def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1]#类别标签向量,1代表侮辱性词汇,0代表不是
return postingList,classVec
# 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) #取并集
return list(vocabSet)
if __name__ == '__main__':
postingList, classVec = loadDataSet()
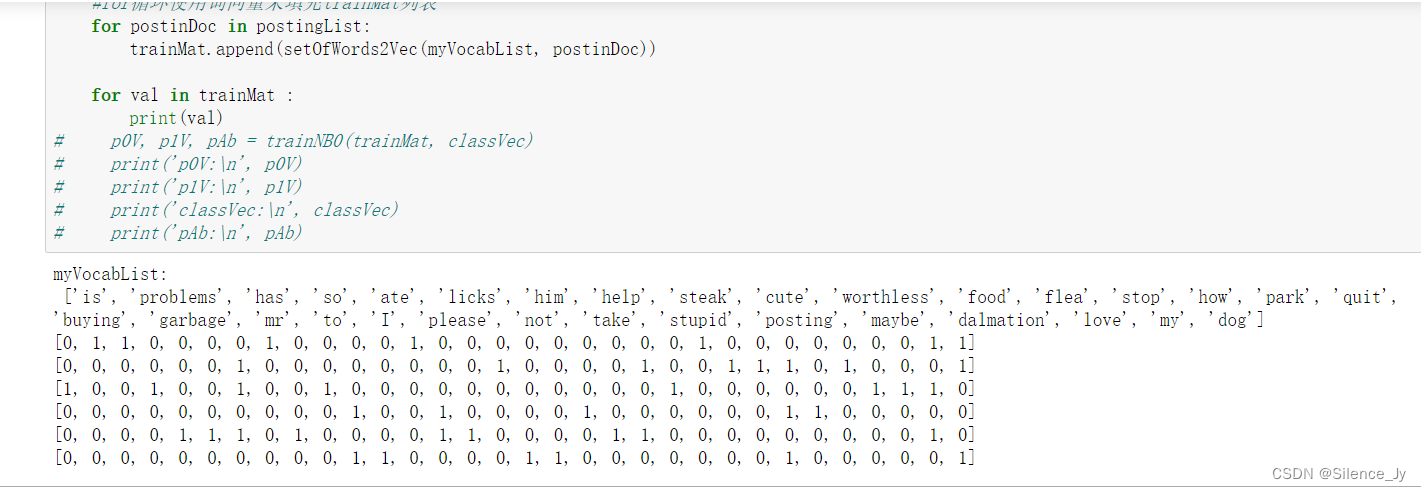
myVocabList = createVocabList(postingList)
print('myVocabList:\n', myVocabList)
myVocabList:
['is', 'problems', 'has', 'so', 'ate', 'licks', 'him', 'help', 'steak', 'cute', 'worthless', 'food', 'flea', 'stop', 'how', 'park', 'quit', 'buying', 'garbage', 'mr', 'to', 'I', 'please', 'not', 'take', 'stupid', 'posting', 'maybe', 'dalmation', 'love', 'my', 'dog']
# 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) #创建一个其中所含元素都为0的向量
for word in inputSet: #遍历每个词条
if word in vocabList: #如果词条存在于词汇表中,则置1
returnVec[vocabList.index(word)] = 1
else: print("the word: %s is not in my Vocabulary!" % word)
return returnVec #返回文档向量
trainMat = []
#遍历每一个词向量来填充trainMat列表
for postinDoc in postingList:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
# print(trainMat)
我们先使用极大似然估计计算条件概率和先验概率
import numpy as np
p0V, p1V, pAb = trainNB0(trainMat, classVec)
# 先验概率
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix) # 文件数,也就是行向量的个数
numWords = len(trainMatrix[0]) # 单词数,也就是词汇表中单词的个数
# 先验概率 👇
pAbusive = sum(trainCategory) / float(numTrainDocs)
# 侮辱性文件的出现概率,即 trainCategory 中所有 1 的个数(0 1 相加即得 1 的个数)
# 条件概率 👇
# (非)侮辱性单词在每个文件中出现的次数列表
# 比如说 p0Num = [1,3,12,....] 表示第 2 个文档中出现了 3 次非侮辱词汇
p0Num = np.zeros(numWords) # [0,0,0,.....] 非侮辱性单词在每个文件中出现的次数列表
p1Num = np.zeros(numWords) # [0,0,0,.....] 侮辱性单词出在每个文件中出现的次数列表
# (非)侮辱性单词在(非)侮辱性文档出现的总数
p0Denom = 0.0 # 0 非侮辱性词汇在所有非侮辱的文档的出现总数
p1Denom = 0.0 # 1 侮辱性词汇在所有侮辱性的文档的出现总数
#遍历每个文件
for i in range(numTrainDocs):
# 是否是侮辱性文件
if trainCategory[i] == 1:
# 如果是侮辱性文件,对侮辱性文件的向量进行相加
#表示在所有侮辱性文件中,去重词汇表中各个词汇出现的次数
p1Num += trainMatrix[i]
# 对向量中的所有元素进行求和
#表示在所有侮辱性文件中,去重词汇表中所有词汇出现的次数之和
p1Denom += sum(trainMatrix[i])
else:
# 如果是非侮辱性文件,对非侮辱性文件的向量进行相加,表示在所有非侮辱性文件中,去重词汇表中各个词汇出现的次数
p0Num += trainMatrix[i]
# 对向量中的所有元素进行求和,表示在所有非侮辱性文件中去重词汇表中所有词汇出现的次数之和
p0Denom += sum(trainMatrix[i])
# 在类别 1 即侮辱性文档的条件下,去重词汇表中每个单词出现的概率
p1Vect = p1Num / p1Denom
# 在类别 0 即非侮辱性文档的条件下,去重词汇表中每个单词出现的概率
p0Vect = p0Num / p0Denom
return pAbusive, p0Vect, p1Vect
但是我们输出结果后会发现基于极大似然估计得朴素贝叶斯算法的结果差强人意,如果其中一个类别的概率值为0,那么最后的乘积也为0,我们可以贝叶斯估计优化算法,在条件概率计算的公式的分子分母上分别加上 λ 和 S j λ \lambda和S_j\lambda λ和Sjλ, S j S_j Sj代表分类的个数,此样例中为2,即侮辱与非侮辱类。
也就是将条件概率和先验概率的分子初始化为1,分母初始化为2.
# (非)侮辱性单词在每个文件中出现的次数列表
# 比如说 p0Num = [1,3,12,....] 表示第 2 个文档中出现了 3 次非侮辱词汇
p0Num = np.ones(numWords) # [1,1,1,.....] 非侮辱性单词在每个文件中出现的次数列表
p1Num = np.ones(numWords) # [1,1,1,.....] 侮辱性单词出在每个文件中出现的次数列表
# (非)侮辱性单词在(非)侮辱性文档出现的总数
p0Denom = 2.0 # 0 非侮辱性词汇在所有非侮辱的文档的出现总数
p1Denom = 2.0 # 1 侮辱性词汇在所有侮辱性的文档的出现总数
但是此时如果我们直接输出的话会出现下溢出问题,是由于太多个小数相乘造成的,在python的精度下,太多小数相乘会四舍五入为0,会影响得到正确的答案。一种解决方法是对乘积取自然对数,所以我们可以修改以下代码
p1Vect = np.log(p1Num / p1Denom)
p0Vect = np.log(p0Num / p0Denom)
p0V, p1V, pAb = trainNB0(trainMat, classVec)
print('p0V:\n', p0V)
print('p1V:\n', p1V)
print('classVec:\n', classVec)
print('pAb:\n', pAb)