上的数据,以提高系统的磁盘访问速度。Linux操作系统的缓存主要分为页缓存和目录缓存两种类型。
页高速缓存:页高速缓存是Linux操作系统中最常见的一种缓存类型,也是最重要的一种缓存类型(会在下一小节进行详细讲解)。页高速缓存主要用于缓存文件和块设备的数据,当程序读取文件或者块设备数据时,系统会将数据缓存到内存中的页高速缓存中。当程序再次访问这些数据时,系统可以直接从页高速缓存中读取数据,从而提高磁盘访问速度。
目录缓存:目录缓存用于缓存磁盘上的目录项和文件属性信息,以加速文件系统的访问。当程序访问文件或者目录时,系统会首先查找目录缓存中是否存在相应的目录项或者属性信息,如果存在,则直接返回缓存的信息,否则就需要从磁盘上读取相应的信息。
Linux操作系统中的缓存是一种非常有效的机制,可以提高系统的性能和效率。
3.应用层的缓存
应用层缓存是指应用程序自身的缓存,主要将一些常用应用的数据缓冲到内存中,以减少频繁访问磁盘等外部设备的次数,从而提高应用程序的运行效率。
综上,无论是哪一种类型的缓存,最终的作用都是用来缓解CPU和内存之间、内存和硬盘之间因为传输速度不同带来的矛盾。在接下来的小节中将会对操作系统层和应用层两种不同类型的缓存进行讲解。
类型 |
描述 |
CPU级别的缓存 |
集成在CPU芯片上的缓存,分为L1、L2、L3三级缓存。用于存储CPU需要使用的数据和指令,减少CPU访问内存的次数。 |
操作系统的缓存 |
内存管理机制,主要用于缓存磁盘上的数据,提高系统的磁盘访问速度。分为页缓存和目录缓存。页缓存用于缓存文件和块设备的数据,目录缓存用于缓存磁盘上的目录项和文件属性信息。 |
应用层的缓存 |
应用程序自身的缓存,将一些常用应用的数据缓冲到内存中,减少频繁访问磁盘等外部设备的次数,提高应用程序的运行效率。 |
5.2 页高速缓存
在 Linux 操作系统中,页是内存管理的基本单位。操作系统会将物理内存和虚拟内存(也称逻辑内存)分为若干个大小相等的区域,每个区域为一页,每页大小一般为 4KB 或 8KB。当进程需要访问内存时,操作系统会把对应的虚拟内存页映射到物理内存页上,从而实现进程对内存的访问。
而页高速缓存(Page Cache、也称为页缓存)是基于页的概念实现的,每个页缓存的页面的大小通常与系统中的物理页大小相同(一般为4KB或8KB),是内核为了提高文件系统性能而实现的一种缓存机制,用于缓存文件系统的数据块。当应用程序访问磁盘中的一个文件时,内核会将文件的数据块从磁盘读入页缓存中,当应用程序再次访问同一块数据时,内核会直接从页缓存中返回数据,而不必再次从磁盘中读取该文件,所以页缓存可以加快文件系统的读写速度,进而提高系统性能,读写关系框图如下所示:
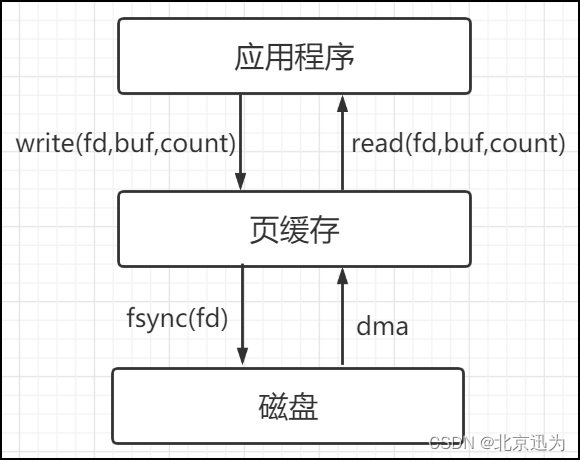
这里以写程序为例进行讲解,使用以下程序可以将“abc”3个字节的数据写入磁盘中:
write(fd, "abc", 3); //写入 3 个字节数据
程序执行完成后,write()随即返回,数据在这时并没有直接写入磁盘,而是写入到了页高速缓存中,当写入数据的页数达到一定阈值,或者系统空闲时,内核会将其缓冲区中的数据写入(刷新至)磁盘。而在此期间,另一进程试图读取该文件的这几个字节,内核将自动从缓冲区高速缓存中提供这些数据,而不是从源文件中进行提供。
需要注意的是,页缓存中的每一页都是内存中的一页,因此页缓存的大小也受到物理内存的限制。如果物理内存不足,内核会尝试从页缓存中释放一些页,以便给进程使用。
至此,关于页高速缓存的讲解就结束了。
5.3 页缓存的刷新
当数据需要写入磁盘时,需要进行缓存的刷新操作,以保证数据的一致性和完整性。页缓存的刷新可以分为显式刷新和隐式刷新两种情况,下面对两种刷新形式进行讲解:
隐式刷新
隐式刷新是指缓冲区自动刷新。当发生以下情况时,页缓存会自动刷新缓存:
1.缓存区已满。当页缓存中的缓冲区被填满时,页缓存会将缓冲区中的数据写入磁盘,并清空缓冲区,以便接收更多数据。
2.文件关闭。当文件关闭时,页缓存会将缓冲区中的所有数据写入磁盘。
3.系统关闭。当系统关闭时,页缓存会将所有未写入磁盘的缓冲区数据写入磁盘,以确保数据的一致性和完整性。
显式刷新
显式刷新是指开发人员通过调用 sync()、syncfs()、fsync()以及 fdatasync()等函数来主动刷新页缓存,接下来将对部分显式刷新函数进行讲解:
1 fsync()函数
本小节代码在配套资料“iTOP-3588开发板\03_【iTOP-RK3588开发板】指南教程\03_系统编程配套程序\28”目录下,如下图所示:
fsync()函数用来将指定文件的内容数据和元数据写入磁盘(元数据并不是文件内容本身的数据,而是一些用于记录文件属性相关的数据信息,譬如文件大小、时间戳、权限等等信息,这里统称为文件的元数据,存储在磁盘设备中),只有在对磁盘设备的写入操作完成之后,fsync()函数才会返回。所使用的头文件和函数原型,如下所示:
所需头文件 |
函数原型 |
|
1 |
#include <unistd.h> |
int fsync(int fd); |
函数调用成功将返回 0,失败返回-1,fread()函数参数含义如下所示:
参数名称 |
参数含义 |
|
1 |
fd |
文件描述符 |
fsync函数的功能较为单一,至此关于fsync()函数的讲解就完成了,下面进行相应的实验。
实验要求:
本代码所要实现的目标为对目标文件实现拷贝功能,拷贝完成之后使用fsync()函数进行缓冲区的刷新。
实验步骤:
首先进入到ubuntu的终端界面输入以下命令来创建demo28_fsync.c文件,如下图所示:
vim demo28_fsync.c
 然后向该文件中添加以下内容:
然后向该文件中添加以下内容:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
// 步骤一:判断命令行的参数
if (argc != 3)
{
// 打印命令行参数的用法
printf("Usage:%s <src file> <obj file>\n", argv[0]);
}
// 步骤二:定义变量
int fd_src; // 源文件的文件描述符
int fd_obj; // 目标文件的文件描述符
char buf[32] = {0}; // 定义读写缓存区
ssize_t ret; // 读写返回值类型为 ssize_t
// 步骤三:打开文件获得文件描述符
fd_src = open(argv[1], O_RDWR); // 以可读写方式打开源文件
if (fd_src < 0) // 如果打开源文件失败
{
perror("open is error\n"); // 打印错误信息
return -1; // 返回-1,代表失败
}
fd_obj = open(argv[2], O_CREAT | O_RDWR, 0666); // 如果目标文件不存在则创建,否则可读可写打开
if (fd_obj < 0) // 如果打开目标文件失败
{
perror("open is error\n"); // 打印错误信息
return -2; // 返回-2,代表失败
}
// 步骤四:读写操作
while ((ret = read(fd_src, buf, 32)) != 0) // 循环读取源文件
{
write(fd_obj, buf, ret); // 将读取的数据写入目标文件
}
// 对目标文件执行 fsync 同步
fsync(fd_obj);
// 步骤五:关闭文件描述符
close(fd_src); // 关闭源文件的文件描述符
close(fd_obj); // 关闭目标文件的文件描述符
return 0; // 返回0,代表成功
}和2.7综合练习1相比上述代码仅仅添加了第44行fsync()函数,用来对页高速缓存进行刷新。保存退出之后,使用以下命令对demo28_fsync.c进行编译,编译完成如下图所示:
gcc -o demo28_fsync demo28_fsync.c
 然后使用命令“vim test”创建test文件,并添加以下内容:
然后使用命令“vim test”创建test文件,并添加以下内容:
hello world!!
添加完成如下图所示:

然后使用命令“./demo28_fsync test new_file”来运行,运行成功如下图所示:

可以看到程序运行成功之后,new_file文件会被创建。
2 fdatasync()函数
系统调用 fdatasync()与 fsync()类似,不同之处在于 fdatasync()仅将参数 fd 所指文件的内容数据写入磁盘,并不包括文件的元数据。同样,只有在对磁盘设备的写入操作完成之后,fdatasync()函数才会返回。
所需头文件 |
函数原型 |
|
1 |
#include <unistd.h> |
int fdatasync(int fd); |
函数调用成功将返回0,失败返回-1 并设置 errno 以指示错误原因,fread()函数参数含义如下所示:
参数名称 |
参数含义 |
|
1 |
fd |
文件描述符 |
由于fdatasync()函数使用简单,这里就不再进行对应的实验了。
3 sync()函数
系统调用sync()会将所有文件 I/O 内核缓冲区中的文件内容数据和元数据全部更新到磁盘设备中,该函数没有参数、也无返回值,意味着它不是对某一个指定的文件进行数据更新,而是刷新所有文件 I/O 内核缓冲区。所使用的头文件和函数原型,如下所示:
所需头文件 |
函数原型 |
|
1 |
#include <unistd.h> |
void sync(void); |
由于sync()函数的使用同样简单,这里也就不再进行对应的实验了。
5.4 stdio缓冲
为了缓和CPU处理速度远远大于硬盘读写速度这一矛盾,Linux操作系统在内核空间中开辟了页高速缓冲区,read()和write()系统调用并非直接对磁盘进行读写,而是对页高速缓冲区中的数据进行操作。而每一次系统调用都要经过以下步骤:
- CPU切换到内核态
- 进行数据的拷贝
- 数据拷贝完成之后CPU切换到用户态
CPU状态间的切换是极其耗费性能的,而每次读写的数据又很小时,就显得有些得不偿失了,这时候就轮到应用层的stdio缓冲出场了。
从名字就可以看出,应用层缓存位于用户空间,当应用程序通过标准 I/O(fread()和fwrite())读写磁盘文件时,标准 I/O 的读写函数会将用户写入或读取的文件数据缓存在stdio缓冲区中,然后再一次性将stdio缓冲区中缓存的数据通过系统调用 I/O(文件 I/O)写入到文件 I/O 内核缓冲区或者拷贝到应用程序的 buf 中,以此达到减少系统调用的次数,提高系统性能的效果。
在本章节中将会对stdio缓冲进行详细的讲解。
5.4.1 stdio缓冲分类
stdio缓存包括三种类型,分别为完全缓冲(block_buffered)、行缓冲(line_buffered)和无缓冲(unbuffered),下面将对三种类型的stdio缓冲进行讲解:
完全缓冲:
全缓冲是指整个缓存区域都由用户程序控制,文件I/O操作将数据直接从缓存区读取或写入缓存区,当缓存区满时才会写入文件。在全缓存模式下,除了在程序结束时缓存区被自动刷新,还可以通过fflush()手动刷新缓存区(会在5.3.3小节对该函数进行讲解)。
行缓冲:
行缓冲是指每次I/O操作时,只有遇到换行符“\n”或者缓存区已满时才会将缓存区中的数据写入文件。在行缓存模式下,如果没有遇到“\n”字符,printf()等函数就不会返回,直到遇到“\n”或者缓存区满了才会返回。当然,也可以通过fflush()手动刷新缓存区。
无缓冲:
无缓存是指不使用缓存,每次I/O操作都直接读取或写入文件。这种方式的缺点是频繁的I/O操作会大大降低程序的效率,但是可以保证读取和写入文件的数据是最新的。
类型 |
描述 |
全缓冲 |
当缓存区被填满时才进行实际的输入/输出操作,通常用于磁盘文件 |
行缓冲 |
当遇到换行符时,缓存区才进行实际的输入/输出操作,通常用于终端设备 |
无缓冲 |
不进行缓存,每次输入/输出操作都会立即进行实际的输入/输出操作,通常用于网络通信和一些特殊设备 |
需要注意的是,stdio缓存的类型可以通过setvbuf()函数进行设置(会在下一小节对该函数进行讲解),如果不设置,默认是全缓存模式。另外,stdio库提供了很多函数用于控制缓存的刷新,如fflush()、setbuf()等。对于需要对数据进行实时写入或读取的应用程序,需要仔细考虑缓存的使用方式以及刷新时机。
5.4.2设置缓冲区
通过setvbuf()函数,可以对文件的stdio缓冲区进行设置,譬如缓冲区的缓冲模式、缓冲区的大小、起始地址等。所使用的头文件和函数原型,如下所示:
所需头文件 |
函数原型 |
|
1 |
#include <stdio.h> |
int setvbuf(FILE *stream, char *buf, int mode, size_t size); |
函数调用成功返回 0,失败将返回一个非0值,并且会设置errno来指示错误的原因。
fread()函数参数含义如下所示:
参数名称 |
参数含义 |
|
1 |
stream |
FILE 指针,用于指定对应的文件,每一个文件都可以设置它对应的 stdio 缓冲区。 |
2 |
buf |
如果参数buf不为 NULL,那么buf指向size大小的内存区域将作为该文件的stdio缓冲区。 如果buf等于NULL,那么stdio库会自动分配一块空间作为该文件的 stdio 缓冲区(参数 mode 配置为非缓冲模式除外)。 |
3 |
mode |
参数 mode 用于指定缓冲区的缓冲类型,可取值如下(每种模式的含义可以回顾上一小节): ⚫ _IONBF:不对 I/O 进行缓冲(无缓冲)。 ⚫ _IOLBF:采用行缓冲 I/O。 ⚫ _IOFBF:采用完全缓冲 I/O。 |
4 |
size |
指定缓冲区的大小。 |
对于stdio缓冲区进行相关的一些设置函数还有setbuf()函数和setbuffer()函数,使用方法和setvbuf()函数函数相似,在这里就不进行深入的讲解了,可以自行查阅。
5.4.3刷新stdio缓冲区
stdio缓冲区在写入数据时并不会立即将数据写入到磁盘或终端,而是先将数据存储到缓冲区中,等到缓冲区满了或者程序调用了刷新函数时才会将缓冲区中的数据写入到磁盘或终端。刷新缓冲区的作用就是将缓冲区中的数据强制写入到磁盘或终端,确保数据被写入到文件中,从而避免数据的丢失。下面是一些常见的刷新stdio缓冲区的方式:
1.文件关闭时自动刷新缓冲区
当一个文件流被关闭时,stdio库会自动将其对应的缓冲区刷新到文件或终端中。因此,可以通过关闭文件流来刷新缓冲区。例如:
scssCopy code
FILE *fp = fopen("file.txt", "w");// 写入数据到缓冲区fclose(fp); // 关闭文件,自动刷新缓冲区
2.缓冲区满时自动刷新缓冲区
当stdio缓冲区满时,stdio库会自动将缓冲区中的数据写入到文件或终端中。因此,可以通过向缓冲区写入大量数据来触发缓冲区满的情况,从而自动刷新缓冲区。例如:
scssCopy code
FILE *fp = fopen("file.txt", "w");
char buffer[BUFSIZ];// 向缓冲区写入大量数据,触发缓冲区满的情况fwrite(buffer, BUFSIZ, 1, fp);
3.标准I/O函数自动刷新缓冲区
在使用标准I/O函数进行输入输出时,stdio库会自动刷新缓冲区。例如,调用printf函数输出数据时,stdio库会自动将数据写入到stdout流中,并刷新缓冲区。类似地,调用scanf函数读取数据时,stdio库会自动将数据从stdin流中读取,并刷新缓冲区。
4.调用C语言库函数强制刷新
fflush函数可以强制将指定文件流的缓冲区中的数据写入到文件中或终端中。该函数的原型如下:
所需头文件 |
函数原型 |
|
1 |
#include <stdio.h> |
int fflush(FILE *stream); |
其中,参数 stream 指定需要进行强制刷新的文件,若参数 stream 为 NULL,则 fflush()将刷新所有的 stdio 缓冲区。 函数调用成功返回 0,否则将返回-1,并设置errno以指示错误原因。
5.5 分散聚集IO
除了stdio缓冲这一方式外,分散聚集IO(Scatter-Gather IO)也是减少系统调用次数从而提高系统性能的一种方式。分散聚集IO(Scatter-Gather IO)是一种IO操作方式,它可以在一次IO操作中对多个缓冲区进行读取或写入,而无需对每个缓冲区进行单独的IO操作。
在Scatter-Gather IO中,数据被分散到多个缓冲区中,每个缓冲区都有一个指针来指示读写操作的位置。因此,使用Scatter-Gather IO可以实现高效的数据传输,同时减少了数据拷贝的次数和开销,从而提高了系统性能和效率。
Scatter-Gather IO通常用于处理大量的数据传输和网络通信,例如传输文件、数据库操作和网络数据包的处理等。在操作系统中,Scatter-Gather IO由多个操作系统调用组成,最常用的是readv()和writev()系统调用,它们可以同时处理多个缓冲区的数据。
readv()函数和writev()函数的原型如下:
所需头文件 |
函数原型 |
|
1 |
#include <sys/uio.h> |
ssize_t readv(int fd, const struct iovec *iov, int iovcnt); |
2 |
ssize_t writev(int fd, const struct iovec *iov, int iovcnt); |
readv()函数和writev()函数分别从指定的文件描述符fd读取和写入数据,并将数据分散到多个缓冲区中。readv()函数和writev()函数的参数含义如下所示:
参数名称 |
参数含义 |
|
1 |
fd |
文件描述符 |
2 |
iov |
指向iovec结构体数组的指针,该结构体包含了缓冲区的地址和大小等信息。 |
3 |
iovcnt |
iovec结构体数组的长度。 |
iovec结构体定义在头文件<sys/uio.h>中,其定义如下:
struct iovec {
void *iov_base; // 缓冲区基址
size_t iov_len; // 缓冲区长度
};iovec结构体包含两个成员变量,分别为iov_base和iov_len,两个成员变量的含义如下所示:
参数名称 |
参数含义 |
|
1 |
iov_base |
指向缓冲区的基址,可以是任意类型的指针。 |
2 |
iov_len |
缓冲区的长度,以字节为单位。 |
在分散聚集IO(Scatter-Gather IO)的操作中,使用iovec结构体描述每个缓冲区的基址和长度,将多个缓冲区组合成一个整体进行IO操作。
至此关于分散聚集IO的相关讲解就完成了,下面进行相应的实验。
实验要求:
演示了如何使用iovec结构体和readv、writev函数进行分散聚集IO操作
实验步骤:
首先进入到ubuntu的终端界面输入以下命令来创建demo29_scatter-gather.c文件,如下图所示:
vim demo29_scatter-gather.c
 然后向该文件中添加以下内容:
然后向该文件中添加以下内容:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/uio.h>
#define BUF_SIZE 100
int main()
{
// 定义三个缓冲区
char buf1[BUF_SIZE] = { 0 };
char buf2[BUF_SIZE] = { 0 };
char buf3[BUF_SIZE] = { 0 };
// 定义一个 iovec 结构体数组
struct iovec iov[3];
// 定义一个变量用于记录读取的字节数
ssize_t nread;
// 设置 iovec 结构体数组的各个成员的指针和长度
iov[0].iov_base = buf1;
iov[0].iov_len = 5;
iov[1].iov_base = buf2;
iov[1].iov_len = 8;
iov[2].iov_base = buf3;
iov[2].iov_len = BUF_SIZE;
// 从标准输入中读取数据并写入到 iovec 结构体数组中
nread = readv(STDIN_FILENO, iov, 3);
// 输出读取的字节数
printf("%ld bytes read.\n", nread);
// 分别输出三个缓冲区的内容
printf("buf1: %s\n", buf1);
printf("buf2: %s\n", buf2);
printf("buf3: %s", buf3);
return 0;
}代码中定义了三个不同大小的缓冲区buf1、buf2、buf3,并创建了一个iovec结构体数组iov,将缓冲区的基址和长度保存到数组中。
在readv函数中,将标准输入文件描述符(STDIN_FILENO)作为第一个参数,将iovec结构体数组iov作为第二个参数,并将数组长度3作为第三个参数。readv函数将从标准输入中读取数据,并将数据分别存储到iovec结构体数组iov中的三个缓冲区中。
在writev函数中,将标准输出文件描述符(STDOUT_FILENO)作为第一个参数,将iovec结构体数组iov作为第二个参数,并将数组长度3作为第三个参数。writev函数将从iovec结构体数组iov中的三个缓冲区中读取数据,并将数据分别写入到标准输出中。
保存退出之后,使用以下命令对scatter-gather.c进行编译,编译完成如下图所示:
gcc -o demo29_scatter-gather demo29_scatter-gather.c
 然后使用“./demo29_scatter-gather”命令运行该程序,该程序运行完成之后会进入阻塞状态等待字符输入,如下图所示:
然后使用“./demo29_scatter-gather”命令运行该程序,该程序运行完成之后会进入阻塞状态等待字符输入,如下图所示:

然后使用“./demo29_scatter-gather”命令运行该程序,该程序运行完成之后会进入阻塞状态等待字符输入,如下图所示:

输入“abcde12345678helloworld”内容后点击回车,程序运行如下图所示:
 ‘
‘
可以看到buf1、buf2、buf3三个缓冲区的字符都被打印了出来,至此关于分散聚集IO的实验就结束了。
需要注意的是,在执行分散聚集IO操作时,需要确保iovec结构体数组描述的缓冲区物理上不连续。在上面的示例代码中,buf1、buf2、buf3是定义在栈上的三个不同的数组,它们的地址是物理上不连续的,因此可以使用iovec结构体数组描述这三个缓冲区进行分散聚集IO操作。如果将这三个缓冲区合并成一个连续的缓冲区,再使用iovec结构体数组进行分散聚集IO操作将无法提高IO操作的效率。
5.6 直接IO
在前面几个小节中对几种不同类型的缓冲进行了讲解,缓冲的存在减少了系统调用的次数,从而减小了系统开销,提高了系统性能,于此同时也带来了一些弊端,若没有中间的缓冲区,数据只需要一次拷贝就能从硬盘到达应用程序,而如今缓存的存在,使得数据需要经过内核空间的页高速缓存和用户空间的stdio缓冲区,数据的多次拷贝增大了CPU和内存的开销,那有没有一种方式,可以直接在应用程序和硬盘间进行数据的读写呢,答案是肯定的。
直接IO(Direct I/O)也被称为“零拷贝IO”(Zero Copy I/O),是一种在数据传输过程中直接将数据从磁盘或网络卡读取到用户空间的技术,而不需要经过中间缓存的过程。这种技术通常使用在大规模数据传输的场景中,例如文件拷贝、数据库、图像视频处理等领域。
与标准I/O相比,直接I/O没有缓冲区的概念,数据直接从磁盘读取到用户空间的缓存中,然后进行处理。这减少了复制和内核空间的操作,从而提高了效率。
与系统调用I/O相比,直接I/O避免了将数据从内核缓冲区复制到用户空间缓冲区的操作。这在大量数据传输时可以提高效率。
而要使用直接 I/O只需要在调用 open()函数打开文件时,指定O_DIRECT 标志,具体代码如下所示:
fd = open(filepath, O_WRONLY | O_DIRECT);
在之后的章节会对直接IO进行讲解,本小节就不再进行相应的实验了,下面对直接IO的优缺点进行总结:
直接IO的优点:
1.减少数据传输的中间步骤,减少CPU和内存的开销,提高数据传输的效率。
2.避免了数据拷贝过程中的内存分配和复制开销,节省了系统资源和时间。
3.减少了上下文切换次数,避免了CPU等待,提高了系统的整体性能。
直接IO的缺点:
1.使用直接IO需要在内核态和用户态之间频繁切换,会增加系统的负担。
2.直接IO对应用程序的要求较高,需要使用特定的函数调用和操作系统支持。
3.直接IO不能对普通文件进行操作,只能对支持mmap()操作的文件系统进行读写操作。
综上,使用直接IO需要权衡其优缺点,具体使用场景需要根据实际情况进行选择。
5.7 缓冲IO总结
下图概括了 stdio 函数库和内核所采用的缓冲(针对输出文件),以及对各种缓冲类型的控制机制。自上而下,首先是通过 stdio 库将用户数据传递到 stdio 缓冲区,该缓冲区位于用户态内存区。当缓冲区填满时,stdio 库会调用 write()系统调用,将数据传递到内核高速缓冲区(位于内核态内存区)。最终,内核发起磁盘操作,将数据传递到磁盘。
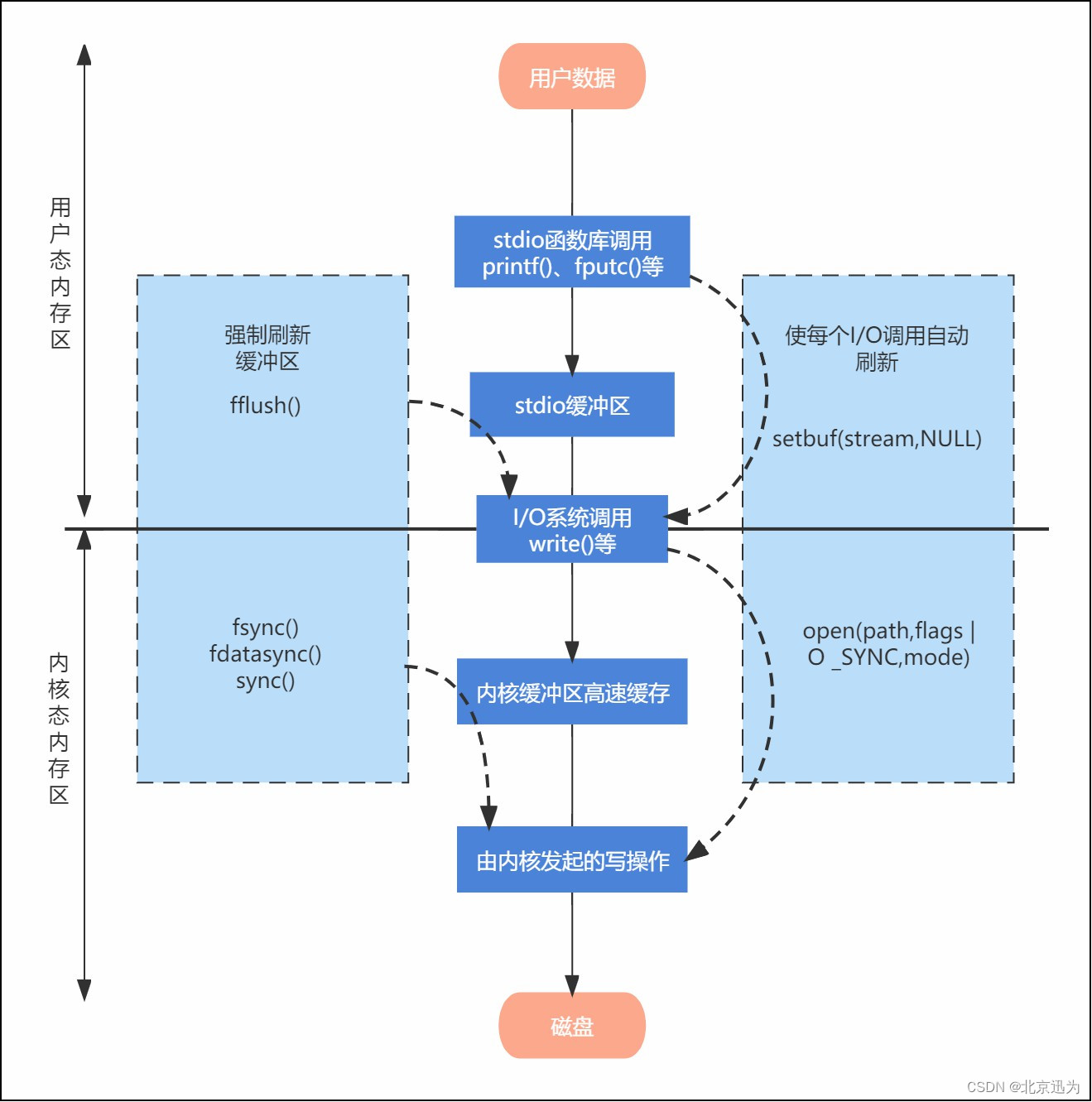
应用程序调用库函数可以对 stdio 缓冲区进行相应的设置,设置缓冲区的缓冲模式、缓冲区大小以及由调用者指定一块空间作为 stdio 缓冲区,并且可以强制调用 fflush()函数刷新缓冲区;而对于内核缓冲区来说,应用程序可以调用相关系统调用对内核缓冲区进行控制,譬如调用 fsync()、fdatasync()或 sync()来刷新内核缓冲区(或通过 open 指定 O_SYNC 或 O_DSYNC 标志),或者使用直接 I/O 绕过内核缓冲区(open 函数 指定 O_DIRECT 标志)。