前言:
前面写了监督学习的几种算法,下面就开始无监督啦!
如果文章有错误之处,小伙伴尽情在评论区指出来(嘿嘿),看到就会回复的。
1.聚类(Clustering)
1.1 概述(Overview of clustering methods)

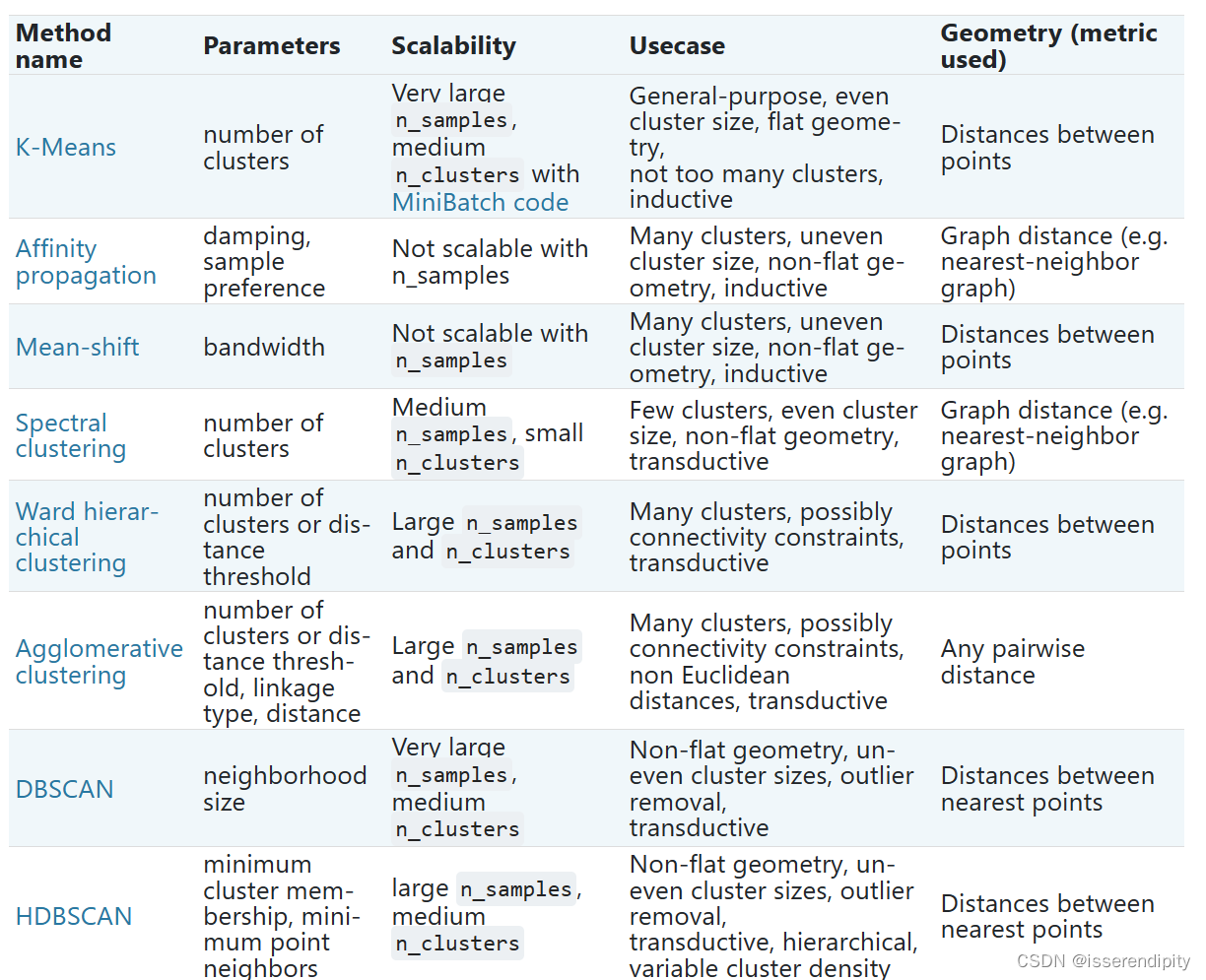
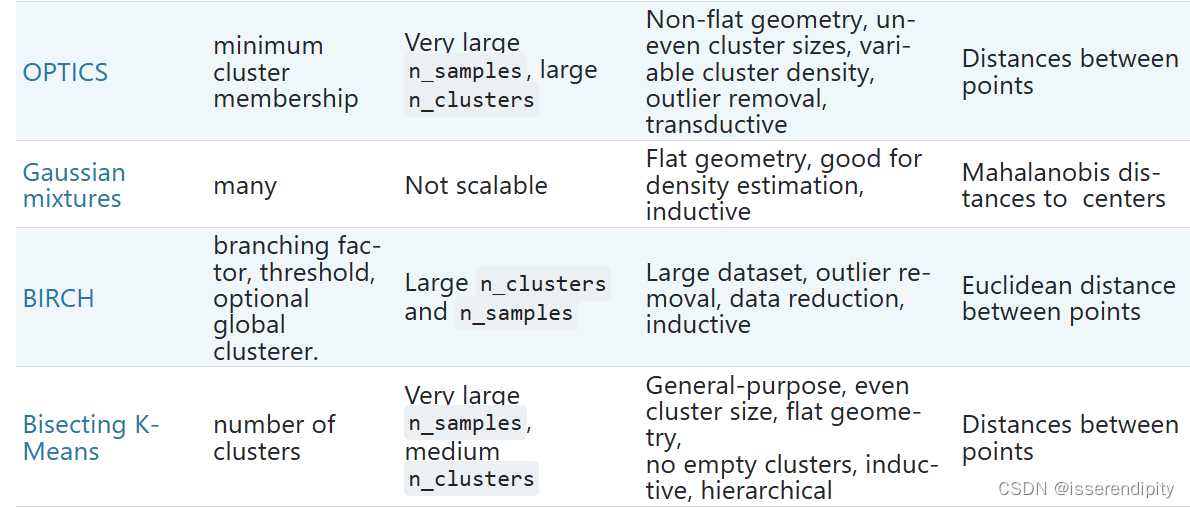
当这个类有一定形状(图的最上两行),即非平面流体,并且标准的欧式距离不是正确的度量标准时,聚类是非常有用的。
1.2 K-means
1.2.1 概念
通过把样本分离成 n 个具有相同方差的类的方式来对数据进行聚类,最小化一个称为惯量或簇内平方和的准则(见下文)。该算法需要指定簇的数量。它可以很好地扩展到大量样本,并已经在许多不同领域的应用领域被广泛使用。
注:簇和类应该是一样的概念,我们一同使用。
1.2.2 实现
是样本,
是簇心。下面是误差公式:
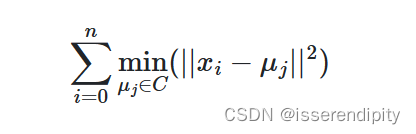
- 输入K和数据集N,tol(阈值)
- 随意初始化一个K个样本作为一个簇的中心(质心)
- 将离质心近的样本归为一类,计算簇內平方和误差
- 计算簇內均值更新质心
- 重复3,4步骤直到误差<tol或者到了最大循环次数,跳出循环,返回簇心
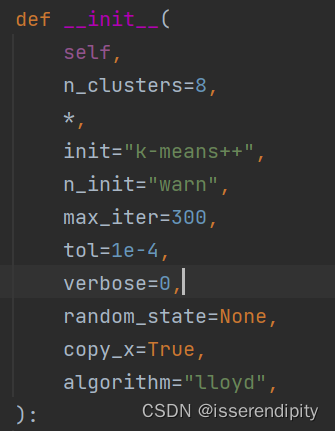
说明:
这个K-Mean需要调参(比悲伤更悲伤的事)
n_clusters(K值),
max_iter(最大收敛次数),
n_init(不同的初始化质心运行算法的次数,一般不需要修改,默认是10,如果你的K值较大,可以适当增大),
algorithm:有“auto”, “full” or “elkan”三种选择。"full"就是传统的K-Means算法, “elkan”是elkan K-Means算法。默认的"auto"则会根据数据值是否是稀疏的,来决定如何选择"full"和“elkan”。一般数据是稠密的,那么就是 “elkan”,否则就是"full"。一般来说建议直接用默认的"auto"
1.2.3 代码
import matplotlib.pyplot as plt
import mpl_toolkits.mplot3d
import numpy as np
from sklearn import datasets
from sklearn.cluster import KMeans
np.random.seed(5)
iris=datasets.load_iris()
x=iris.data #4个特征
y=iris.target
estimators=[
('K_means_iris_8',KMeans(n_clusters=8)),
('K_means_iris_3',KMeans(n_clusters=3)),
('K_means_iris_bad_init',KMeans(n_clusters=3,n_init=1,init='random')),
]
fig=plt.figure(figsize=(10,8)) #指定宽高:画一个1500*1200的图
titles=["8 clusters","3 clusters","3 clusters,bad initialization"]
for idx,((name,est),title) in enumerate(zip(estimators,titles)): #使用每个不同 的方法进行训练和画图
ax=fig.add_subplot(2,2,idx+1,projection="3d",elev=48,azim=134)
est.fit(x)
labels=est.labels_
ax.scatter(x[:,3],x[:,0],x[:,2],c=labels.astype(float),edgecolor='k') #取了三个特征进行画图
ax.xaxis.set_ticklabels([])
ax.yaxis.set_ticklabels([])
ax.zaxis.set_ticklabels([])
ax.set_xlabel('Patel width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Patel length')
ax.set_title(title)
ax=fig.add_subplot(2,2,4,projection='3d',elev=48,azim=134) #增加一个子图
for name,label in [("Setosa", 0), ("Versicolour", 1), ("Virginica", 2)]:
ax.text3D(
x[y==label, 3].mean(), ###x[y==label, 3]中间有个空格,我找了半个小时!!!
x[y==label, 0].mean(),
x[y==label, 2].mean()+2,
name,
horizontalalignment="center",
bbox=dict(alpha=0.2,edgecolor='w',facecolor='w'),
)
ax.scatter(x[:,3],x[:,0],x[:,2],c=y,edgecolor='k')
ax.xaxis.set_ticklabels([])
ax.yaxis.set_ticklabels([])
ax.zaxis.set_ticklabels([])
ax.set_xlabel("Petal width")
ax.set_ylabel("Sepal length")
ax.set_zlabel("Petal length")
ax.set_title("Ground Truth")
plt.subplots_adjust(wspace=0.25,hspace=0.25)
plt.show()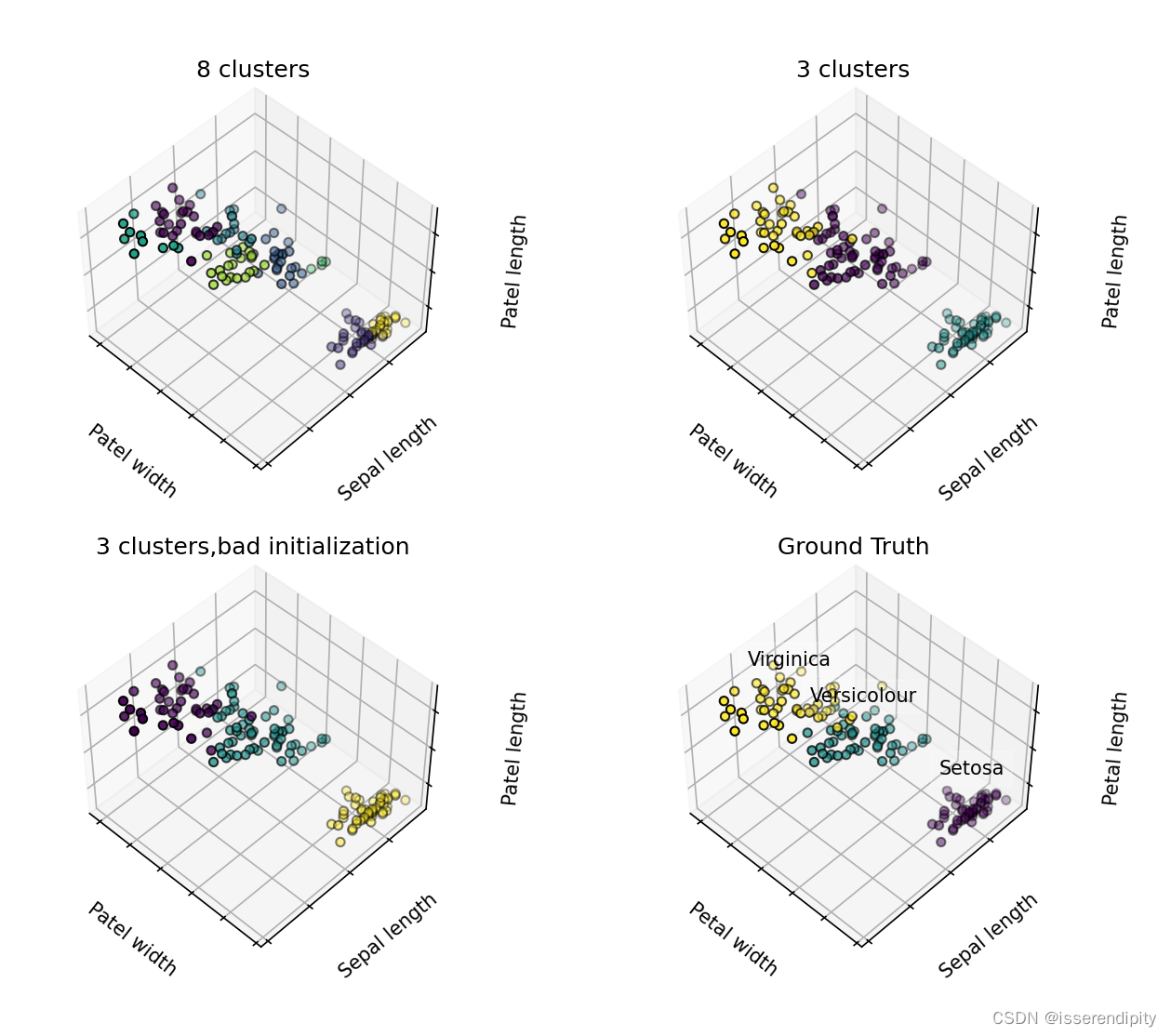
总结:
从上图中可以看出,K值很大影响了这个簇分的好不好,所以这个很重要。下面这个n_init比上面那个要差一点,是因为值太小了。
模型好坏跟参数太息息相关啦!!!
1.2.4 拓展
Mini Batch K-Means:
这个和K-Means差不多,只是每次取小批量的数据进行训练。这些小批量极大减少了收敛到局部解所需的计算量。 与其他降低 k-means 收敛时间的算法相比,小批量 k-means 产生的结果一般只比标准算法略差。
1.3 AP聚类算法(Affinity propagation)
1.3.1 引入
概念:
通过在不同点之间不断的传递信息,从而最终选出聚类中心,完成聚类。
优点:
- 不需要指定最终聚类族的个数
- 已有数据点作为最终的聚类中心,而不是新生成一个族中心
- 模型对数据的初始值不敏感
- 对初始相似度矩阵数据的对称性没有要求
- 相比与K-centers聚类方法,其结果的平方差误差较小
1.3.2 实现

好啦,后面有时间再填一些算法。
欢迎大家点赞,收藏!