第三讲 数据挖掘详解(上)
文章目录
3.1 数据挖掘技术的分类
数据挖掘的定义是“通过对(通常是大量的)数据集进行分析,发现潜在的数据关系,用易于理解的、能被数据所有者使用的新方式对数据进行概括”。数据挖掘的输入数据通常是表格,输出可以是规则、簇、树结构、图、方程式和模式等。最初,“数据挖掘”一词含有负面意义,尤其是在统计学家之间,诸如“数据窥探”、“钓鱼”和“数据捕捞”一类的术语是指从没有完全统计基础的数据中提取结论的特殊技术。然而,随着时间的推移,数据挖掘学科变得更加成熟,数据挖掘有了扎实的科学方法和丰富的实际应用。
3.1.1 数据集:实例与变量
让我们先看看3个范例数据集和可能的问题。表3.1是最近人数死亡统计表格的一部分,原表格含有860条记录。该表记录了每个人死亡时的年龄(age列),drinker列标明此人是否饮酒,smoker列标明此人是否吸烟,weight列记录此人死亡时的体重。表3.1中的每一行对应于一位死亡者的信息。针对该数据集,可能的问题有:
- 吸烟和喝酒对人的体重有什么影响?
- 吸烟者是否也喝酒?
- 影响人预期寿命的最重要的因素是什么?
- 能否找到一组特定的人群,他们具有相似的生活方式?
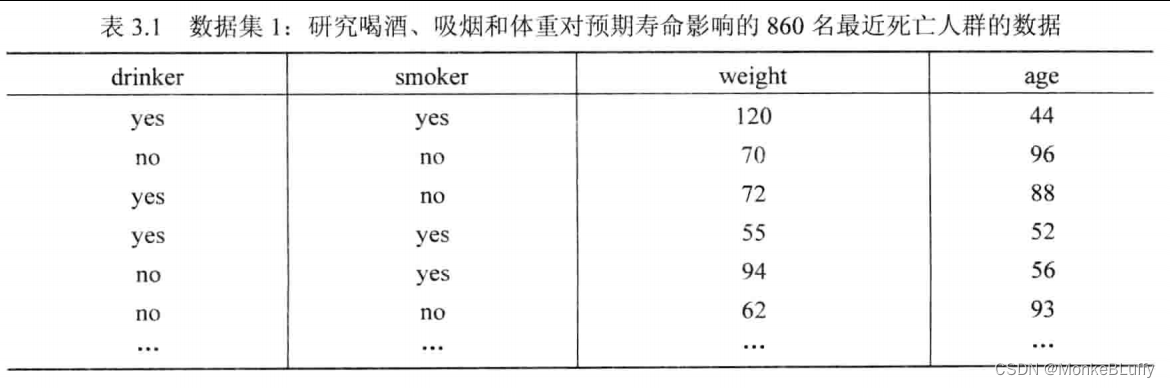
表3.2展示了另一个数据集,该数据集记录了某本科项目420名学生的相关信息。表格每行对应于一名学生的信息,不同学生选择的课程不同。该表罗列了学生每门课程的得分,例如,第一位学生在线性代数课上得了9分,在逻辑课上得了8分。表3.2使用的是荷兰的课程评分系统,在该评分系统中,课程成绩在1分(最低分)和10分(最高分)之间。5分和5分以下的视为不通过。“—”表示该学生未修该门课程。该表只展示了部分课程的情况。在必修课程之外,还存在大量选修课程。最后两列展示了学生的整体表现。duration一列记录学生毕业或退学之前的学习总时长。result列记录学生的综合表现:优秀、通过或不通过。学校可能对以下问题感兴趣:
- 某些课程的成绩之间是否存在很高的相关性?
- 综合表现优秀的学生通常选择哪些课程?
- 哪些课程严重拖延了毕业时间?学生为何退学?
- 能否找到一组学生,他们具有相似的学习行为?
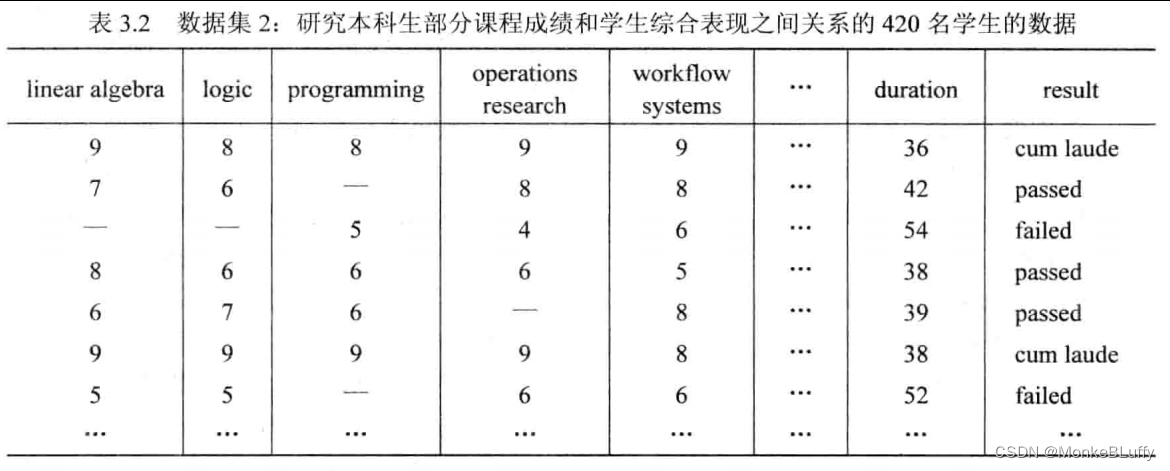
表3.3展示了第3个数据集的部分内容,该数据集含有240条某咖啡馆的点餐单信息。每行对应于一名顾客的点餐单,每列则对应于某样产品。例如,第一位顾客点了一杯卡布奇诺和一份小松饼。类似例子极为常见,这类数据集上的分析通常被称为购物篮分析(market basket analysis),例如,我们可以对顾客在超市或电子商店购买的产品组合进行分析。咖啡店、超市、书店等可能会对下列问题感兴趣:
- 顾客通常同时购买哪些产品?
- 人们会在何时购买某种特定的产品?
- 是否可以描述典型顾客群的特征?
- 如何提升产品的销量和利润?
表3.1、表3.2和表3.3展示了作为数据挖掘算法输入的3个典型数据集,这样的数据集通常被称为样本(sample)或表(table)。这3张表中的行通常被称为实例(instance),其他常见的名称包括个体(individual)、实体(entity)、案例(case)、物体(object)或记录(record)等。实例可以对应于死亡者、学生、顾客、订单、订单明细、消息等。这3张表中的列被称为变量(variable),变量通常还被称为属性(attribute)、特征(feature)或数据元素(date element)等。第一个数据集(表3.1)中含有4个变量:drinker、smoker、weight和age。
我们区分类别变量(categorical variable)和数值变量(numerical variable)。类别变量含有一个可能取值的有限集合,可以简单地枚举这些值。例如,一个可能取值为真或假的布尔型变量。数值变量可以排序,但不能简单地枚举。数值变量的例子包括:温度(39.7摄氏度)、年龄(44岁)、体重(56.3千克)、物品数量(3杯咖啡)和高度(海平面下11米)。类别变量通常还可以被进一步细分为序数变量(ordinal variable)和名义变量(也就是类别变量,nominal variable)。名义变量没有逻辑上的排序,例如,布尔型变量(真或假)、颜色(红、黄、绿)、欧洲国家(德国、意大利等),它们没有普遍接受的逻辑排序。序数变量含有对应的排序规则,例如表3.2中的result列即为序数变量,它含有优秀、通过和不通过3个可能取值。大多数情况下,“通过”应在“优秀”和“不通过”之间。
在应用数据挖掘技术之前,需要对数据进行预处理。很多情况下,我们可以删除一些行与列。例如,我们可以事先移除几乎不含有相关信息的列,从而减少问题的维度。明确含有偏差的实例也应该被移除。此外,某个特定实例的部分变量值可能出现缺失或类型错误,这可能是记录数据时的错误,也可能有其他具体的原因。例如,表3.2中部分课程的成绩缺失(用“—”标识)。该缺失并不是记录时的错误,相反,它含有特定的含义。对于某些分析技术,缺失的课程成绩可以被视为0。也就是说,未选修该课视为比该门课的最低得分还低。对于其他一些分析技术,该列的值可以映射为“是”(上过该门课)或“否”(成绩为“—”的实例)。
将表3.1、表3.2、表3.3与表1.3的事件记录进行比较,显然相对于过程挖掘技术,数据挖掘技术对输入数据的格式做出的假设更少。例如,表1.1中定义了两种标识符——事件和案例,而不是单一的标识符(如表格中的行)。进一步的,事件可以根据时间排序,而在表3.1、表3.2和表3.3中,行的顺序并没有任何意义。对于某些特定的问题,可以将事件记录转化为简单的数据集,从而进行数据挖掘。我们把这样的行为称为特征抽取(featureextraction)。后面,我们将在很多场合使用特征抽取,例如对发现的过程模型的决策进行分析,又如在过程发现之前对案例进行聚类从而为每个类别建立单独的过程模型。
在介绍数据挖掘的基本输入格式并讨论典型的数据挖掘问题之后,我们将数据挖掘技术分为两个主要类别:有监督学习(supervised learning)和无监督学习(unsupervisedlearning)。
3.1.2 有监督学习:分类与回归
有监督学习假设数据带标记,也就是说,存在一个标记所有实例的响应变量(responsevariable)。例如在表3.2中,result列可以被选为响应变量,因此每个学生可以被标记为“优秀”、“通过”或“不通过”。其他的变量称为预测变量(predictor variable)。我们希望通过预测变量解释响应变量。有时候,响应变量也被称为依赖变量(dependent variable),预测变量则被称为独立变量(independent variables)。我们的目标是通过独立变量解释依赖变量。例如,我们可能希望通过学生的课程成绩预测他的综合表现。
根据响应变量类型的不同(类别变量或数值变量),有监督学习技术可以被进一步划分为分类和回归。分类技术假设响应变量是类别变量,其目的是通过预测变量对实例进行分类。考虑表3.1中的例子,我们可以将人分为吸烟者和不吸烟者两类。因此,我们选择了一个类别响应变量:smoker。通过分类,我们希望找出吸烟者和不吸烟者之间的主要不同。例如,我们可以发现大多数吸烟者同时还喝酒且早逝。通过对第二个数据集(表3.2)应用分类技术,且将result列作为响应变量,我们可以发现一个显著的事实:综合表现优秀的学生成绩也比较高。在3.2节中,我们将说明如何通过分类技术来构建决策树。
回归技术假定响应变量是数值变量,该技术的目的是找出一个最佳函数,它能够以最小的误差拟合原有数据。例如,我们选择年龄作为表3.1中数据集的响应变量,(假设)我们发现了函数:age=124-0.8×weight。例如,一个50公斤的人预计活到84岁,而一个100公斤的人则预计活到44岁。对于第二个数据集,我们可以发现,工作流系统课的得分严重依赖于线性代数课和逻辑课的得分。例如,workflow systems=0.6+0.8×linear algebra+0.2×logic。对于第三个数据集,我们可以(再次假设)发现一个函数,通过其他饮料的购买量,这个函数能够预测硬面包圈的购买量。
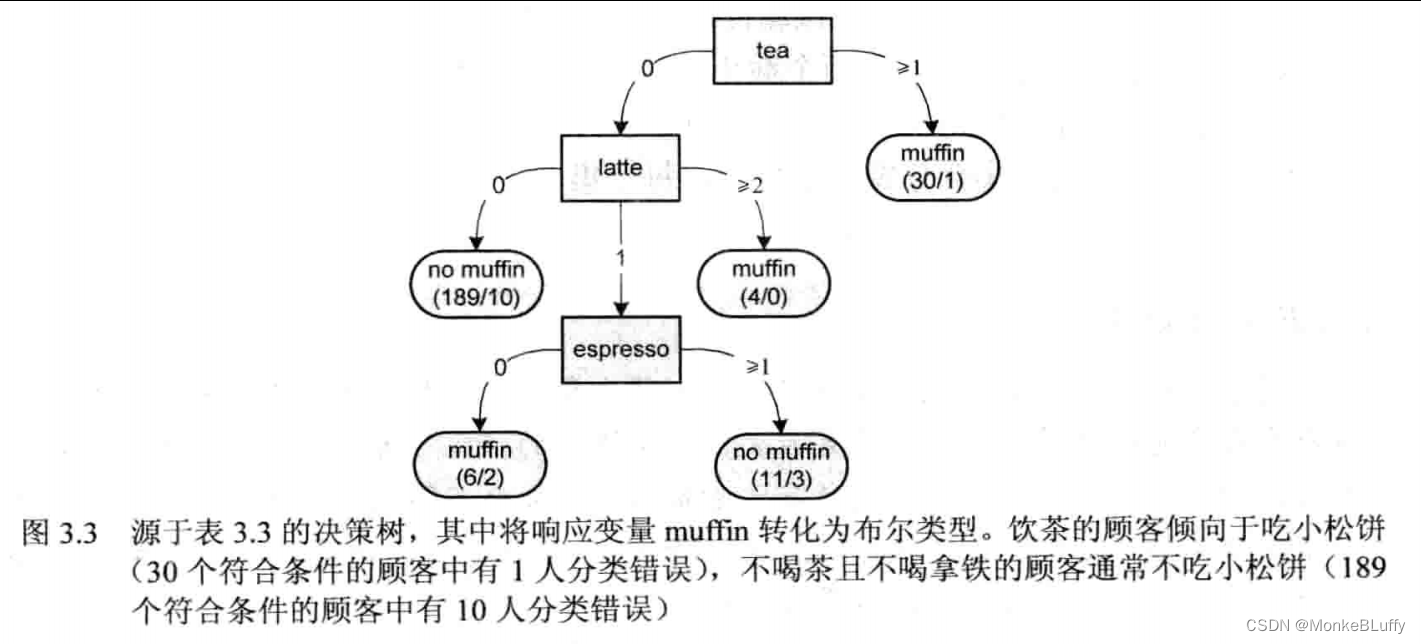
分类需要一个类别响应变量。在一些例子中,我们可以将数值响应变量转化为类别响应变量。例如,对于表3.1,我们可以通过如下方式将变量年龄转化为类别响应变量:低于70岁的年龄映射到“年轻”,70和70岁以上映射到“年老”。这样,我们就可以构建一个将实例分类为在年轻时死亡人员和年老时死亡人员的决策树。类似的,表3.3中的值也可以转化为类别变量,例如将正值映射到“是”(该商品被购买),0值映射到“否”(该商品并未被购买)。将该映射规则应用到表3.3后,我们可以对该咖啡馆的数据应用分类技术。例如将列muffin作为响应变量,我们可以发现,饮用较多茶的顾客倾向于吃小松饼。
3.1.3 无监督学习:聚类与模式发现
无监督学习假设数据无标记,也就是说,我们并不将变量分为响应变量和预测变量。在本章中,我们考虑两种类型的无监督学习:聚类和模式发现。
聚类算法通过检验数据来发现相似的实例组。与分类算法不同,聚类算法并不关注某些响应变量,而是将整个实例视为一个整体。例如,聚类的目的可以是发现学生(表3.2)或顾客(表3.3)中的相似群体。著名的聚类技术有k-means聚类和层次聚类,3.3节将对它们进行简单介绍。
有许多针对数据的模式发现技术。通常情况下,我们的目的是寻找“如果X则Y”模式,其中X和Y涉及不同变量的值。例如对于表3.1,有“如果somker=no并且age≥70,则drinker=yes”,对于表3.2,有“如果logic≤6并且duration>50,则result=failed”。最著名的模式发现技术是关联规则挖掘,我们将在3.4节进一步解释这一技术。
注意决策树也可以被转化为规则。然而,决策树通常是针对一个特定的响应变量构建的,因此从决策树抽取的规则只能通过预测变量来说明响应变量。关联规则是通过无监督学习发现的,也就是说,我们不需要选择特定的响应变量。
数据挖掘的结果可以是说明性的,也可以是预测性的。决策树、关联规则、回归函数可以说明用于学习模型的数据集中的一些规律。然而它们也可以用于对新的实例进行预测,例如通过一个学生第一学期的课程成绩预测其综合表现。
下面,我们将具体分析之前提过的一些技术。在本章最后,我们将关注如何对挖掘结果的质量进行度量。
3.2 决策树学习
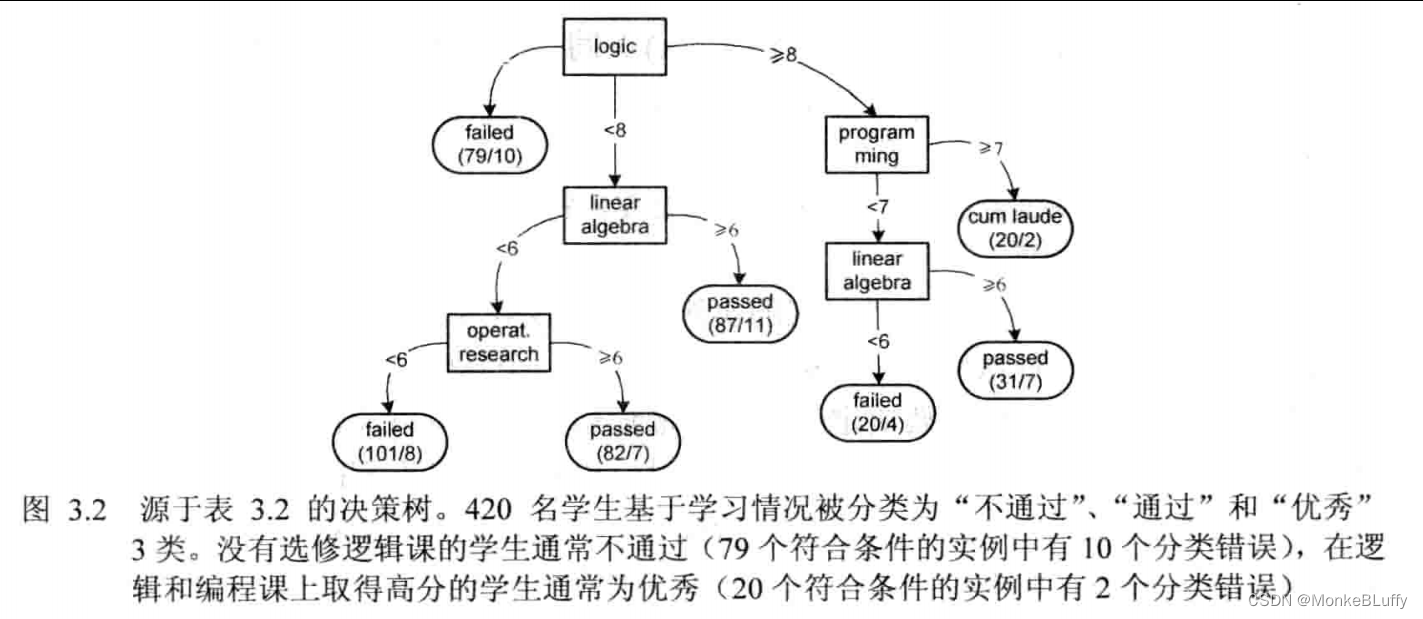
决策树学习是一种基于预测变量对实例进行分类的有监督学习技术。在决策树学习中,只有一个标记数据的类别响应变量,学习结果采用树形结构呈现。图3.1、图3.2和图3.3分别展示了针对本章之前介绍过的3个数据集的决策树。叶子结点对应于响应变量的可能取值,非叶子结点对应于预测变量。在决策树学习的上下文中,预测变量被称为属性(attribute)。每个属性结点将一个实例集分裂成两个或更多的子集,根结点对应于所有实例。
在图3.1中,根结点代表所有实例。在这个例子中有860个实例(对应860人)。基于属性smoker,实例被分裂为吸烟(195人)和不吸烟(860-195=665人)两类实例。吸烟的实例不再继续分裂。基于此信息,我们已将该类实例标记为“年轻”,也就是说,我们认为吸烟者应死于70岁前。不吸烟者被进一步分裂为饮酒者和不饮酒者。我们认为后一组人能活得更长,因此标记为“年老”。所有叶子结点含有两个数字,前一个数字表示被分类为该情况的实例数,第二个数字表示关联于该叶子结点,但被错误分类为实例的总数。在所有195名被分类为“年轻”的吸烟者中,11人被错误分类,也就是说他们虽然吸烟,但并没有在70岁前死亡。
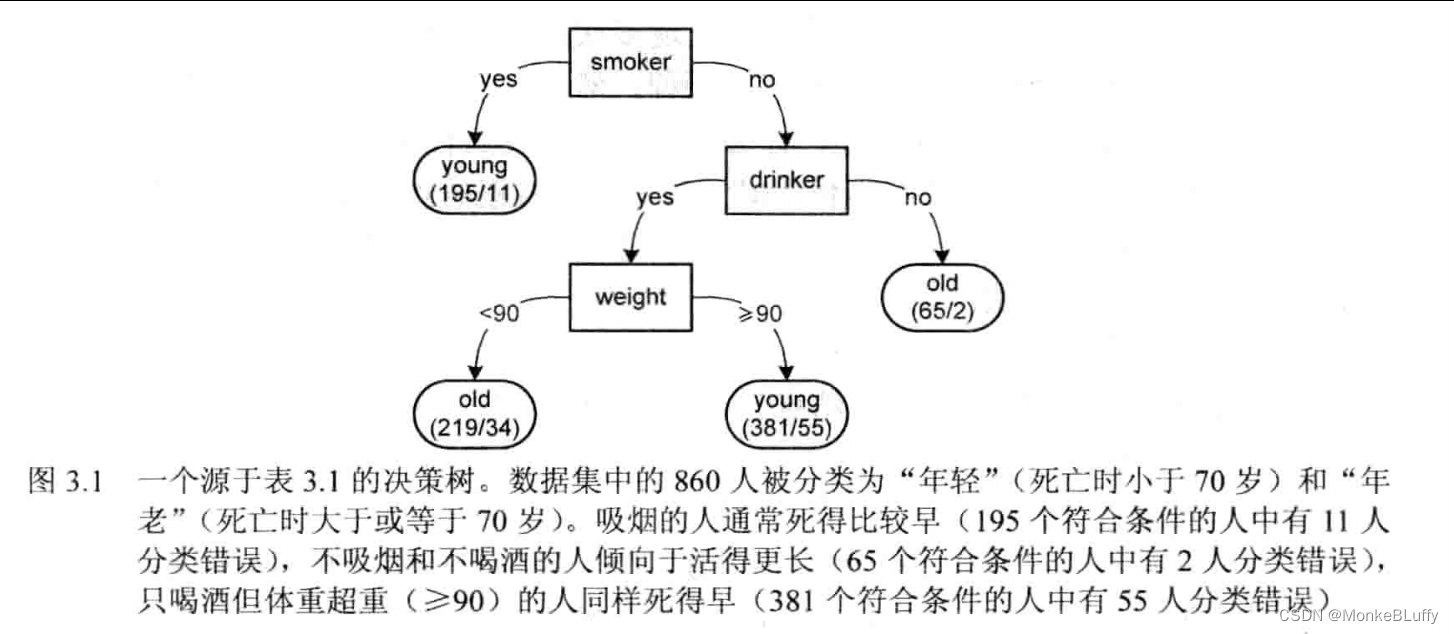
另外两棵决策树可以用同样的方式解读。基于一个属性,一个实例集也可以被分裂为3个(或更多)子集。一个属性可以在树中出现多次,但不能在同一路径上出现两次。例如,在图3.2中,有两个结点涉及线性代数课程,然而它们并不在同一条路径上,因此对应于不相交的学生集合。如上文所述,针对具体语义,我们有许多处理缺失值的方法。在图3.2中,我们将缺失的课程成绩当作“0”(参见图中从根结点引出的最左边的弧)。
如图3.1、图3.2和图3.3所示的决策树可以通过许多技术生成,大多数技术采用如下所述的自顶向下的递归算法:
- 生成根结点r,并将所有实例关联到根结点。X:={r}是需要转化的结点的集合;
- 如果X=Ø,返回树及其根结点r,算法结束;
- 选择x∈X,将其移出X,也就是X:=X{x}。计算结点x分裂前的评分,sold(x),比如可以基于熵进行评分;
- 决定分裂是否可能/必须。如果不需要分裂,则转到步骤(2),否则继续下一步;
- 对于所有可能的属性a∈A,评价基于该属性进行分裂的效果。选择具有最好改进效果的属性a,也就是说,最大化sanew(x)-sold(x)。同一个属性不能在由根结点发出的相同路径中出现多次。同时还要注意,对于数值型属性,需要决定所谓的“截止值”(即图3.2中的<8和≥8);
- 如果改进足够显著,创建新的子结点集Y,将Y加入X(即X:=XUY),并将x与Y中所有的子结点相连;
- 关联Y中的每个结点与其对应的实例集合,转至步骤(2)。
这里我们只介绍一种通用算法的粗略框架。设计一个具体的决策树学习算法需要许多设计时的决策。例如,我们需要决定何时停止增加结点,这可以通过评分函数的改进进行判断,也可以通过限制树的深度进行处理。同时,也存在许多不同的属性选择方式。这些方式可以基于熵(见下文)和Gini多样性指数等。当选择数值型数据进行分裂时,我们需要决定截止值,因为我们不可能为每一个可能值生成一个子结点。例如,一个客户可以点任意数量的拿铁,我们不希望在利用该属性进行分裂时列举所有的可能值。如图3.3所示,结点latte只含有3个子结点,基于两个截止值将自然数域分片为{0},{1}和{2,3,…}。
这些问题只是设计一个完整的决策树学习算法时,会遇到的众多问题中的一部分。关键是,通过将实例集合分裂为子集合,每个集合中的差异变得越来越少。这可以通过熵(entropy)的概念很好地进行描述。
3.3 k-means聚类
聚类关注将实例聚集到不同的类中,每一类中的实例彼此相似,而与其他类中的实例并不相似。聚类采用无标签数据,是一种无监督学习技术。存在许多聚类算法,此处我们关注k-means聚类。
图3.5展示了聚类的基本思想。假设我们有一个数据集,它只含有两个变量:age和weight。这样的数据集可以通过截取表3.1的最后两列来获得。图中的点对应于特定年龄和体重的人。通过诸如k-means的聚类技术,可以发现图3.5右图所示的3个类别。理想情况下,每个类别中的实例接近于该类别的其他实例,而远离其他类别中的实例。每个类别含有一个用+标识的重心,即该类别的中心,可以通过计算该类别所有实例坐标的平均值获得。注意图3.5只展示了两个维度,这可能有一些误导性,因为实际情况下往往具有许多维度(例如课程或产品的数量)。然而,这个二维视图有助于我们理解一些基本的思想。

基于距离的聚类算法,例如k-means和层次聚类,假定了一个距离的概念。最常见的方法是将所有实例考虑成为一个n维向量,其中n是变量的数目,并简单地采用欧几里得距离作为距离。为了这个目的,序数值和二元值需要被转化成数值,例如true=1,false=0,cum laude=2, passed=1, failed=0。注意在定义距离度量的时候,缩放的尺度非常重要。例如,一个变量代表从10到1000000米的范围,而另一个变量代表0.2~0.8之间的参数,那么前一个变量的影响会控制住后一个变量。因此,需要一些归一化的手段。
图3.6展示了k-means算法的基本思想。这里我们尽可能地简化问题,令k=2,并且只含有10个实例。算法始于一个随机初始化的用两个+表示的重心。在图3.6(a)中,重心被随机地放置到二维空间中。采用选定的距离度量,所有的实例分别被分配给离它最近的重心。这里,我们采用标准欧几里得距离。所有用空心圆点标识的实例被分配给左边的重心,所有用实心圆点标识的实例被分配给右边的重心。基于这一分配,我们得到了两个初始的聚类。现在我们可以为每个聚类计算它们的实际中心。这将产生两个新的重心。图3.6(b)中,我们再次将所有实例分配到最近的重心。这将生成图3.6(b)所示的两个新聚类。所有用空心圆点表示的实例分配到一个重心,所有用实心圆点表示的实例分配到另一个重心。现在我们计算这两个新聚类的真实中心,这将生成如图3.6©新的重心。我们再次将实例分配到最近的重心上。然而,新的分配没有发生任何变化,重心的位置保持不变。汇聚过程结束后,k-means算法输出两个聚类和相关统计数据。
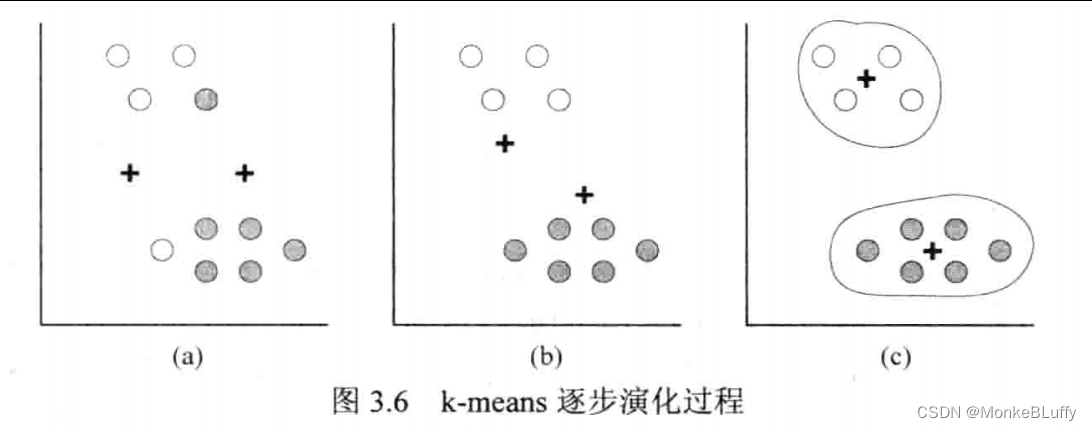
一个特定聚类算法的质量可以通过所有实例到对应重心的距离的平均值来定义。k-means聚类只是一种启发式的算法,并不能保证得到实例到对应重心平均距离最小的k个聚类。事实上,聚类结果依赖于初始化时的情况,因此最好用不同的初始化条件重复执行该算法,选出最佳的结果。
使用k-means时的一个问题在于确定类别数量k。对于k-means算法而言,k值从一开始就是固定的。注意实例到对应图心的平均距离随着k的增大而减小。在极端的情况下,每个实例单独聚为一类,此时实例到对应重心的平均距离为0。这种情况用处不大。因此,一种常用的方法是从较小的聚类数开始,逐渐增大k值,直到没有显著的改进。
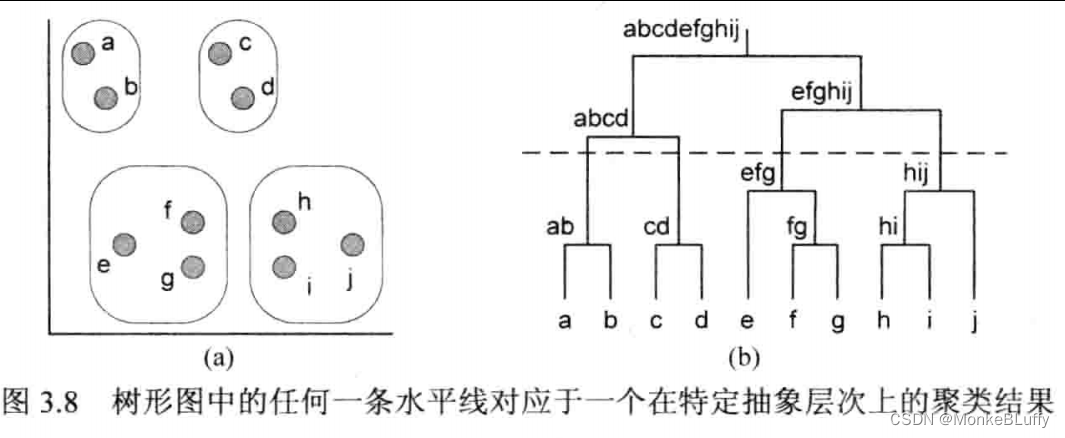
另一种常用的聚类技术是AHC(Agglomerative Hierarchical Clustering,层次聚类)。层次聚类生成一个可变的聚类数。图3.7展示了该方法的基本思想。层次聚类工作如下:先将每个实例单独分配到一个类别中。开始搜寻最接近的两个分类,将这两类合并成一个新的聚类。例如,最初的聚类只含有a和b,将它们合并为ab。此后再次搜索两个最接近的聚类并合并。这一过程重复进行,直到所有实例都被合并到同一聚类中。图3.7(a)展示了所有中间聚类,即除了最初的单实例聚类和最后的全实例聚类外的所有聚类情况。由于层次聚类的层次特性,我们可以通过如图3.7(b)的系统树形图直观表示聚类结果。
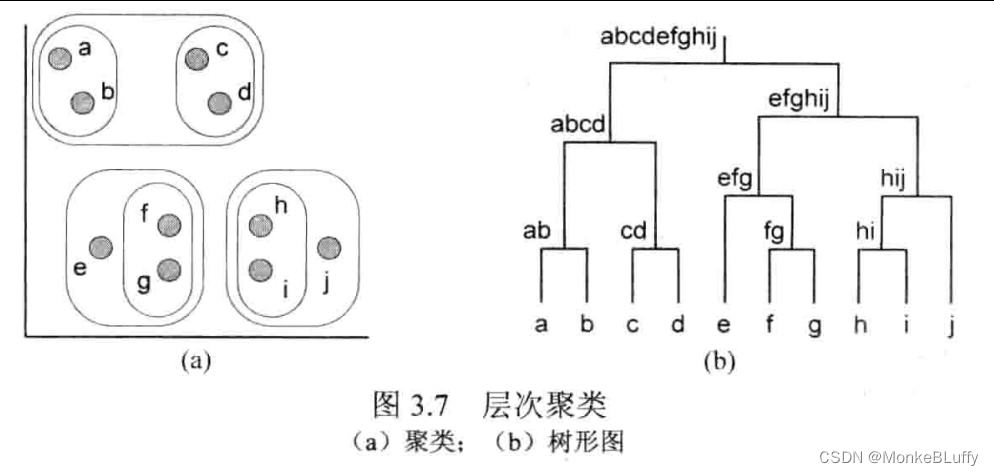 任意一条穿过树形图的水平线对应于一个确定的聚类结果。例如,图3.8(b)展示了这样的一条水平线,该水平线对应的聚类结果在图3.8(a)中展示。将该水平线移至系统树形图的底部,会生成许多单实例聚类。将该水平线上移,会产生一个包含所有实例的单一聚类。通过移动水平线,用户可以改变抽象层次。
任意一条穿过树形图的水平线对应于一个确定的聚类结果。例如,图3.8(b)展示了这样的一条水平线,该水平线对应的聚类结果在图3.8(a)中展示。将该水平线移至系统树形图的底部,会生成许多单实例聚类。将该水平线上移,会产生一个包含所有实例的单一聚类。通过移动水平线,用户可以改变抽象层次。
聚类只是间接地与第1章描述的过程发现问题相关联。然而,聚类可以被用作过程挖掘的预处理步骤。通过将相似的案例进行分组,我们可以构造易于理解的局部过程模型。如果发现的针对所有案例的过程模型过分复杂难以理解,那么先确定聚类,再针对每个聚类发现简化的模型,可能会有所帮助。