代码见文末
论文地址:Learning Efficient Convolutional Networks through Network Slimming
ICCV 2017 Open Access Repository
1.概述
由于边缘设备的限制,在模型的部署中经常受到模型大小、运行内存、计算量的限制。之前的方法要么只能解决其中一个问题,要么会带来精度损失。因此,论文提出能够使用BN层中的缩放因子γ实现对通道的剪枝,这种方法能够很好的解决三个问题,同时也不会带来过多的精度损失,也不需要进行额外的网络结构搜索。具体如下:
在每层卷积中,有多个特征图,例如64个特征图。但是这64个特征图不一定都重要,保留其中重要的特征图,而将不重要的特征图剪枝掉,这就是模型剪枝。因此,首先我们需要给每个特征图一个权重因子,然后保留其中重要的特征图。 这个权重因子通过BN层中的缩放因子γ实现。
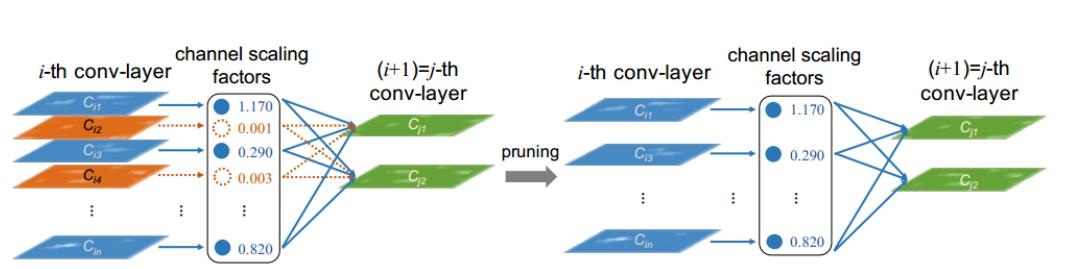
2.BN层的原理即实现
归一化是数据预处理中的一个常见步骤,主要目的是调整数值型数据的尺度,使之落在一个特定的范围,如0到1或-1到1之间。这一步骤对于很多机器学习算法的性能至关重要,尤其是那些对变量尺度敏感的算法。其主要作用如下:
促进算法效率:归一化通过将所有特征调整到相同的尺度,可以加快算法的收敛速度。特别是在使用基于梯度的优化算法时,归一化帮助保持梯度的稳定,从而加速学习过程。
增强模型性能:归一化确保没有单个特征会因尺度大而对模型训练产生不成比例的影响,这有助于提升模型在测试数据上的表现和预测的准确性。
避免数值问题:大的数值范围可能导致数值计算问题,如数值不稳定和溢出。归一化通过限制数据在一个固定范围内,帮助避免这些问题。
对抗梯度消失和爆炸:在训练深层神经网络时,归一化帮助控制梯度的传播,减轻梯度消失和梯度爆炸的问题,这是通过维持各层激活值和梯度在适当范围内实现的。
提高模型鲁棒性:归一化减少了模型对输入特征尺度的依赖,提高了模型对输入数据中的小变动或噪声的鲁棒性。
BN主要在Batch维度进行归一化,在特征图中也就是B,H,W维度,LN在层(样本)维度进行归一化。卷积一般使用BN是因为卷积的特征映射方式在整个数据集上往往是统一的。利用BN在批次维度上对这些特征进行归一化,可以有效地减少不同批次数据分布的差异。而Transformer更加强调注意力,需要捕捉每个样本自身的依赖关系,因而常用LN。
同时,BN能够有效地减轻内部协变量偏移(Internal Covariate Shift),加速训练过程。内部协变量偏移指的是由于上一层参数的更新,当前层的输入分布很可能发生了改变,而BN除了对整个Batch维度进行归一化以外,还包括了两个可学习的参数(缩放因子γ和偏移量),以便网络能够恢复到原始的数据分布。
对于每一个特征图,缩放因子γ越大,则很有可能特征图越重要,因此,我们基于缩放因子γ得到特征图的权重因子。
3.L1与L2正则化
在实际情况中,缩放因子γ可能分布比较密集,因此,在训练时使用L1正则化对参数进行稀疏化,即让更多的权重因子接近于0。
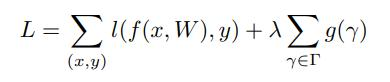
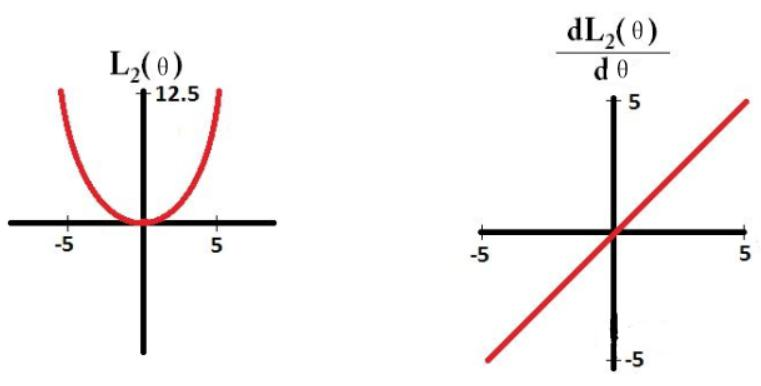
L1正则化往往具有稀疏化的作用,而L2正则化往往具有平滑化的作用。这是因为L1正则化的梯度保持恒定,最终会收敛到0,而L2正则化梯度会越来越小,收敛会越来越慢,收敛会接近于0。
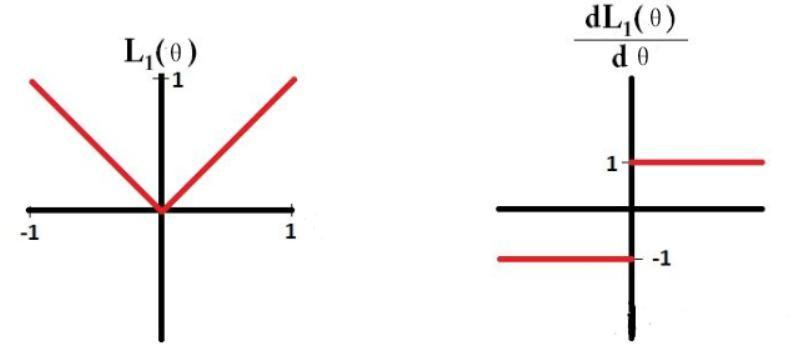
4.整体流程
整体训练流程是首先正常训练,然后缩放因子γ进行l1正则化进行再训练,第三部使用尺度因子进行剪枝,最后,对剪枝后的模型再进行微调,微调后的性能甚至会超越原来的模型。

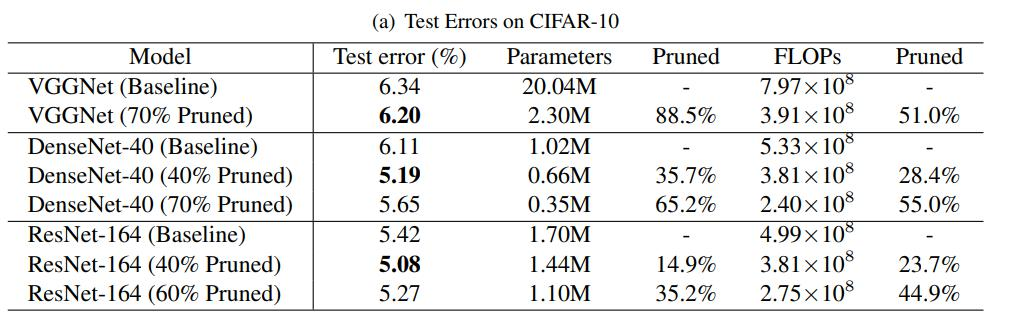
实验结果如下:
链接:https://pan.baidu.com/s/12nhoFcZWLD1_ticGprawUg?pwd=iujk
提取码:iujk