背景:通常在处理分类问题中数据不平衡类别。使用SMOTE算法对其中的少数类别进行过采样,以使其与多数类别的样本数量相当或更接近。
直接上代码
from imblearn.over_sampling import SMOTE
from sklearn.datasets import make_classification
from collections import Counter
import matplotlib.pyplot as plt
# 创建一个不平衡的数据集
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.1, 0.9], n_informative=3, n_redundant=1,
flip_y=0, n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10)
print('Original dataset shape %s' % Counter(y))
# 使用SMOTE算法平衡数据集
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
print('Resampled dataset shape %s' % Counter(y_resampled))
# 可视化原始数据集和平衡后的数据集
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c=y, marker='o', cmap='coolwarm', alpha=0.6)
plt.title('Original Dataset')
plt.subplot(1, 2, 2)
plt.scatter(X_resampled[:, 0], X_resampled[:, 1], c=y_resampled, marker='o', cmap='coolwarm', alpha=0.6)
plt.title('Resampled Dataset')
plt.tight_layout()
plt.show()Original dataset shape Counter({1: 900, 0: 100})
Resampled dataset shape Counter({0: 900, 1: 900})
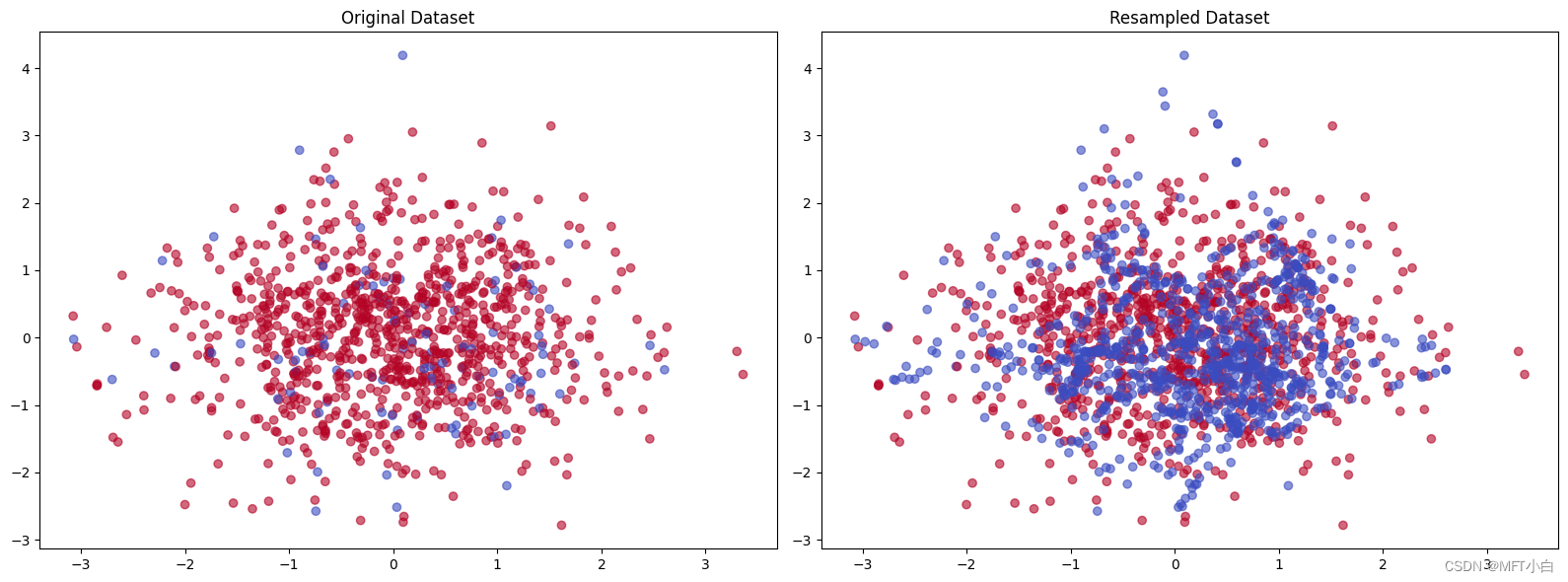
这个示例中,首先生成一个不平衡的二分类数据集,然后使用SMOTE算法来生成新的合成样本,使得两个类别的样本数量相等。最后原始数据集和平衡后的数据集进行可视化展示。