1 概述
词法分析(lexical analysis),也称scanning, 编译程序的第一阶段,其作用是识别单词(程序意义上)并找出词法错误. 读入源程序的输入字符、将它们拆分成词素,生成并输出一个词法单元序列,每个词法单元对应于一个词素
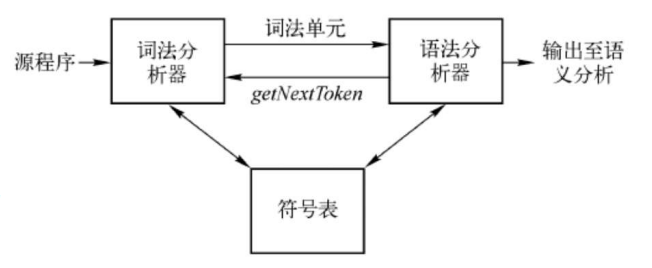
回顾词法分析在整个编译过程的位置
![[【笔记】编译原理L1#^53d248| 回顾编译原理的各个模块顺序]]
1.1 词法分析的常见做法
- 由语法分析器调用,需要的时候不断读取、生成词法单元。这样可以避免额外的输入输出。
- 词法分析可以使用:[[【笔记】编译原理L2:词法分析(lexical analysis)#3.2 正则表达式 | RE]] 和 [[【笔记】编译原理L2:词法分析(lexical analysis)#3.4 正则语言(RL)| RL]]
Note:在识别出词法单元之外,还会完成一些不需要生成词法单元的简单处理,比如删除注释、将多个连续的空白字符压缩成一个字符等
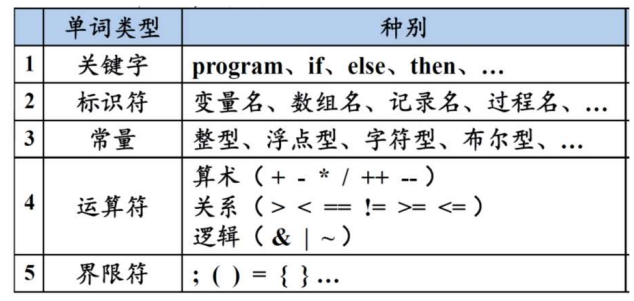
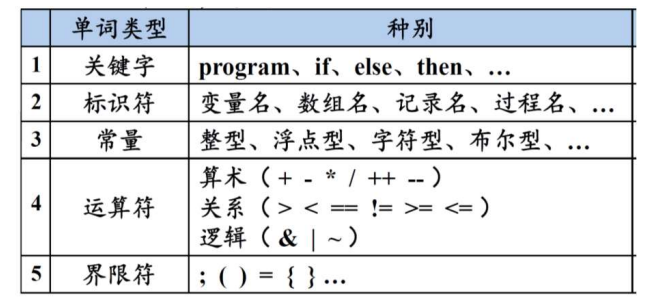
1.2 一些经典名词
| 词素(Lexeme) | 词法单元 (Token) <词法单元名、属性值(可选)> | 词性划分 |
|---|---|---|
| 源程序中的字符序列,它和某类词法单元的模式匹配,被词法分析器识别为该词法单元的实例。 | 单元名是表示词法单位种类的抽象符号,语法分析器通过单元名即可确定词法单元序列的结构, 是有意义的最小的程序单位。属性值通常用于语义分析之后的阶段 |
根据作用对程序子串进行分类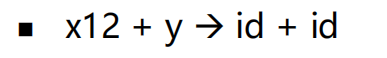 |
- 词法分析的输出是单词(token)的序列<词法单元名、属性值(可选)>:
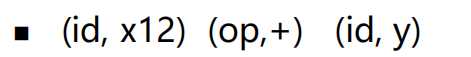
- Token序列将作为语法分析程序的输入:
- 一个具体的示例:

2 语言的定义
2.1 什么是语言
- 作用:沟通,交流,传递信息
- 自然语言:英语,中文,日语
2.2 你如何定义语言?
- 无限的集合
- 抽象地来看:字符组成了单词; 单词组成了句子; 句子携带了信息
- 语言是形式化的内容提取——单词、句子、语言:是三种不同的语言
| 单词(Token) | 句子(Sentence) | 语言(Language) |
|---|---|---|
| 满足一定规则的字符(Character)串 | 满足一定规则的单词序列 | 满足一定条件的句子集合 |
示例:程序设计语言:形式化的内容提取
| 程序设计语言(Programming Language) | 程序(Program) | 语句(Sentence) | 单词(Token) |
|---|---|---|---|
| 组成程序的所有语句的集合。 | 满足语法规则的语句序列 | 满足语法规则的单词序列。 | 满足词法规则的字符串 |
语言是字和组成字的规则
“doge”(it’s not a word ): reserved words and some rules forwords (词法)
“Long time no see”(It’s not a correct sentence): rules forsentences(语法)
检查单词错误是词法负责的范畴,检查句子错误是语法负责的范畴语言是用有限的规则来描述的无限集
语言的组成部分
| 符号 (Symbol/Character) | 字母表 | 符号串(字符串) |
|---|---|---|
| 语言中不可再分的单位 | 符号的非空有穷集合,Σ,V或其它大写字母, 其中的元素可称为字母、符号、字符。例如:V1 = {a, b, c}, V2 = {+, -, 0, 1, …,9}, Σ= {x|x∈ASCII字符} | 某字母表上的符号的有穷序列。a, b, c, abc, bc,…:V1上的符号串; 1250, +2, -1835,…:V2上的符号串。空串(ε):不含任何符号的串 |
- 语句: 字母表上符合某种构成规则的符号串序列。
- 语言 L:某字母表上的语句的集合: L(Σ); 注意:定义在同一个字母表上的语言有很多!
比如:Σ定义了语言中允许出现的全部符号;若Σ = 英文字母,L(Σ)是英文句子, 若Σ = ASCII字符, L(Σ)可以定义成C语言程序,但也可以定义成Java程序或者其他的程序语言,这里就可以构成多种语言。(此现象产生的原因:L(Σ)是字符串集合,但不是包含Σ上任意的字符串,而是满足某种规则的字符串——引出了我们要如何定义规则?)
2.3 如何定义规则
文法(G, Grammar): 四元组G = ( V N V_{N} VN , V T V_{T} VT , S S S, P P P ),其中:
| V N V_{N} VN | V T V_{T} VT | S S S | P P P |
|---|---|---|---|
| 一个非空有限的非终结符号集合,它的每个元素称为非终结符,一般用大写字母表示,它是可以被取代的符号; | 一个非空有限的终结符号集合,它的每个元素称为终结符,一般用小写字母表示, 是一个语言不可再分的基本符号 | 一个特殊的非终结符号,称为文法的开始符号或识别符号, S S S ∈ V N V_{N} VN, 开始符号S必须至少在某个产生式的左部出现一次; |
产生式的有限集合。所谓的产生式,也称为产生规则或简称为规则,是按照一定格式书写的定义语法范畴的文法规则。词法、语法都是这样定义的 |
- 描述形式——文法
- 语法——语句:语句的组成规则。描述方法:BNF范式、产生式
- 词法——单词:单词的组成规则。描述方法:BNF范式、产生式、正规式
[!Note]- 文法示例
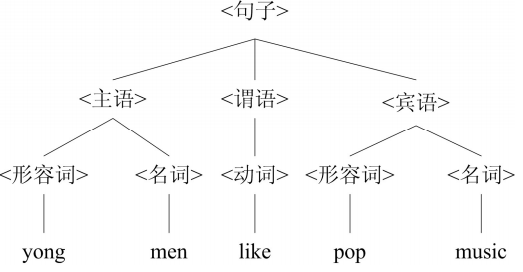
(1)自然语言文法示例:
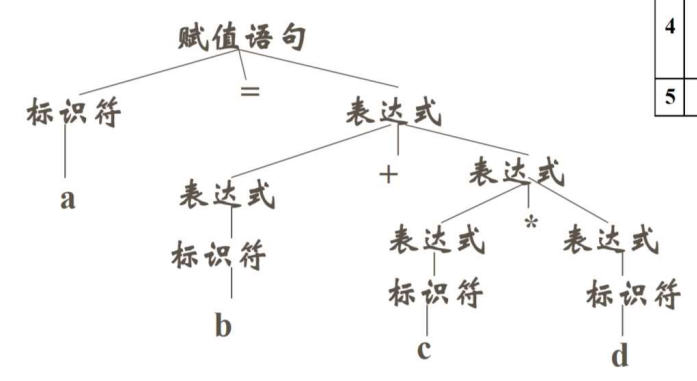
(2) 程序语言文法示例:


文法规则的递归定义:
- 非终结符的定义中包含了非终结符自身
- 设Σ={0,1}; <整数>-><数字><整数>|<数字>; <数字>->0 | 1
- 使用递归定义时要谨慎,要有递归出口,否则可能永远产生不出句子
扩充的BNF表示

2.4 符号串的基本概念
| 符号串连接 | 符号串方幂 | 符号串前缀后缀 | 符号串子串 | 符号串子序列 |
|---|---|---|---|---|
| x和y的连接xy是把y的所有符号顺序地接在x的符号之后所得到的符号串 | 设x是字母表∑上的符号串,把x自身连接n次得到的符号串z, 即z = xx…xx(n个x),称作符号串x的n 次幂,记作 z = x n z = x^{n} z=xn | 设x、y、z是某一字母表上的符号串,x = yz,则y是x 的前缀,z 是x的后缀; z≠ε 时y是x的真前缀, y≠ε时z 是 x 的真后缀 | 非空字符串x,删去它的一个前缀和一个后缀后所得到的字符串称为 x 的子字符串,简称子串。如果删去的前缀和后缀不同时为ε,则称该子串为真子串 | 从s中删去零或多于零个符号(这些符号不要求连续),这里也体现了符号串子串是要求连续的。 |
| 符号串逆转(用SR表示) | 符号串长度 | 符号串集合(语言)的积 | 字符串集合(语言)的方幂 |
|---|---|---|---|
| 将S中的符号按相反次序写出而得到的符号串 | 是该符号串中的符号的数目。例如|aab|=3,|ε|=0 | 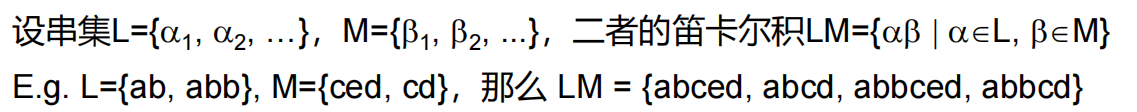 |
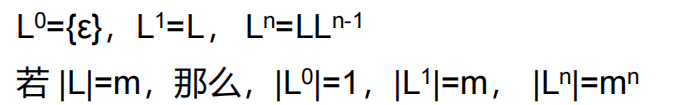 |
| 字符串集合(语言)的Kleene闭包 | 字符串集合(语言)的正闭包 |
|---|---|
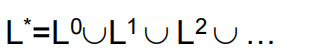 |
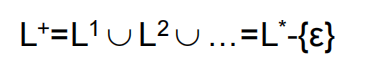 |
| **语言L(Σ)就是其字母表(把字母表看作是由 | Σ |
3 正则文法
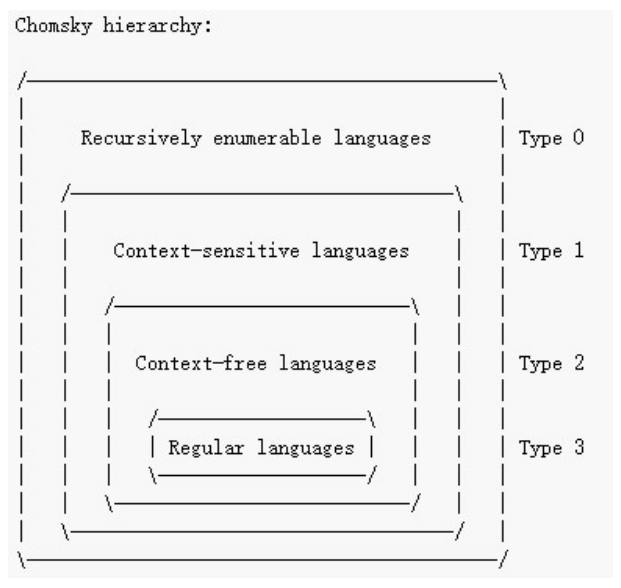
3.1 Chomsky 3型文法:正规(正则)文法
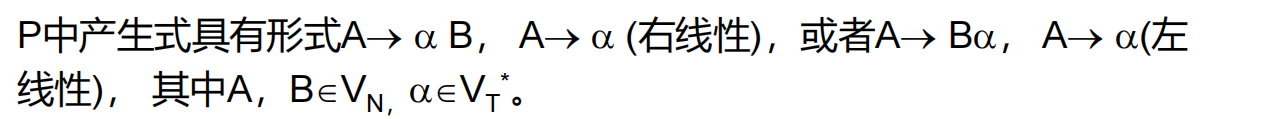
也称为正规文法RG、线性文法:若所有产生式均是左线性,则称为左线性文法;若所有产生式均是右线性,则称为右线性文法。
注意:产生式要么均是右线性产生式,要么是左线性产生式,不能既有左线性产生式,又有右线性产生式。
3.2 正则表达式
- 定义正则语言(regular languages, RL)的标准工具
- 其定义的集合叫做正则集合(regular set)
- 是词法单元的规约
- 识别3型语言的自动机称为有限状态自动机(FA)。
3.2.1 正则表达式中的四种运算的作用
| 括号® | 或运算 | | 连接运算 · | *运算 |
|---|---|---|---|
| 不改变r表示,主要是用于确定运算优先关系 | 表示“或”关系 | 表示连接,经常省略,如r·s也可表示为rs | r*表示对r所描述的文本进行0到若干次循环连接 |
3.2.2 定义正则表达式

实际应用中也会扩充很多正则表达式的运算,比如:
r + r^{+} r+也是 ∑ \sum ∑上的正则表达式,表示的正则集 L ( r + ) = ( L ( r ) ) + L(r^{+}) = (L(r))^{+} L(r+)=(L(r))+.
+代表前面的字符至少出现一次,而*代表前面的字符可以不出现,也可以出现一次或者多次运算符的优先级:* > 连接符 > |, 示例:(a)|((b)*©) 可写为 a|b*c
正则表达式的作用和产生式等价
强调一下Σ的含义:表示的是语言中允许出现的全部符号
3.2.3 正则定义(类似define)
给正则表达式起个名字,避免过长的RE定义
示例:定义整数的正则表达式:
Digit = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Integer = Digit+
理解:有点像C++中的宏定义define,可以简化表达。
3.2.4 正则文法示例(邮箱地址)

PS: 在使用regular识别工具时,.需要转义。另外,可以有一些简化写法,例如使用^和$识别开头结尾
3.2.5 正则表达式运算的性质

3.3 正则表达式和正则文法的关系
两者等价,可以互相转化
3.4 正则语言(RL)
概念:正则语言(regular language, RL):可用一个正则表达式定义的语言叫做正则语言, 一般地,程序设计语言的单词是正则语言,可用RE定义
正则表达式局限性:RE 不能定义具有对称结构和嵌套结构的语言

4 有限状态自动机
4.1 有限状态自动机概述
正则表达式 – specification(便于书写理解);有限自动机 –Implementation(便于计算机执行)。有限自动机是描述有限状态系统的数学模型. 在很多领域,如网络协议分析、形式验证、代码安全、排版系统等有重要应用。
[!info]- 什么是有限系统?
状态:是将事物区分开的一种标识
具有离散状态的系统:如数字电路(0,1);电灯开关(on,off);十字路口的红绿灯;其状态数是有限的。
具有连续状态的系统:水库的水位、室内的温度等可以连续发生变化;可以有无穷个状态.
有限状态系统是离散状态系统。
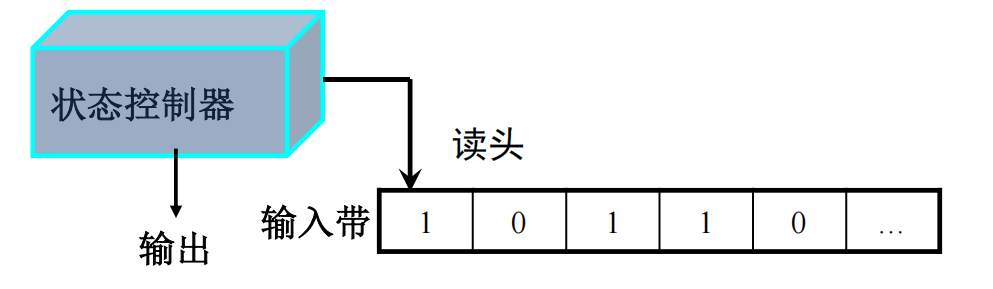
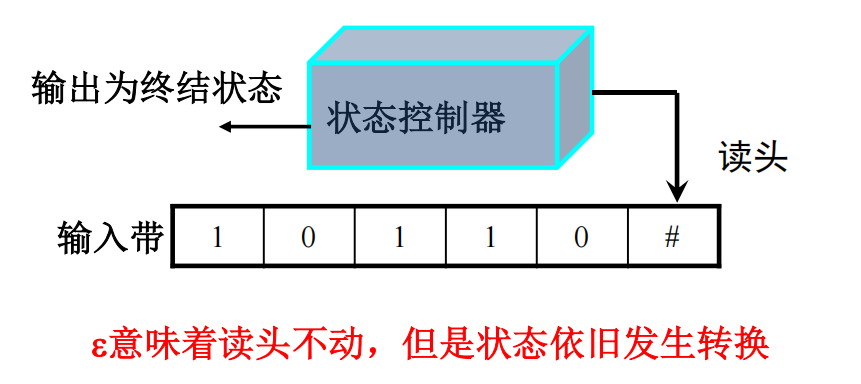
有限自动机FA可以理解成状态控制器:
- FA有有限个状态,其中有初始状态,终止状态
- 起始:处于初始状态,读头位于输入带开头
- 中间:从左到右依次读取字符,发生状态迁移
- 结束:读头到达输入带末尾,状态到达终态
4.2 有限自动机例子——经典的过河问题
一个人带着一头狼,一头羊,以及一棵白菜处于河的左岸。人和他的伴随品都希望渡到河的右岸。有一条小船,每摆渡一次,只能携带人和其余三者之一。如果单独留下狼和羊,狼会吃羊;如果单独留下羊和白菜,羊会吃菜。怎样才能渡河,而羊和白菜不会被吃掉呢?
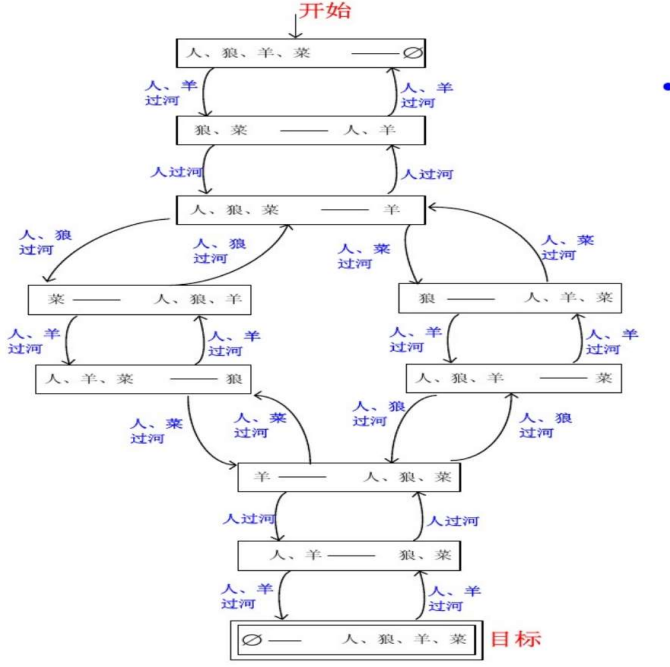
从图中找出初始状态到目标状态的一条有向路,就是这个问题的一个解
4.3 有限自动机的五要素
- 有限状态集 SS — 结点
- 有限输入符号集 Σ
- 转移函数 δ ( s , a ) = t \delta (s,a) = t δ(s,a)=t
- 一个开始状态s0
- 一个终止状态集 TS
- 输入:字符串
- 输出:若输入字符串结束,且到达终止状态,则接受,否则拒绝
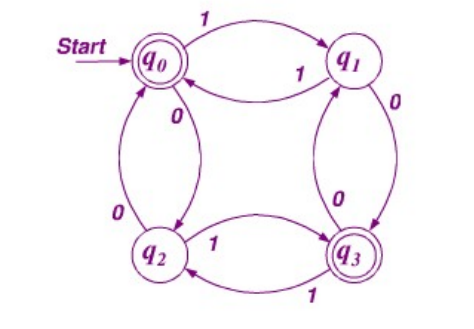
例如:“101” 输出拒绝,“1010”输出接受。
词法分析器在扫描输入串过程中,寻找和某个模式匹配的次数,转换图中每个状态代表一个可能在这个过程中出现的情况.
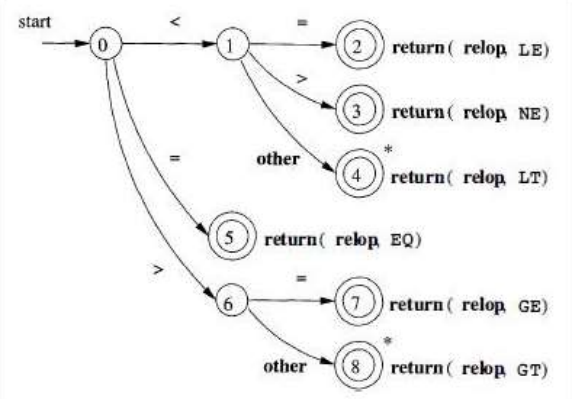
有穷自动机是识别器,只能对每个可能的输入串回答:是 或 否
4.4 确定有限自动机DFA

4.4.1 DFA的两种转换形式
状态转换图 :用有向图表示自动机,比较直观,易于理解;
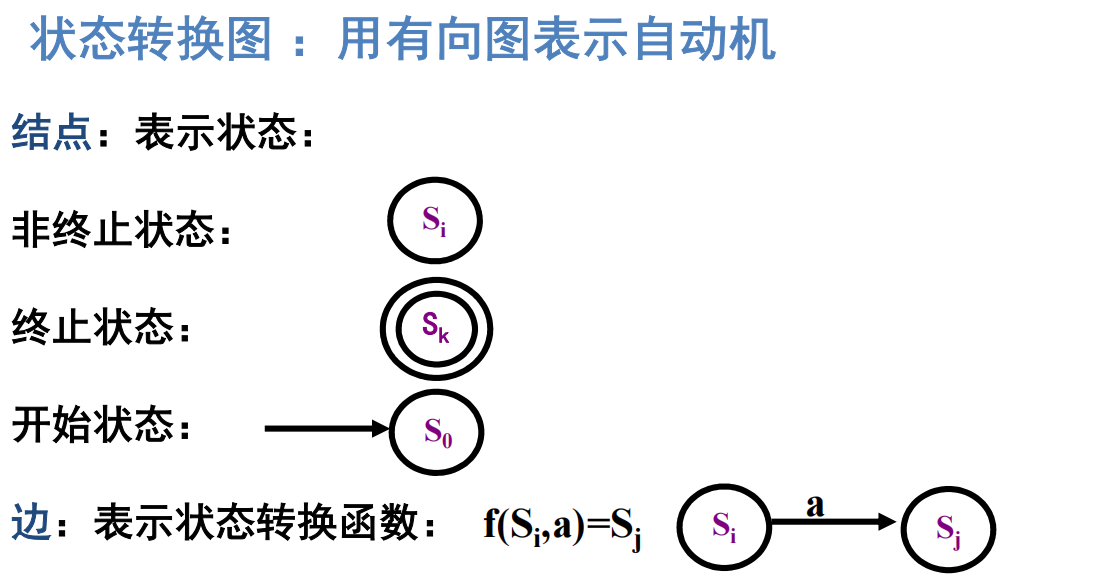
状态转换矩阵:用二维数组描述自动机,易于程序的自动实现;

转换表的优点是能够很容易地确定和一个给定状态和一个输入符号相对应的转换。缺点是如果输入字母表很大,且大多数状态在大多数输入字符上没有转换的时候,转换表要占用大量空间。
注意转换矩阵中,初始状态和终止状态需要用特殊符号表示。
4.4.2 DFA的确定性
- 形式定义
- 初始状态唯一:S0
- 转换函数是单值函数,即对任一状态和输入符号,唯一地确定了下一个状态
- 没有输入为 ε \varepsilon ε空边,即不接受没有任何输入就进行状态转换的情况。
- 转换表上的体现
- 初始状态唯一:第一行
- 表元素唯一
- 转换图上的体现
- 初始状态唯一:
- 每个状态最多发出n条边,n是字母表中字母的个数,且发出的任意两条边上标的字母都不同
4.4.3 DFA接受的字符串

DFA M接受的所有串的集合,称为M定义的语言,记为 L(M)
一些特殊情况:
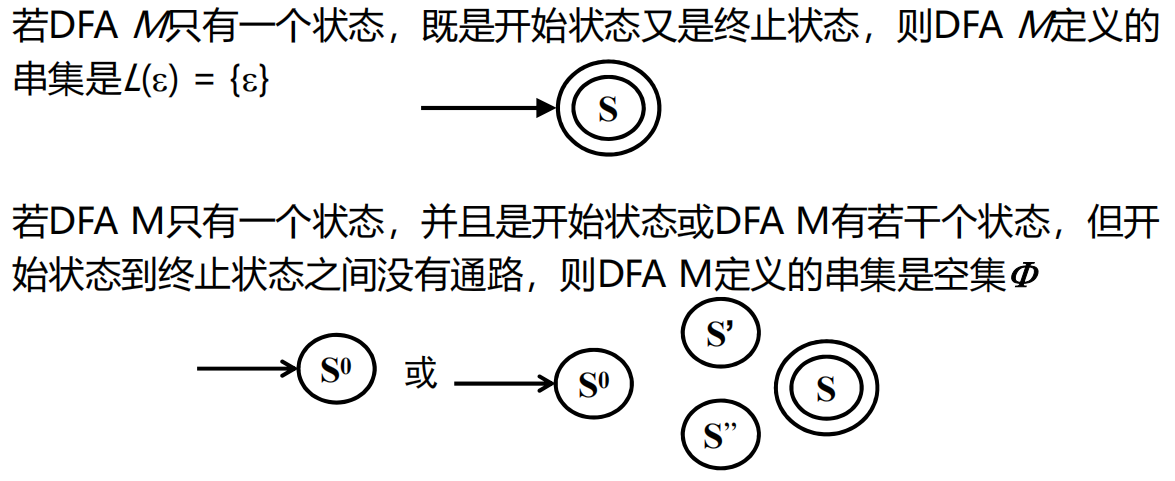
4.4.4 DFA的实现
| 转换表方式 | 转换图方式 |
|---|---|
| 是通用的算法,不同的语言,只需改变输入的转换表,识别程序不需改变 | 不需要存储转换表(通常转换表是很大的),但当语言改变即自动机的结构改变时,整个识别程序都需要改变 |
4.5 非确定有限自动机

与DFA的区别:不要求转化函数是单值函数。不过NFA也可以用状态转换图或状态转换矩阵表示
4.5.1 NFA接受的字符串

转换路径中的 ε \varepsilon ε将被忽略,因为空串不会影响构建得到的字符串,NFA所能接受的串与DFA是相同的,但NFA实现起来很困难, NFA M接受的所有串的集合,称为M定义的语言,记为 L(M)
4.6 NFA v.s. DFA
4.6.1 总体区别
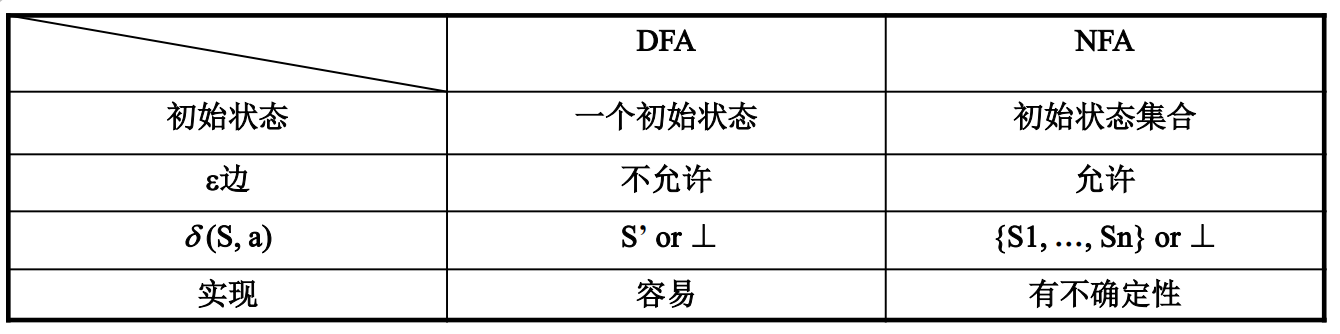
- 对于确定的输入串,DFA只有一条路径接受它
- NFA则可能需要在多条路径中进行选择!
- NFA和DFA都可以模拟RE,NFA可转换成DFA
4.6.2 两者接受的字符串(可以等价)
4.6.3 由NFA构造DFA
构造方法:
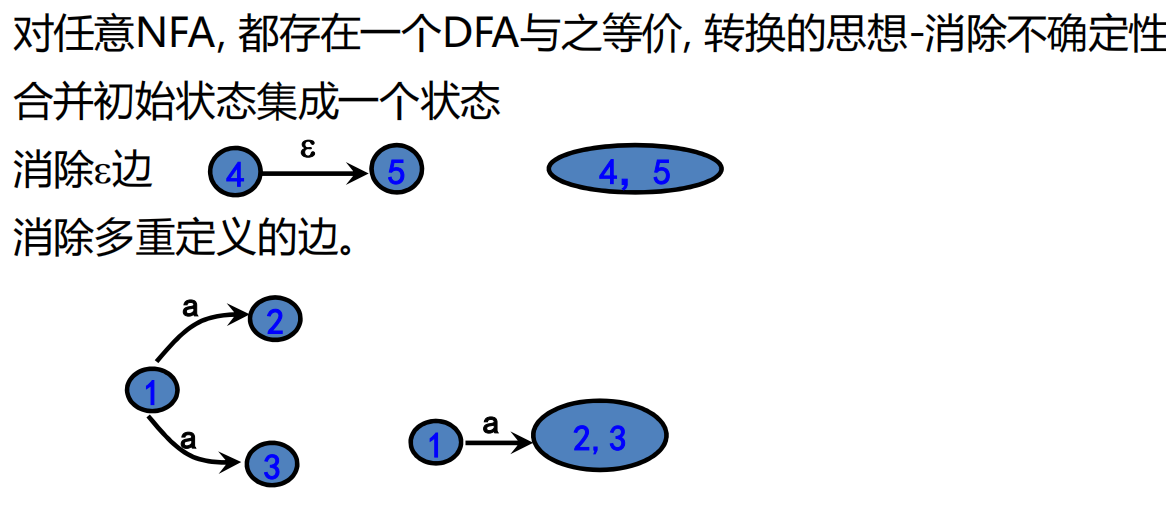
4.6.3.1 子集法

核心思想:找出当N读入某个输入串之后可能位于的所有状态集合
- ε \varepsilon ε-closure(T): 对于给定的 NFA A, 和它的一个状态集合 T, T的空闭包计算如下:


- Move(T, a):对于NFA N中的给定状态集合T和符号 a, Move(T, a) = {s | 对于状态集T中的一个状态s1, 如果A中存在一条从s1到s的a转换边}
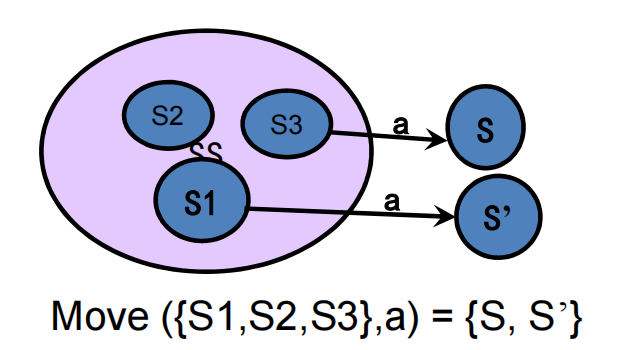
- 构造Dtran
- 我们需要找出当N读入了某个输入串之后可能位于的所有状态集合。
- 首先,在读入第一个输入符号之前,N可以位于集合 ε \varepsilon ε-closure(s0)中的任何状态上,其中s0是N的开始状态。下面进行归纳定义。
- 假定N在读入输入串x之后可以位于集合T中的状态上。如果下一个输入符号是a,那么N可以立即移动到move(T,a)中的任何状态。然而,N可以在读入a后再执行几个8转换,因此N在读入a之后可位于 ε \varepsilon ε-closure(move(T,a))中的任何状态上。
4.7 RE v.s. NFA/DFA
对∑上的每一个正则表达R,存在一个∑上的非确定有限自动机N,使得 L(N) = L®, N可以通过子集法得到与之等价的确定有限自动机D
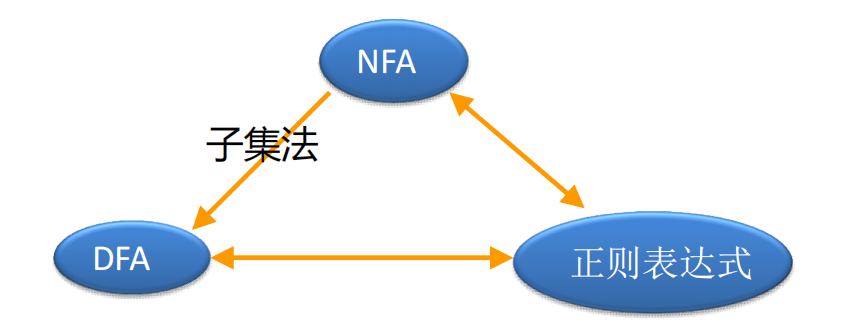
4.7.1 从RE生成FA,用来模拟RE的实现
方法一:RE -> NFA -> DFA -> 最小DFA

归纳规则:
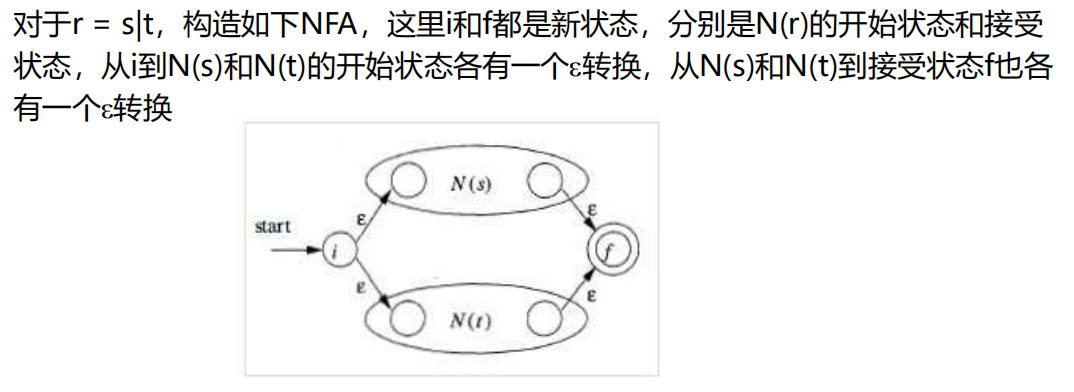
- 对于r = s | t
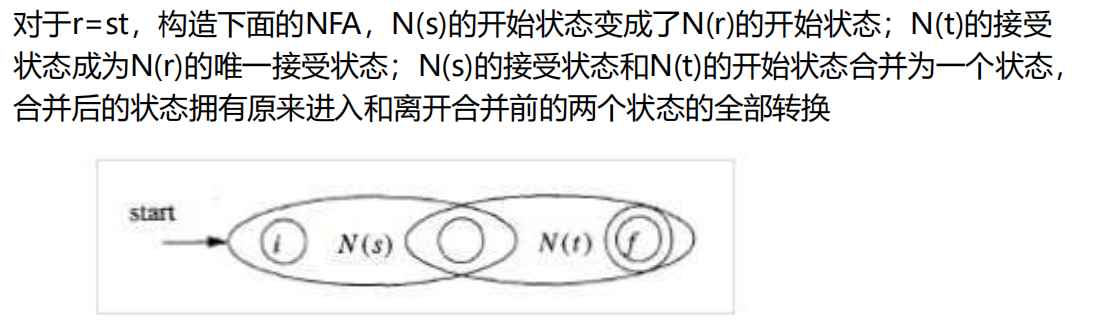
- r = st
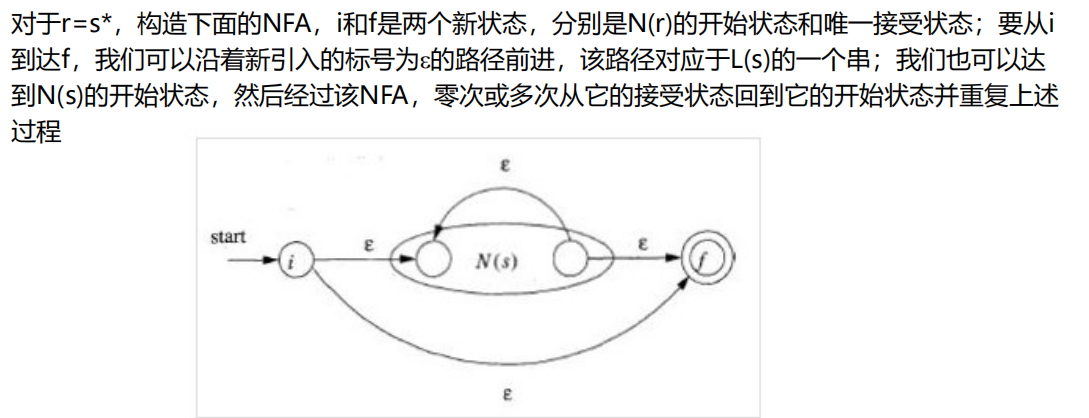
- r = s ∗ r = s^* r=s∗
方法二:RE -> DFA -> 最小DFA
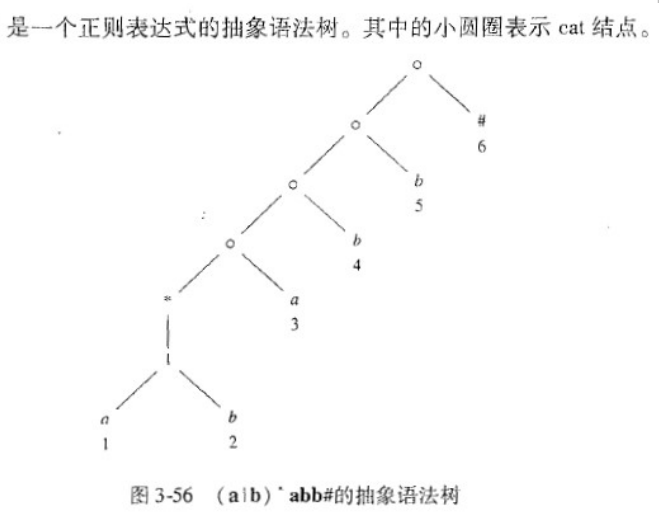
- 首先先构造语法分析树,并标记位置
- (a|b)*abb -> (a|b)*abb# (增广正则表达式(r)#)
- NFA的重要状态:NFA状态有一个标号非 ε \varepsilon ε的离开转换,则称该状态为重要状态(important state) — 子集法在计算move(T, a)的时候,只使用了重要状态
- 计算四个函数nullable, firstpos, lastpos, followpos
- nullable(n) returns true or false:表示以n为根结点推导出的句子集合是否包括空串,“是”则nullable(n)=true;“否”则nullable(n)=false
- firstpos(n)定义了以结点n为根推导出的某个句子的第一个符号的位置集合
- lastpos(n)定义了以结点n为根推导出的某个句子的最后一个符号的位置集合—规则在本质上和计算firstpos的规则相同,但是在针对cat结点的规则中,左右子树的角色要对调