引入:
①MySQL的事务,有四个比较核心的特性:
1.原子性 2.一致性 3.持久性(和持久化说的是一回事(把数据存在硬盘上=>持久 把数据存在内存中=>不持久)重启进程/重启主机之后,数据是否存在)4.隔离性
②redis是一个内存数据库,把数据存是放在内存中的(内存数据不持久的,要想做到持久,就需要让redis把数据存储到硬盘上)
③redis相比于MySQL这样的关系型数据库,最明显的优势=>效率高/快
④为了保证速度快,数据肯定还是得存放在内存中,但是为了持久,数据还是的想办法存放在硬盘上,因此redis巨鼎,内存中存储数据,硬盘上也存数据
⑤当插入一个新数据的时候,就需要把这个数据同时写到内存和硬盘中,当查询某个数据的时候,直接从内存中读取,硬盘中的数据只是在redis重启的时候,用来恢复数据
Redis实现持久化是按照什么样的策略来进行实现的?
1.RDB=>Redis DataBase:定期备份,设置一个时间,定期把硬盘中的数据备份到备份盘中(这里使用二进制的方式来组织数据,直接把数据读到内存中,按照字节的格式取出来,放到结构体/对象中即可)
2.AOP=>Append Only File:实时备份,只要是下载了一个数据,就往备份盘里写(是使用文本的方式来组织数据的,则需要进行一系列的字符串切分操作)
当开启aof的时候,rdb就不生效了,启动的时候,就不在读取rdb文件内容了
一.RDB实现持久化:
RDB定期把我们Redis内存中所有的数据,都写入硬盘中,生成一个快照(Redis给内存中当前存储的这些数据,赶紧拍个照片,生成一个文件,存储在硬盘中。后续Redis一旦重启了(内存数据就没了,就可以根据刚才的“快照”,就能把内存中的数据给恢复过来))
“定期”具体来说,又有两种方式:
1.手动触发(程序员通过Redis客户端,执行特定的命令,来出发快照的生成):
save:执行save的时候,Redis会全力以赴的进行“快照”的生成操作,此时就会阻塞Redis的其他客户端命令,导致类似key*的后果(一般不建议使用save)
bgsave:bg=>background(后面)不会影响Redis服务器处理其他客户端的请求和命令
(这里Redis使用的是“多进程”的方式,来完成并发编程,来完成bgsave的实现)
![]()
2.自动触发:在Redis配置文件中,设置一个,让Redis每隔多长时间/每产生多少次修改就触发
注意:
①redis 生成的RDB文件是存放在redis的工作目录中,也是在redis的配置文件中设置的
②RDB机制生成的镜像文件。redis服务器就是默认开启了RDB的
③二进制的文件,把内存中的数据,以压缩(需要消耗一定的CUP资源,但是能节省存储空间)的形式保存到这个二进制文件中
④后续redis服务器重新启动,就会尝试加载这个RDB文件,如果发现格式错误,就可能会加载数据失败
⑤redis提供了RDB的检查工具redis-check-rdb*
⑥当执行生成RDB镜像操作的时候,此时就会把要生成的快照数据,先保存到一个临时文件中,当这个快照生成完毕之后,在删除之前的RDB文件,把生成的临时文件名字改成刚才的dump.rdb(自始至终rdb文件只有一个)
⑦生成一次rdb快照,这个成本是一个比较高的成本,不能让这个操作太频繁,正因为redis生成的不能太频繁,这就导致,快照里的数据,和当时的数据情况可能存在偏差(APF解决的就是这个问题)

bgsave的执行流程:
1.判断当前是否已经存在其他工作的子进程(比如现在已经有一个子进程正在执行bgsave,此时就直接把当前的bgsave返回)
2.如果没有其他的工作子进程,就通过fork这样的系统调用,创建出一个子进程来
(fork是Linux系统提供的一个创建子进程的API(系统调用)如果是其他的系统,比如Windows,创建子进程就不是fork(CreateProcess...)
fork创建子进程,简单粗暴,直接把当前的进程(父进程)复制(会复制pcb,虚拟地址空间(内存中的数据,文件描述符...))一份,作为子进程,一旦复制完成了,父子进程就是两个独立的进程,就各自执行各自的了
本来redis sever中,有若干变量,保存了一些键值对数据,随着这样的fork的进行,子进程的这个内存中也存在和刚才父进程一模一样的变量
因此,复制出来的这个“克隆体”(子进程)的内存中的数据就是和“本体”(父进程)是一样的
接下来安排子进程去执行“持久化”操作,也就相当于把父进程本体这里的内存数据给持久化了,也就导致了子进程持久化写入的那个文件和父进程本来要写的文件是同一个了
注意:
如果当前,redis服务器中存储的数据特别多,内存消耗特别大(比如100G)此时,进行上述复制操作,是否会有很大的性能开销?
答:此处的性能开销,其实挺小的,fork在进行内存拷贝的时候,不是简单无脑的直接把所有的数据都拷贝一遍,而是“写时拷贝”的机制来完成的(如果紫禁城例的这个内存数据和父进程的内存数据完全一样了,此时就不会触发真正的拷贝动作(而是他俩用一份内存数据),但是,其实这俩进程的内存空间,应该是各自独立的,一旦某一方针对这个数据做了修改,就会立即触发真正物理上的数据拷贝)
例子:

在进行bgsave这个场景中,绝大部分的内存数据,是不需要改变的(整体来说这个过程执行还是挺快的,这个短时间内,父进程不会有大批的内存数据的变化)
)
3.子进程负责进行写文件,生成快照的过程,父进程继续接收客户端的请求,继续正常提供服务
4.子进程完成整体的持久化过程之后,就会通知父进程,干完了,父进程,就会更新一些统计信息,子进程可以结束销毁了
具体的操作:
1.手动执行save和bgsave触发一次生成快照:
(由于当前的数据比较少,所以bgsave立即就完成,但接触到的数据多了,执行bgsave就会消耗一定的时间)
2.插入新的key,不手动执行bgsave
①如果通过正常的流程重新启动redis服务器,此时redis服务器在推出的时候,自动触发生成rdb的操作
②如果是异常重启(kill -9或者服务器掉电,此时redis服务器来不及生成rdb,内存中尚未保存到快照的数据,就会随着重启而丢失)
③redis生成快照操作,不仅仅是手动命令才触发,也可以自动触发
1)通过刚才配置文件中save执行M时间内,修改N次
2)通过shutdown命令(redis里的一个命令)关闭redis服务器,也会触发(service redis-server restart)正常关闭
3)redis进行主从复制的时候,主节点也会自动生成rdb快照,然后把rdb快照文件内容传输给从节点
3.bgsave操作流程是创建子进程,子进程完成持久化操作,持久化会把数据写入到新的文件中,然后使用新的文件替换就的文件(可以使用Linux的stat命令,查看文件的inode编号)
注:
Linux文件系统:文件系统典型的组织方式主要是把文件系统分成了三个大部分
①.超级块(放的是一些管理信息)
②.inode区(存放的inode节点,每个文件都会分配一个inode数据结构,包含了文件的各种元数据)
③.block区,存放文件的数据内容
4.通过配置生成rdb快照
5.如果把rdb文件,故意改坏了,会怎么样?
手动的把rdb文件内容改坏了,然后一定是通过kill进程的方式,重新启动redis服务器;如果是通过service redis-server restart重启,就会在redis服务器退出的时候,重新生成rdb快照,就把刚才改坏的文件替换掉
rdb文件是二进制的,直接把rdb文件交给redis服务器去使用,的到的结果是不可预期的,可能redis服务器能够重启,也可以redis服务器直接重启失败
注:redis也提供了rdb文件的检查工具,可以先通过检查工具,检查一下rdb文件的格式是否符合要求
二.AOF实现持久化:类似于MySQL的binlog,就会把用户的每个操作,都记录到文件中,当redis重启的时候,就会读到这个aof文件的内容,用来恢复数据(aof默认一般是关闭状态,修改配置文件,来开启aof功能)
注:
1.redis虽然是一个单线程服务器,但是速度很快,为什么?最重要的原因:只是在内存操作
2.引入AOF之后,又要写入内存,又要写硬盘,还能和之前一样快嘛?
实际上是没有影响的:①AOF机制并非是直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓冲区,积累一波之后,在统一写入硬盘②硬盘中读写数据,顺序读写的数据是比较快的(还是比内存要慢很多)随机访问的速度是比较慢的(AOF每次把新的操作写入到原有文件的末尾,属于顺序写入)
注:如果把数据写入到缓冲区里,本质还是在内存中,万一重启或主机掉电,缓冲区没来的及写入AOF的数据还是会丢失
于是redis给出了一些选项,让程序员,根据实际情况来决定怎么取舍,缓冲区刷新策略:①刷新频率越高,性能影响就越大,同时数据的可靠信越高 ②刷新频率越低,性能影响就越小,数据的可靠性就越低
always:命令写⼊aof_buf后调⽤fsync同步,完成后返回(频率最高,可靠信最高,性能最低)
everysec:命令写⼊aof_buf后只执⾏write操作,不进⾏fsync。每秒由同步线程进⾏fsync。(频率变低,可靠信变低,性能提高)
no:命令写⼊aof_buf后只执⾏write操作,由OS控制 fsync频率(频率最低,可靠信最低,性能最高)
3.AOF文件持续增长,体积越来越大,会影响redis下次启动的启动时间,redis启动的时候要读取AOF文件(实际上redis在重启的时候只是关注最终结果)的内容
AOF文件有些内容是冗余的:
比如:进行一下操作:lpush key 111,lpush key 222,lpush key 333<=> lpush key 111 222 333
再比如,进行一下操作:set key 111 ,set key 222,set key 333=>set key 333
再比如:set key 111 ,del key,set key 222,del key =>相当于什么都不做
因此,redis就存在一个机制,能够针对AOF文件进行整理操作,这个整理操作就是能够删除其中冗余的操作,并且合并一些操作,达到给AOF文件瘦身这样的效果
3.重写机制:
⼿动触发:调⽤bgrewriteaof命令。
⾃动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定⾃动触发时 机。
auto-aof-rewrite-min-size:表⽰触发重写时AOF的最⼩⽂件⼤⼩,默认为64MB。
auto-aof-rewrite-percentage:代表当前AOF占⽤⼤⼩相⽐较上次重写时增加的⽐例。
AOF的重写流程:
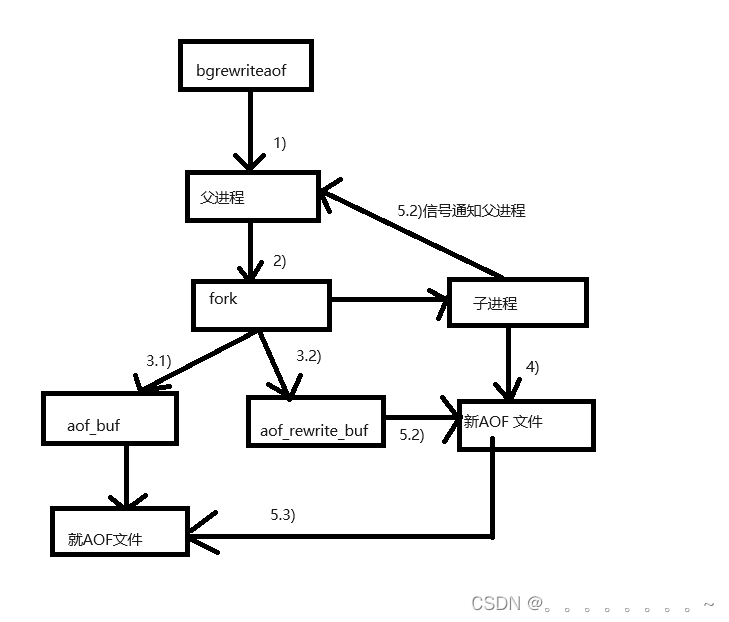
创建子进程fork
父进程仍然负责接收请求,子进程负责对AOF进行重写(重写的时候不关心AOF文件中原来都有啥,只是关心内存中的最终数据状态(子进程值需要把内存中当前的数据获取出来,以AOF的格式写入到一个新的AOF文件中(内存中数据的状态,就已经相当于是把AOF文件结果整理后的磨摸样了)))
①子进程写新AOF文件的同时,父进程仍然在不停的接收客户端新的请求,父进程还是会把这些请求产生的AOF写入到缓冲区,再刷新到原有的AOF文件里
②在创建子进程的以瞬间,子进程就继承了当前父进程的内存状态。 因此,子进程里的内存数据是父进程fork之前的状态,fork之后,新来的请求,对内存造成的修改,是子进程不知道的。 此时,父进程这里又准备了一个aof_rewrite_buf缓冲区,专门存放fork之后的数据 子进程这边把aof数据写完之后,会通过一个信号通知一下父进程,父进程再把aof_rewrite_buf缓冲区中的内容也写入到新的aof文件里 就可以用aof新文件代替aof旧文件了
③此处子进程写数据的过程,非常类似于rdb生成一个镜像快照,只不过rdb这里是按照二进制的方式来生成的,aof重写,则按照aof这里要求的文本格式来生成(都是为了把当前内存中的所有数据记录到文件中)
④如果在执行bgrewriteaof的时候,当前redis已经进行重写了,此时不会执行aof操作,直接返回了
⑤如果在执行bgrewriteaof的时候,发现redis在生成rdb文件快照的时候,此时,aof重写操作就会等待,等待rdb快照生成完毕之后,再执行aof操作
⑥rdb对于fork之后的新数据,就直接置之不理了,aof则对于fork之后的新数据,采取aof_rewrite_buf缓冲区的方式来处理(rdb本身的设计理念就是用来“定期备份”的,只要是定期备份,就难以和最新数据保持一致;aof的理念是实时备份)实时备份不一定比定期备份好,这个要看实际场景
父进程fork完毕之后,就已经让子进程写新的aof文件了,并且随着时间的推移,子进程很快就写完了新的文件,要让新的aof文件代替旧的,父进程此时还在继续写这个即将消亡的旧的aof文件是否还有意义?[不能不写]
答:考虑到极端情况,假设在重写的过程中,重写了一半,服务器挂了,子进程的数据就会丢失,新的aof文件内容还不完整,所以父进程不坚持写旧aof文件,重启就没法保证数据的完整性
3.混合式持久化:
aof本本来是按照文本的方式写文件,但是文本的方式写文件,后续加载的成本是比较高的,于是就引入了“混合持久化”的方式,结合了rdb和aof的特点
按照aof的方式把每个请求/操作,都记录入文件,在出发aof重写之后,就会把当前内存的状态按照rdb二进制的格式写入新的aof文件中,后续再进行操作,仍然是按照aof文本的方式追加到文件后面
信号通知父进程:
信号可以认为是Linux的神经系统