9. Flink 状态如何存储?
在 Flink 中,状态存储 被叫做 StateBackend,它具备两种能力:
- 在计算过程中提供访问 State 能力,开发者在编写业务逻辑中能够使用 StateBackend 的接口读写数据。
- 能够将 State 持久化到外部存储,提供容错能力。
Flink 状态提供三种存储方式:
- 内存型:MemoryStateBackend,适用于验证、测试、不推荐生产使用。
- 文件型:FSStateBackend,适用于长周期大规模的数据。
- RocksDB: RocksDBStateBackend,适用于长周期大规模的数据。
上面提到的 StateBackend 是 面向用户 的,在 Flink 内部 3 种 State 的关系如下图:
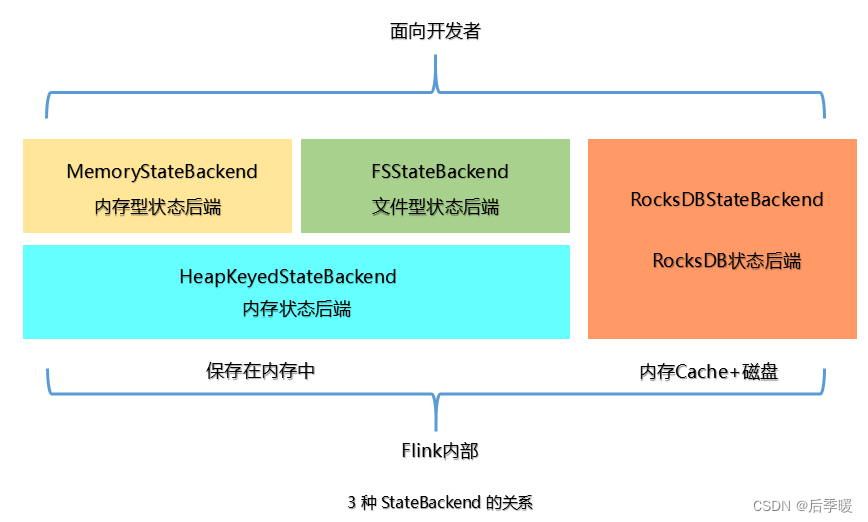
在运行时,MemoryStateBackend 和 FSStateBackend 本地的 State 都保存在 TaskManager 的内存中,所以其底层都依赖于 HeapKeyedStateBackend。HeapKeyedStateBackend 面向 Flink 引擎内部,使用者无须感知。
1、内存型 StateBackend
MemoryStateBackend,运行时所需的 State 数据全部保存在 TaskManager JVM 堆上内存中,KV 类型的 State、窗口算子的 State 使用 HashTable 来保存数据、触发器等。执行检查点的时候,会把 State 的快照数据保存到 JobManager 进程的内存中。
MemoryStateBackend 可以使用异步的方式进行快照(也可以同步,推荐异步),避免阻塞算子处理数据。
基于内存的 StateBackend 在生产环境下不建议使用,可以在本地开发调试测试 。注意点如下 :
- State 存储在 JobManager 的内存中,受限于 JobManager 的内存大小。
- 每个 State 默认5MB,可通过 MemoryStateBackend 构造函数调整。
- 每个 Stale 不能超过 Akka Frame 大小。
2、文件型 StateBackend
FSStateBackend,运行时所需的 State 数据全部保存在 TaskManager 的内存中, 执行检查点的时候,会把 State 的快照数据保存到配置的文件系统中。
可以是分布式或者本地文件系统,路径如:
- HDFS路径:“hdfs://namenode:40010/flink/checkpoints”
- 本地路径:“file:///data/flink/checkpoints”
FSStateBackend 适用于处理大状态、长窗口、或者大键值状态的有状态处理任务。注意点如下 :
- State 数据首先被存在 TaskManager 的内存中。
- State 大小不能超过 TM 内存。
- TM 异步将 State 数据写入外部存储。
MemoryStateBackend 和 FSStateBackend 都依赖于 HeapKeyedStateBackend,HeapKeyedStateBackend 使用 State 存储数据。
3、RocksDBStateBackend
RocksDBStateBackend 跟内存型和文件型都不同 。
RocksDBStateBackend 使用嵌入式的本地数据库 RocksDB 将流计算数据状态存储在本地磁盘中,不会受限于 TaskManager 的内存大小,在执行检查点的时候,再将整个 RocksDB 中保存的 State 数据全量或者增量持久化到配置的文件系统中,在 JobManager 内存中会存储少量的检查点元数据。RocksDB 克服了 State 受内存限制的问题,同时又能够持久化到远端文件系统中,比较适合在生产中使用。
缺点:RocksDBStateBackend 相比基于内存的 StateBackend,访问 State 的成本高很多,可能导致数据流的吞吐量剧烈下降,甚至可能降低为原来的1/10。
适用场景
最适合用于处理大状态、长窗口,或大键值状态的有状态处理任务。
- RocksDBStateBackend 非常适合用于高可用方案。
- RocksDBStateBackend 是目前唯一支持增量检查点的后端。增量检查点非常适用于超大状态的场景。
注意点
- 总 State 大小仅限于磁盘大小,不受内存限制。
- RocksDBStateBackend 也需要配置外部文件系统,集中保存 State。
- RocksDB 的 JNI API 基于 byte 数组,单 Key 和单 Value 的大小不能超过 8 88 字节。
- 对于使用具有合并操作状态的应用程序,如 ListState ,随着时间可能会累积到超过2的31次方字节大小,这将会导致在接下来的查询中失败。
10. Flink 状态过期后如何清理?
1、DataStream 中状态过期
可以对 DataStream 中的每一个状态设置清理策略 StateTtlConfig,可以设置的内容如下:
过期时间:超过多长时间未访问,视为 State 过期,类似于缓存。
过期时间更新策略:创建和写时更新、读取和写时更新。
State 可见性:未清理可用,超时则不可用。
2、Flink SQL 中状态过期
Flink SQL 一般在流 Join、聚合类场景使用 State,如果 State 不定时清理,则导致 State 过多,内存溢出。清理策略配置如下:
StreamQueryConfig qConfig = ...
//设置过期时间为 min = 12小时 ,max = 24小时
qConfig.withIdleStateRetentionTime(Time.hours(12),Time.hours(24));
11. 什么是 CheckpointCoordinator 检查点协调器?
1) CheckpointCoordinator(检查点协调器) 周期性的向该流应用的所有source算子发送 barrier(屏障)。
2) 当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
3) 下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
4) 每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
5) 当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
12. 当作业失败后,检查点如何恢复作业?
Flink 提供了 应用自动恢复机制 和 手动作业恢复机制。
1、应用自动恢复机制
Flink 设置有作业失败重启策略,包含三种:
- 定期恢复策略(fixed-delay):固定延迟重启策略会尝试一个给定的次数来重启 Job,如果超过最大的重启次数,Job 最终将失败,在连续两次重启尝试之间,重启策略会等待一个固定时间,默认 Integer.MAX_VALUE 次。
- 失败比率策略(failure-rate):失败比率重启策略在 Job 失败后重启,但是超过失败率后,Job 会最终被认定失败,在两个连续的重启尝试之间,重启策略会等待一个固定的时间。
- 直接失败策略(None):失败不重启。
2、手动作业恢复机制
因为 Flink 检查点目录分别对应的是 JobId,每通过 flink run 方式 / 页面提交方式恢复都会重新生成 JobId,Flink 提供了在启动之时通过设置 -s 参数指定检查点目录的功能,让新的 Jobld 读取该检查点元文件信息和状态信息,从而达到指定时间节点启动作业的目的。
启动方式如下:
/bin/flink -s /flink/checkpoints/03112312a12398740a87393/chk-50/_metadata
13. 要实现 Exactly-Once 需具备什么条件?
要保证flink 端到端需要满足以下三点
1、flink要开启checkpoint
2、source支持数据重发
3、sink端幂等性写入、事务性写入。我们常使用事务性写入
sink 事务性写入分为两种方式
1、WAL(预写日志的方式):先将数据当作状态保存,当收到checkpoint完成通知后,一次性sink到下游系统
2、2pc(两阶段提交):大致的实现的过程就是:
- 开始事务(beginTransaction)创建一个临时文件夹,来写把数据写入到这个文件夹里面。
- 预提交(preCommit)将内存中缓存的数据写入文件并关闭。
- 正式提交(commit)将之前写完的临时文件放入目标目录下。这代表着最终的数据会有一些延迟。
- 丢弃(abort)丢弃临时文件
若失败发生在预提交成功后,正式提交前。可以根据状态来提交预提交的数据,也可删除预提交的数据。
14. 介绍一下两阶段提交

15. 反压
16. Flink 如何进行序列和反序列化的?
所谓序列化和反序列化的含义:
- 序列化:就是将一个内存对象转换成二进制串,形成网络传输或者持久化的数据流。
- 反序列化:将二进制串转换为内存对。
TypeInformation 是 Flink 类型系统的核心类 。
在 Flink 中,当数据需要进行序列化时,会使用 TypeInformation 的生成序列化器接口调用一个 createSerialize() 方法,创建出 TypeSerializer,TypeSerializer 提供了序列化和反序列化能力。
Flink 的序列化过程如下图所示:

对于大多数数据类型 Flink 可以自动生成对应的序列化器,能非常高效地对数据集进行序列化和反序列化 ,如下图: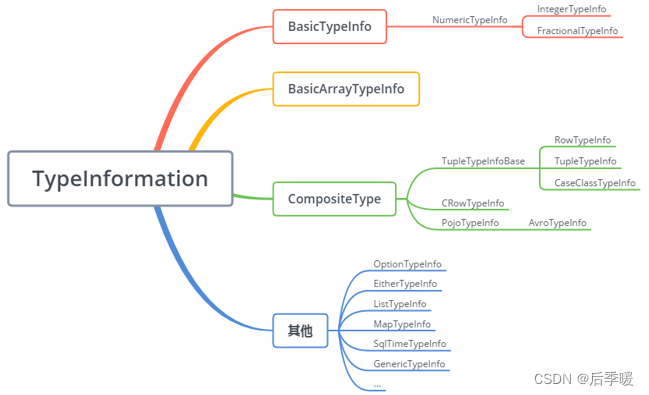
比如,BasicTypeInfo、WritableTypeIno ,但针对 GenericTypeInfo 类型,Flink 会使用 Kyro 进行序列化和反序列化。其中,Tuple、Pojo 和 CaseClass 类型是复合类型,它们可能嵌套一个或者多个数据类型。在这种情况下,它们的序列化器同样是复合的。它们会将内嵌类型的序列化委托给对应类型的序列化器。
通过一个案例介绍 Flink 序列化和反序列化:
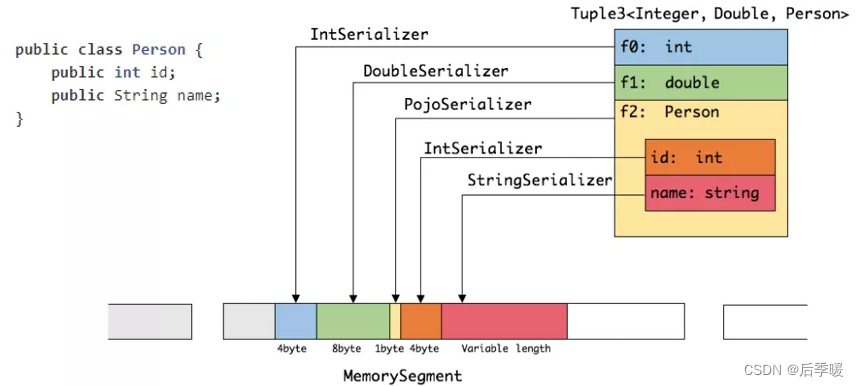
如上图所示,当创建一个 Tuple3 对象时,包含三个层面,一是 int 类型,一是 double 类型,还有一个是 Person。Person 对象包含两个字段,一是 int 型的 id,另一个是 String 类型的 name。
- 在序列化操作时,会委托相应具体序列化的序列化器进行相应的序列化操作。从图中可以看到 Tuple3 会把 int 类型通过 IntSerializer 进行序列化操作,此时 int 只需要占用四个字节。
- Person 类会被当成一个 Pojo 对象来进行处理,PojoSerializer 序列化器会把一些属性信息使用一个字节存储起来。同样,其字段则采取相对应的序列化器进行相应序列化,在序列化完的结果中,可以看到所有的数据都是由 MemorySegment 去支持。
MemorySegment 具有什么作用呢?
MemorySegment 在 Flink 中会将对象序列化到预分配的内存块上,它代表 1 11 个固定长度的内存,默认大小为 32 k b 32\ kb32 kb。MemorySegment 代表 Flink 中的一个最小的内存分配单元,相当于是 Java 的一个 byte 数组。每条记录都会以序列化的形式存储在一个或多个 MemorySegment 中。
17. 为什么 Flink 使用自主内存,而不用 JVM 内存管理?
因为在内存中存储大量的数据(包括缓存和高效处理)时,JVM 会面临很多问题,包括如下:
- Java 对象存储密度低。Java 的对象在内存中存储包含3个主要部分:对象头、实例数据、对齐填充部分。例如,一个只包含 boolean 属性的对象占16byte:对象头占8byte, boolean 属性占1byte,为了对齐达到8的倍数额外占7byte。而实际上只需要1个bit(1/8 字节)就够了。
- Full GC 会极大地影响性能。尤其是为了处理更大数据而开了很大内存空间的 JVM 来说,GC(Garbage Collection)会达到秒级甚至分钟级。
- OOM 问题影响稳定性。内存溢出(OutOfMemoryError)是分布式计算框架经常会遇到的问题, 当 JVM 中所有对象大小超过分配给 JVM 的内存大小时,就会发生 OutOfMemoryError 错误, 导致 JVM 崩溃,分布式框架的健壮性和性能都会受到影响。
- 缓存未命中问题。CPU 进行计算的时候,是从 CPU 缓存中获取数据。现代体系的 CPU 会有多级缓存,而加载的时候是以 Cache Line 为单位加载。如果能够将对象连续存储, 这样就会大大降低 Cache Miss。使得 CPU 集中处理业务,而不是空转。
18. 作业图介绍一下?
JobGraph 是由 StreamGraph 优化而来,是通过 OperationChain 机制将算子合并起来,在执行时,调度在同一个 Task 线程上,避免数据的跨线程,跨网络传递。

作业图 JobGraph 核心对象包括三个:
- JobVertex 点:经过算子融合优化后符合条件的多个 StreamNode 可能会融合在一起生成一个 JobVertex,即一个 JobVertex 包含一个或多个算子, JobVertex 的输入是 JobEdge,输出是 IntermediateDataSet。
- JobEdge 边:JobEdge 表示 JobGraph 中的一 个数据流转通道, 其上游数据源是 IntermediateDataSet ,下游消费者是 JobVertex 。JobEdge 中的数据分发模式会直接影响执行时 Task 之间的数据连接关系是点对点连接还是全连接。
- IntermediateDataSet 中间数据集:中间数据集 IntermediateDataSet 是一种逻辑结构,用来表示 JobVertex 的输出,即该 JobVertex 中包含的算子会产生的数据集。不同的执行模式下,其对应的结果分区类型不同,决定了在执行时刻数据交换的模式。
19. 执行图介绍一下?
ExecutionGraph 是调度 Flink 作业执行的核心数据结构,包含了作业中所有并行执行的 Task 信息、Task 之间的关联关系、数据流转关系。
StreamGraph 和 JobGraph 都在 Flink Client 生成,然后交给 Flink 集群。JobGraph 到 ExecutionGraph 在 JobMaster 中完成,转换过程中重要变化如下:
- 加入了并行度的概念,成为真正可调度的图结构。
- 生成了6个核心对象。

执行图 ExecutionGraph 核心对象包括 6 66 个:
- ExecutionJobVertex:该对象和 JobGraph 中的 JobVertex 一一对应。该对象还包含一组 ExecutionVertex, 数量与该 JobVertex 中所包含的 StreamNode 的并行度一致,假设 StreamNode 的并行度为 5 ,那么 ExecutionJobVertex 中也会包含 5 个 ExecutionVertex。ExecutionJobVertex 用来将一个 JobVertex 封装成 ExecutionJobVertex,并依次创建 ExecutionVertex、Execution、IntermediateResult 和 IntermediateResultPartition,用于丰富 ExecutionGraph。
- ExecutionVertex:ExecutionJobVertex 会对作业进行并行化处理,构造可以并行执行的实例,每一个并行执行的实例就是 ExecutionVertex。
- IntermediateResult:IntermediateResult 又叫作中间结果集,该对象是个逻辑概念表示 ExecutionJobVertex 输出,和 JobGrap 中的 IntermediateDalaSet 一一对应,同样一个 ExecutionJobVertex 可以有多个中间结果,取决于当前 JobVertex 有几个出边(JobEdge)。
- IntermediateResultPartition:IntermediateResultPartition 又叫作中间结果分区。表示 1个 ExecutionVertex 输出结果,与 ExecutionEdge 相关联。
- ExecutionEdge:表示 ExecutionVertex 的输入,连接到上游产生的 IntermediateResultPartition。1 个 Execution 对应唯一的 1 个 IntermediateResultPartition 和 1 个 ExecutionVertex。1 个 ExecutionVertex 可以有多个 ExecutionEdge。
- Execution:ExecutionVertex 相当于每个 Task 的模板,在真正执行的时候,会将 ExecutionVertex 中的信息包装为 1 个 Execution,执行一个 ExecutionVertex 的一次尝试。
JobManager 和 TaskManager 之间关于 Task 的部署和 Task 执行状态的更新都是通过 ExecutionAttemptID 来识别标识的。
20. Flink 调度模式包含几种?
调度模式包含 3 33 种:Eager 模式、分阶段模式(Lazy_From_Source)、分阶段 Slot 重用模式(Lazy_From_Sources_With_Batch_Slot_Request)。
- Eager 调度:适用于流计算。一次性申请需要的所有资源,如果资源不足,则作业启动失败。
- 分阶段调度:LAZY_FROM_SOURCES 适用于批处理。从 SourceTask 开始分阶段调度,申请资源的时候,一次性申请本阶段所需要的所有资源。上游 Task 执行完毕后开始调度执行下游的 Task,读取上游的数据,执行本阶段的计算任务,执行完毕之后,调度后一个阶段的 Task,依次进行调度,直到作业完成。
- 分阶段 Slot 重用调度:LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST 适用于批处理。与分阶段调度基本一样,区别在于该模式下使用批处理资源申请模式,可以在资源不足的情况下执行作业,但是需要确保在本阶段的作业执行中没有 Shuffle 行为。
目前视线中的 Eager 模式和 LAZY_FROM_SOURCES 模式的资源申请逻辑一样,LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST 是单独的资源申请逻辑。