文章信息
- 作者:梁小平,唐振军
- 期刊:ACM Trans. Multimedia Comput. Commun. Appl(三区)
- 题目:Robust Hashing via Global and Local Invariant Features for Image Copy Detection
目的、实验步骤及结论
目的:通过全局和局部提取特征来生成最终图像的哈希值。
实验步骤:
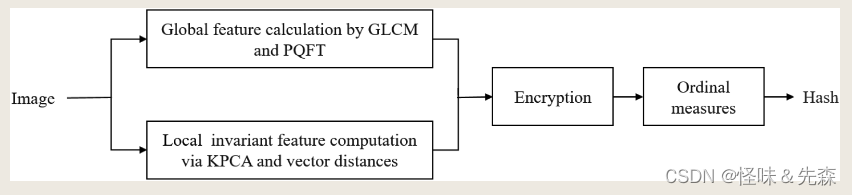
- 数据预处理:双线性插值(512 * 512)
- 全局特征:
- PDFT生成显著图S
- 对GLCM使用四种参数(不同的角度)得到四个矩阵,每个矩阵得到4个统计特征,得到 1 * 16 的全局特征向量
- 局部特征:
- 使用HSV中的V分量,分块(64 * 64),将每一个块拼接成一个列向量,使用KPCA后得到d * N的矩阵。
- 计算每一个矩阵维度的均值作为参考向量,计算所有向量(每一列)和参考向量的距离作为局部特征
- 生成哈希值:将全局特征和局部特征进行拼接,使用量度排序作为最后的哈希值(长度为N+16)。
- 相似性评价:使用汉明距离判断两张图片是否一致,若小于阈值则是相同图片。
结论
- 首次提出KPCA应用于图像哈希
- 适用于混合攻击
- 全局特征对几何攻击(尤其是缩放和旋转)很敏感,而局部特征无法保持全局上下文信息导致判别效果不佳。
- 使用全局和局部结合特征可以更加有利于互补进行提取特征。
本篇论文的实现代码如下:
def image_hash(img_path):
img = processing(img_path)
global_feature = global_feature_gen(img)
local_feature = local_feature_gen(img, 10000, 4)
h_i = gen_hashing(global_feature, local_feature)
return h_i
def processing(img_path):
"""
input:图片的路径
output:处理后的RGB图片
"""
try:
img = cv2.imread(img_path)
x = img.shape[0]//2 # 高度
y = img.shape[1]//2 # 宽度
Min = x if x<y else y
cropped_image = img[x-Min:x+Min, y-Min:y+Min] # 裁剪图像
img = cv2.resize((cropped_image), (512,512), interpolation=cv2.INTER_LINEAR)
except:
img = imageio.mimread(img_path)
img = np.array(img)
img = img[0]
img = img[:, :, 0:3]
x = img.shape[0]//2 # 高度
y = img.shape[1]//2 # 宽度
Min = x if x<y else y
cropped_image = img[x-Min:x+Min, y-Min:y+Min, :] # 裁剪图像
img = cv2.resize((cropped_image), (512,512), interpolation=cv2.INTER_LINEAR)
# out = cv2.GaussianBlur(img, (3, 3),1.3) # 使用python自带的高斯滤波
kernel = np.array([[1,2,1],[2,4,2],[1,2,1]])/16
out = cv2.filter2D(img, -1 , kernel=kernel) # 二维滤波器
# out = cv2.cvtColor(out, cv2.COLOR_BGR2RGB)
out = cv2.cvtColor(out, cv2.COLOR_BGR2HSV)
return out
def local_feature_gen(img, sigma, n_components):
"""
iamge:(512,512,3)
return: 降维之后的图像(d, N)
"""
from sklearn.decomposition import PCA, KernelPCA
N_list = []
V = img[:,:,2]
for i in range(0,V.shape[0],64):
for j in range(0,V.shape[1],64):
image_block = V[i:i+64, j:j+64]
N_list.append(image_block.reshape(-1)[:])
N_list = np.array(N_list).copy()
# kernel_pca = KernelPCA(n_components=4, kernel="poly", gamma=10)
# result = kernel_pca.fit_transform(N_list)
result = kpca(N_list, sigma, 4).copy()
return result.T
def gaussian_kernel(X, sigma):
sq_dists = pdist(X, 'sqeuclidean') # 计算所有样本点之间的平方欧式距离
mat_sq_dists = squareform(sq_dists) # 转换成矩阵形式
return np.exp(-mat_sq_dists / (2 * sigma**2)) # 计算高斯核矩阵
def kpca(X, sigma, n_components):
# 步骤1: 计算高斯核矩阵
K = gaussian_kernel(X, sigma)
# 步骤2: 中心化核矩阵
N = K.shape[0]
one_n = np.ones((N, N)) / N
K = K - one_n.dot(K) - K.dot(one_n) + one_n.dot(K).dot(one_n)
# 步骤3: 计算特征值和特征向量
eigenvalues, eigenvectors = eigh(K)
eigenvalues, eigenvectors = eigenvalues[::-1], eigenvectors[:, ::-1] # 降序排列
# 步骤4: 提取前n个特征向量
alphas = eigenvectors[:, :n_components]
lambdas = eigenvalues[:n_components]
return alphas / np.sqrt(lambdas) # 归一化特征向量
def global_feature_gen(img):
P = pqft(img)
return P
def pqft(img, sigma=8):
h, w, channel = img.shape
r, b, g = img[:,:,0], img[:,:,1], img[:,:,2]
R = r - (g + b)/2
G = g - (r + b)/2
B = b - (r + g)/2
Y = (r + g)/2 - (abs(r - g))/2 - b
RG = R - G
BY =B - Y
I1 = ((r+g+b) /3)
M = np.zeros((h, w))
f1 = M + RG * 1j
f2 = BY + I1 * 1j
F1 = np.fft.fft2(f1)
F2 = np.fft.fft2(f2)
phaseQ1 = np.angle(F1)
phaseQ2 = np.angle(F2)
ifftq1 = np.fft.ifft2(np.exp(phaseQ1 * 1j))
ifftq2 = np.fft.ifft2(np.exp(phaseQ2 * 1j))
absq1 = np.abs(ifftq1)
absq2 = np.abs(ifftq2)
squareq=(absq1+absq2) * (absq1+absq2)
out = cv2.GaussianBlur(squareq, (5, 5), sigma)
out = cv2.normalize(out.astype('float'), None, 0, 255, cv2.NORM_MINMAX)
return out
def gen_hashing(global_feature, local_feature):
"""
先求出列均值,在算出每一列之间的距离,最后使用序数度量来代表哈希值
input:array (x,64,64)
output:list (x)
"""
result = glcm(global_feature)
y_mean = np.mean(local_feature, axis = 0)
z = np.sqrt((y_mean[1:] - y_mean[:-1]) ** 2) * 1000
result.extend(z)
sorted_indices = sorted(range(len(result)), key=lambda i: result[i])
result = [sorted_indices.index(i)+1 for i in range(len(result))]
return result
def glcm(img, levels = 32):
'''
https://www.cnblogs.com/xiaoliang-333/articles/16937977.html
graycom = greycomatrix(img, [1], [0, np.pi/4, np.pi/2, np.pi*3/4], levels=256)
c = feature.greycoprops(graycom, 'contrast') # 对比度
d = feature.greycoprops(graycom, 'dissimilarity') # 相异性
h = feature.greycoprops(graycom, 'homogeneity') # 同质性
e = feature.greycoprops(graycom, 'energy') # 能量
corr = feature.greycoprops(graycom, 'correlation') # 相关性
ASM = feature.greycoprops(graycom, 'ASM') # 角二阶矩
'''
from skimage.feature import graycomatrix, graycoprops
img = img.astype(np.float64)
img = img * levels / 256.0
img = img.astype(np.uint8)
distances = [1, 1, 1, 1]
angles = [0, 45, 90, 135]
#初始化一个空列表来存储GLCM矩阵统计特征
glcms = []
#为每个距离和角度组合计算 GLCM
for d,a in zip(distances,angles):
glcm = graycomatrix(img,distances=[d],angles=[a],levels=levels,symmetric=True, normed=True)
contrast = graycoprops(glcm, 'ASM')
glcms.append(contrast[0, 0])
correlation = graycoprops(glcm, 'contrast')
glcms.append(correlation[0, 0])
energy = graycoprops(glcm, 'correlation')
glcms.append(energy[0, 0])
homogeneity = graycoprops(glcm, 'homogeneity')
glcms.append(homogeneity[0, 0])
# return np.array(np.round(glcms), dtype=np.uint8)
return glcms
def dist_img(h1,h2):
# distance = np.count_nonzero(np.array(list(h1)) != np.array(list(h2)))
# return distance / len(h1)
h1 = np.array(h1)
h2 = np.array(h2)
return sum(np.abs(h1-h2))/len(h1)