涌现能力
大语言模型的涌现能力被非形式化定义为“在小型模型中不存在但在大模型中出现的能力”,具体是指当模型扩展到一定规模时,模型的特定任务性能突然出现显著跃升的趋势,远超过随机水平。类比而言,这种性能涌现模式与物理学中的相变现象有一定程度的相似,但是仍然缺乏相应的理论解释以及理论证实,甚至有些研究工作对于涌现能力是否存在提出质疑 。整体来说,涌现能力的提出有助于使得公众认识到大语言模型所具有的能力优势,能够帮助区分大语言模型与传统预训练语言模型之间的差异。
尽管涌现能力可以定义为解决某些复杂任务的能力水平,但我们更关注可以用来解决各种任务的普适能力。下面简要介绍大语言模型的三种典型涌现能力。
上下文学习(In-context Learning, ICL)。上下文学习能力在 GPT-3 的论文中被正式提出。具体方式为,在提示中为语言模型提供自然语言指令和多个任务示例(Demonstration),无需显式的训练或梯度更新,仅输入文本的单词序列就能为测试样本生成预期的输出。在 GPT 系列模型中,175B 参数的 GPT-3 模型展现出强大的上下文学习能力,而 GPT-1 和 GPT-2 模型则不具备这种能力。此外,上下文学习能力还取决于具体的下游任务。例如,13B 参数的 GPT-3 模型可以在算术任务(例如 3 位数的加减法)上展现出上下文学习能力,但 175B 参数的 GPT-3模型在波斯语问答任务上甚至不能表现出良好的性能。
指令遵循(Instruction Following)。指令遵循能力是指大语言模型能够按照自然语言指令来执行对应的任务。为了获得这一能力,通常需要使用自然语言描述的多任务示例数据集进行微调,称为指令微调(Instruction Tuning)或监督微调(Supervised Fine-tuning)。通过指令微调,大语言模型可以在没有使用显式示例的情况下按照任务指令完成新任务,有效提升了模型的泛化能力。相比于上下文学习能力,指令遵循能力整体上更容易获得,但是最终的任务执行效果还取决于模型性能和任务难度决定。例如,FLAN-PaLM 模型测试了 8B、62B以及 540B 三个参数规模的模型在指令微调之后的效果,当参数规模达到 62B 及以上的情况,才能够在包含 23 个复杂推理任务的 BBH 评估基准上,展现出较好的零样本推理能力。对于规模相对较小的语言模型(如 2B),也可以通过使用高质量指令数据微调的方式习得一定的通用指令遵循能力(主要是简单任务,如文本摘要等)。
逐步推理(Step-by-step Reasoning)。对于小型语言模型而言,通常很难解决涉及多个推理步骤的复杂任务(如数学应用题),而大语言模型则可以利用思维链(Chain-of-Thought, CoT)提示策略来加强推理性能。具体来说,大语言模型可以在提示中引入任务相关的中间推理步骤来加强复杂任务的求解,从而获得更为可靠的答案。在思维链的原始论文中发现,对于 62B 和 540B 参数的 PaLM 模型,思维链提示可以提高其在算术推理基准上的效果,但是 8B 参数的模型则很难获得提升。进一步,思维链所带来的提升在 540B 参数的 PaLM 模型上会更加明细。此外,思维链提示对不同任务的性能提升也不完全相同,例如 PaLM 模型在三个数据集合上产生了不同的提升幅度(GSM8K > MAWPS > SWAMP)。思维链提示特别适合帮助大语言模型解决复杂数学问题,而具有思维链能力也是大语言模型能力的重要体现。
通常来说,很难统一界定大语言模型出现这些上述能力的临界规模(即具备某种能力的最小规模),因为能力涌现会受到多种因素或者任务设置的影响。最近的研究表明,经过了高质量的预训练与指令微调后,即使较小的语言模型(如 LLaMA-2 (7B))也能够一定程度上展现出上述提到的三种能力,并且对于参数规模的要求随着预训练数据规模的扩展以及数据质量的提升在不断下降。此外,现有的研究对于能力涌现的实验往往局限于少数几个模型规模。例如,PaLM 模型的相关公开研究只在 8B、62B 和 540B 三种模型规模上进行了测试,对于未测试过的模型规模的性能尚不清楚。
涌现能力与扩展法则的关系
扩展法则和涌现能力提供了两种不同观点来理解大模型相对于小模型的优势,但是刻画了较为不同的扩展效应趋势。扩展法则使用语言建模损失来衡量语言模型的整体性能,整体上展现出了较为平滑的性能提升趋势,具有较好的可预测性,但是指数形式暗示着可能存在的边际效益递减现象;而涌现能力通常使用任务性能来衡量模型性能,整体上展现出随规模扩展的骤然跃升趋势,不具有可预测性,但是一旦出现涌现能力则意味着模型性能将会产生大幅跃升。由于这两种观点反映了不同的模型性能提升趋势(持续改进 v.s. 性能跃升),可能在一些情况下会导致不一致的发现与结论。
关于涌现能力的合理性也存在广泛的争议。一种推测是,涌现能力可能部分归因于特殊任务的设置:现有评测设置中通常采用不连续的评估指标(如生成代码的准确性使用测试数据通过率评估)以及较为有限的模型参数规模(如 PaLM 技术报告里只展示了 8B、62B 和 540B 三个版本的模型)。在上述这两种情况下,很容易在下游任务的评测效果上产生不连续的变化趋势,导致了所谓的模型能力的“涌现现象”。特别地,如果针对性地修改评估指标时,或者提供更为连续的模型尺寸候选使之变得更为平滑后,涌现能力曲线的突然跃升趋势有可能会消失。这种分析一定程度上解释了模型性能的陡然跃升现象,为涌现能力的存在性打上了问号。然而,在实际使用中,用户就是以一种“不连续”的方式去感知大语言模型的性能优劣。换句话说,模型输出的正确性更为重要,用户满意度的体验过程本身就是离散的。例如,用户更倾向于使用能够正确通过所有测试用例的代码,而不愿意在两个失败代码之间选择一个包含错误较少的代码。
目前还缺少对于大语言模型涌现机理的基础性解释研究工作。与这一问题较为相关的研究叫做“顿悟”(Grokking),是指训练过程中的一种数据学习模式:模型性能从随机水平提升为高度泛化。在未来研究中,还需要更为深入的相关讨论,才能够有效解释大模型的涌现机理。通俗来讲,扩展法则与涌现能力之间微妙的关系可以类比人类的学习能力来解释。以语言能力为例,对于儿童来说,语言发展(尤其是婴儿)可以被看作一个多阶段的发展过程,其中也会出现“涌现现象”。在这一发展过程中,语言能力在一个阶段内部相对稳定,但是当进入另一个能力阶段时可能会出现重要的提升(例如从说简单的单词到说简单的句子)。尽管儿童实际上每天都在成长,但是语言的提升过程本质上是不平滑和不稳定的(即语言能力在时间上不以恒定速率发展)。因此,经常可以看到年轻的父母会对宝宝所展现出的语言能力进展感到惊讶。
GPT 系列模型的技术演变
2022 年 11 月底,OpenAI 推出了基于大语言模型的在线对话应用 — ChatGPT。由于具备出色的人机对话能力和任务解决能力,ChatGPT 一经发布就引发了全社会对于大语言模型的广泛关注,众多的大语言模型应运而生,并且数量还在不断增加。由于 GPT 系列模型具有重要的代表性,本部分内容将针对 GPT 系列模型的发展历程进行介绍,并且凝练出其中的重要技术创新。
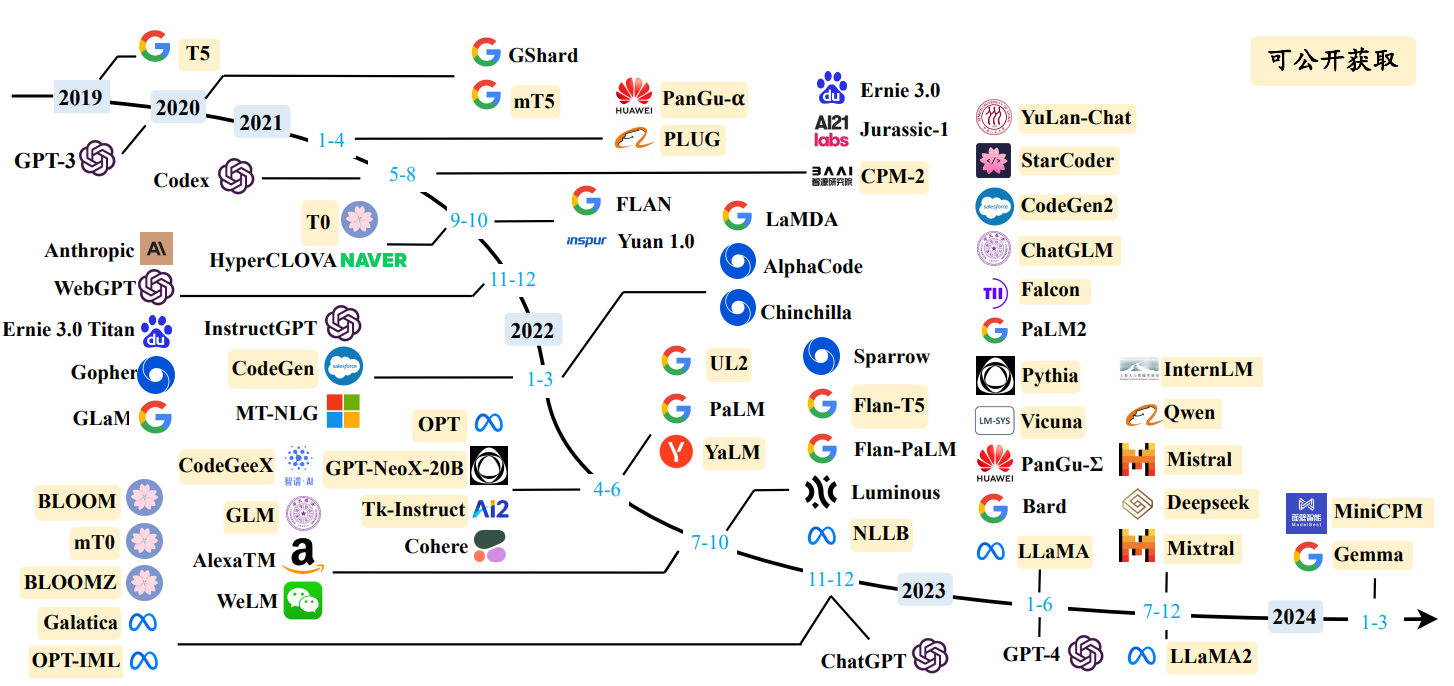
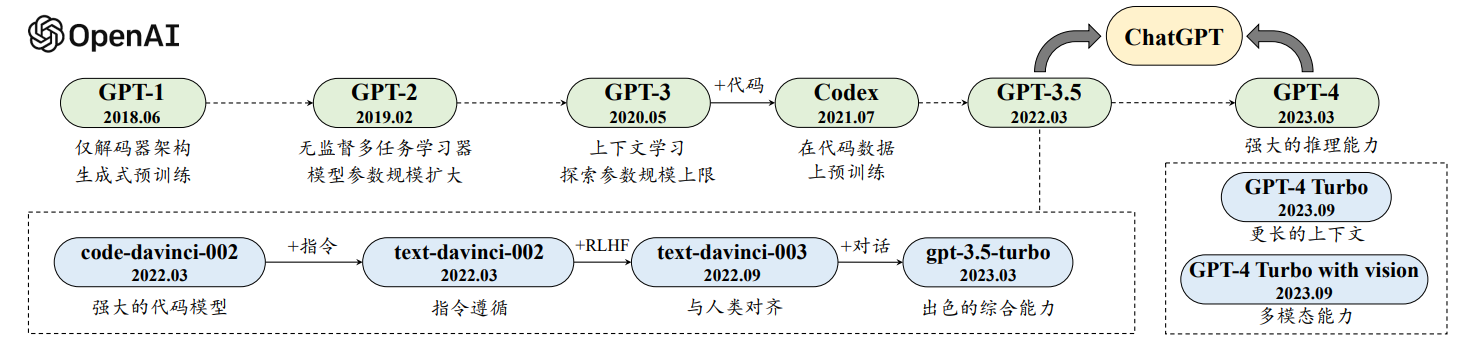
GPT 系列模型的基本原理是训练模型学习恢复预训练文本数据,将广泛的世界知识压缩到仅包含解码器(Decoder-Only)的 Transformer 模型中,从而使模型能够学习获得较为全面的能力。其中,两个关键要素是:(I)训练能够准确预测下一个词的 Transformer (只包含解码器)语言模型;(II)扩展语言模型的规模以及扩展预训练数据的规模。上图展示了 GPT 系列模型的技术演进示意图,这里主要根据 OpenAI 的论文、博客文章和官方 API 说明的信息进行绘制。该图中 实线表示在两个模型之间的进化路径上存在明确的证据(例如,官方声明新模型是基于基础模型开发的),而 虚线 表示相对较弱的进化关系。截止到目前,OpenAI 对大语言模型的研发历程大致可分为四个阶段:早期探索阶段、路线确立阶段、能力增强阶段以及能力跃升阶段,下面进行具体介绍。
早期探索
根据对于 Ilya Sutskever(OpenAI 联合创始人、前首席科学家)的采访,OpenAI在成立初期就尝试使用语言模型研发人工智能系统,但当时使用的是循环神经网络,模型能力和并行训练能力还存在较大的局限性。Transformer 刚刚问世,就引起了 OpenAI 团队的高度关注,并且将语言模型的研发工作切换到 Transformer 架构上,相继推出了两个初始的 GPT 模型,即 GPT-1和 GPT-2,这两个早期工作奠定了后续更强大的 GPT 模型(如 GPT-3 和 GPT-4)的研究基础。
GPT-1,2017 年,Google 推出 Transformer 模型后,OpenAI 团队马上意识到这种神经网络架构将显著优于传统序列神经网络的性能,有可能对于研发大型神经网络产生重要的影响。他们很快着手使用 Transformer 架构研发语言模型,并于 2018 年发布了第一个 GPT 模型,即 GPT-1,模型名称 GPT 是生成式预训练(Generative Pre-Training)的缩写。GPT-1 基于生成式、仅有解码器的 Transformer 架构开发,奠定了 GPT 系列模型的核心架构与基于自然语言文本的预训练方式,即预测下一个词元。由于当时模型的参数规模还相对较小,模型仍然缺乏通用的任务求解能力,因而采用了无监督预训练和有监督微调相结合的范式。与 GPT-1 同期发布的预训练语言模型是大名鼎鼎的 BERT 模型。BERT 与 GPT-1 虽然都采用了基于 Transformer 架构的预训练学习方式,但是它主要面向自然语言理解任务(Natural Language Understanding, NLU),为此只保留了 Transformer 中的编码器,其中 BERT-Large 模型在众多的自然语言理解任务上取得了非常重要的提升,成为当时备受瞩目的“明星模型”。可以说,BERT 当时引领了自然语言处理社区的研究浪潮,涌现了大量针对它改进与探索的工作。由于 GPT-1 模型规模实际上与小规模的 BERT-Base 模型相当(100M 左右参数),在公开评测数据集合上的性能尚不能达到当时众多竞争模型中的最优效果,没有引起学术界的足够关注。
GPT-2,GPT-2 沿用了 GPT-1 的类似架构,将参数规模扩大到 1.5B,并使用大规模网页数据集 WebText 进行预训练。与 GPT-1 不同,GPT-2 旨在探索通过扩大模型参数规模来提升模型性能,并且尝试去除针对特定任务所需要的微调环节。这点在 GPT-2 的论文中得到了着重论述,它试图使用无监督预训练的语言模型来解决各种下游任务,进而不需要使用标注数据进行显式的模型微调。形式化来说,多任务学习(Multi-task Learning)可以通过一种较为通用的概率形式刻画,即 𝑃(output|input, task)——根据输入和任务信息来预测输出。为了建立通用的多任务学习框架,GPT 系列模型将输入、输出和任务信息都通过自然语言形式进行描述,进而后续任务的求解过程就可以看作是任务方案(或答案)的文本生成问题。OpenAI 团队在 GPT-2 的论文中还尝试解释无监督预训练在下游任务中取得良好效果的原因:“由于特定任务的有监督学习目标与无监督学习目标(语言建模)在本质上是相同的(预测下一个词元),主要区别就在于它们只是在全部训练数据的子集上进行优化,因此对于特定下游任务而言,优化无监督的全局学习目标本质上也是在优化有监督的任务学习目标”。对这一说法的通俗理解是,语言模型将每个(自然语言处理)任务都视为基于世界文本子集的下一个词预测问题。因此,如果无监督语言建模经过训练后具有足够的能力复原全部世界文本,那么本质上它就能够解决各种任务。这些 GPT-2 论文中的早期讨论与 Ilya Sutskever 在接受 Jensen Huang 采访时的观点非常类似:“神经网络学到的是生成文本的过程中的某种表示,这些模型的生成文本实际上是真实世界的投影……(语言模型)对下一个单词的预测越准确,(对于世界知识)保真度就越高,在这个过程中获得的分辨度就越高……”。
规模扩展
虽然 GPT-2 的初衷是成为一个“无监督多任务学习器”,但在很多任务上与有监督微调方法相比,模型效果整体上还是要逊色一些。在 GPT-2 基础上,GPT-3 针对(几乎相同的)模型参数规模进行了大幅扩展,在下游任务中初步展现出了一定的通用性(通过上下文学习技术适配下游任务),为后续打造更为强大的模型确立了关键的技术发展路线。
GPT-3,OpenAI 在 2020 年发布了 GPT-3 模型,将模型参数扩展到了 175B 的规模。与 GPT-2 相比,GPT-3 直接将参数规模提升了 100 余倍,对于模型扩展在当时给出了一个极限尝试,其雄心、魄力可见一斑。值得一提的是,OpenAI 的两篇关于扩展法则的论文都是在 2020 年发表的,这说明在 GPT-3 开始训练时可能已经进行了比较充分的实验探索,包括小版本模型的尝试、数据收集与清洗、并行训练技巧等。在 GPT-3 的论文中,它正式提出了“上下文学习”这一概念,使得大语言模型可以通过少样本学习的方式来解决各种任务。上下文学习可以指导大语言模型学会“理解”自然语言文本形式描述的新任务,从而消除了针对新任务进行微调的需要。基于这一学习范式,大语言模型的训练与利用可以通过语言建模的形式进行统一描述:模型预训练是在给定上下文条件下预测后续文本序列,模型使用则是根据任务描述以及示例数据来推理正确的任务解决方案。GPT-3 不仅在各种自然语言处理任务中表现出了优异的效果,对于一些需要复杂推理能力或领域适配能力的特定任务也具有较好的解决能力。虽然 GPT-3 的论文没有明确提出上下文学习能力是大语言模型的涌现能力,但是指出了上下文学习对于大模型的性能增益会更加显著,而对于小模型来说则收益较小(见 GPT-3 论文的)。总体而言,GPT-3 可以被看作从预训练语言模型到大语言模型演进过程中的一个重要里程碑,它证明了将神经网络扩展到超大规模可以带来大幅的模型性能提升,并且建立了以提示学习方法为基础技术路线的任务求解范式。
能力增强
由于具有较强的模型性能,GPT-3 成为 OpenAI 开发更强大的大语言模型的研究基础。根据公开资料披露的内容来说,OpenAI 探索了两种主要途径来改进GPT-3 模型,即代码数据训练和人类偏好对齐。
代码数据训练,原始的 GPT-3 模型的复杂推理任务能力仍然较弱,如对于编程问题和数学问题的求解效果不好。为了解决这一问题,OpenAI 于 2021 年 7 月推出了 Codex,这是一个在大量 GitHub 代码数据集合上微调的 GPT 模型。实验结果表明,Codex 可以解决非常困难的编程问题,还能显著提升大模型解决数学问题的能力。此外,2022 年 1 月 OpenAI 还公开了一种用于训练文本和代码嵌入的对比方法,结果表明该方法能够改善一系列相关任务的性能,包括线性探测分类、文本搜索和代码搜索等。根据 OpenAI 所发布的 API 信息所示,GPT-3.5模型是在基于代码训练的 GPT 模型(即 code-davinci-002)基础上开发的,这表明在代码数据上进行训练有助于提高 GPT 模型的综合性能,尤其是代码能力。另一个可能的启发是对于可用于预训练的数据范围的扩展,可能并不局限于自然语言形式表达的文本数据。
人类对齐,OpenAI 关于人类对齐的公开研究工作可以追溯到 2017 年(实际时间或更早)。在一篇题为“Learning from Human Preferences”的博客文章中,OpenAI 的研究团队介绍了一项使用强化学习算法从人类标注的偏好数据中学习如何改进模型性能的工作。在这篇强化学习工作发表不久,2017 年 7 月 OpenAI 研究团队又提出了一项改进的强化学习算法— PPO 算法(Proximal Policy Optimization, PPO),这也成为了 OpenAI 在后续人类对齐技术里所采用的标配强化学习算法。在 2020 年,OpenAI 研究团队将人类对齐算法应用于提升自然语言处理任务上的能力,训练了一个根据人类偏好进行优化的摘要模型。以这些前期工作为基础上,2022 年 1 月,OpenAI 正式推出 InstructGPT 这一具有重要影响力的学术工作,旨在改进 GPT-3 模型与人类对齐的能力,正式建立了基于人类反馈的强化学习算法,即 RLHF 算法。值得一提的是,在 OpenAI 的论文和相关文档中,很少使用“指令微调”(Instruction Tuning)一词,主要是使用“监督微调”一词(即基于人类反馈的强化学习算法的第一步)。除了提高指令遵循能力,基于人类反馈的强化学习算法有助于缓解有害内容的生成,这对于大语言模型在实际应用中的安全部署非常重要。OpenAI 在一篇技术博客文章中描述了他们对齐研究的技术路线,并总结了三个有前景的研究方向:训练人工智能系统以达到(1)使用人类反馈、(2)协助人类评估和(3)进行对齐研究。通过这些增强技术,OpenAI 将改进后的具有更强能力的 GPT 模型命名为 GPT3.5 模型。
性能跃升
在历经上述近五年的重要探索,OpenAI 自 2022 年底开始发布了一系列重要的技术升级,其中具有代表性的模型是 ChatGPT、GPT-4 以及 GPT-4V/GPT-4 Turbo,这些模型极大提高了现有人工智能系统的能力水平,成为了大模型发展历程中的重要里程碑。
ChatGPT,2022 年 11 月,OpenAI 发布了基于 GPT 模型的人工智能对话应用服务 ChatGPT。OpenAI 官方博客文章概要地介绍了 ChatGPT 的研发技术,主要是沿用了 InstructGPT(原帖中称 ChatGPT 为“InstructGPT 的兄弟模型”)的训练技术,但是对于对话能力进行了针对性优化。在训练数据的收集过程中,ChatGPT将人类生成的对话数据(同时扮演用户和人工智能的角色)与训练 InstructGPT 的相关数据进行结合,并统一成对话形式用于训练 ChatGPT。ChatGPT 在与人机对话测试中展现出了众多的优秀能力:拥有丰富的世界知识、复杂问题的求解能力、多轮对话的上下文追踪与建模能力、与人类价值观对齐的能力等。在后续的版本更迭中,ChatGPT 进一步又支持了插件机制,通过现有工具或应用程序扩展了它 的功能,能够超越以往所有人机对话系统的能力水平。ChatGPT 一经推出就引发了社会的高度关注,对于人工智能的未来研究产生了重要影响。
GPT-4,继 ChatGPT 后,OpenAI 于 2023 年 3 月发布了 GPT-4,它首次将GPT 系列模型的输入由单一文本模态扩展到了图文双模态。总体来说,GPT-4 在解决复杂任务方面的能力显著强于 GPT-3.5,在一系列面向人类的考试中都获得了非常优异的结果。GPT-4 发布后,微软的研究团队针对其进行了大规模人类生成问题的性能测试,实验结果表明 GPT-4 具有令人震撼的模型性能,论文作者认为 GPT-4 的到来展现出了通用人工智能的曙光。此外,由于进行了为期六个月的迭代对齐(在基于人类反馈的强化学习中额外增加了安全奖励信号),GPT-4 对恶意或挑衅性查询的响应更加安全。在技术报告中,OpenAI 强调了安全开发GPT-4 的重要性,并应用了一些干预策略来缓解大语言模型可能出现的问题——幻觉、隐私泄露等。例如,研究人员引入了“红队攻击”(Red Teaming)机制来减少生成有害或有毒的内容。更重要的是,GPT-4 搭建了完备的深度学习训练基础架构,进一步引入了可预测扩展的训练机制,可以在模型训练过程中通过较少计算开销来准确预测模型的最终性能。
GPT-4V、GPT-4 Turbo以及多模态支持模型. 基于发布的GPT-4初版模型,OpenAI 在 2023 年 9 月进一步发布了 GPT-4V,重点关注 GPT-4 视觉能力的安全部署。在 GPT-4V 的系统说明中,广泛讨论了与视觉输入相关的风险评估手段和缓解策略。GPT-4V 在多种应用场景中表现出了强大的视觉能力与综合任务解决能力。在 2023 年 11 月,OpenAI 在开发者大会上发布了升级版的 GPT-4 模型,称为 GPT-4 Turbo,引入了一系列技术升级:提升了模型的整体能力(比 GPT-4 更强大),扩展了知识来源(拓展到 2023 年 4 月),支持更长上下文窗口(达到 128K),优化了模型性能(价格更便宜),引入了若干新的功能(如函数调用、可重复输出等)。同时,Assistants API 功能也被推出,旨在提升人工智能应用助手的开发效率, 开发人员可以利用特定的指令、外部知识和工具,在应用程序中快速创建面向特定任务目标的智能助手。此外,新版本的 GPT 模型还进一步增强了多模态能力,分别由 GPT-4 Turbo with Vision、DALL·E-3、TTS(Text-to-speech)以及 Listen to voice samples 等支持实现。这些技术升级进一步提高了 GPT 模型的任务性能,扩展了 GPT 模型的能力范围。更重要的是,随着模型性能和支撑功能的改进,极大地加强了以 GPT 模型所形成的大模型应用生态系统。
尽管 GPT 系列模型取得了巨大的科研进展,这些最前沿的大语言模型仍然存在一定的局限性。例如,GPT 模型可能在某些特定上下文中生成带有事实错误的内容(即幻觉)或存在潜在风险的回应。更多针对大语言模型局限性的讨论从人工智能的发展历程来看,开发能力更强、更安全的大语言模型是一项长期的研究挑战。为了有效降低使用模型的潜在风险, OpenAI 采用了迭代部署策略,通过多阶段开发和部署的生命周期来研发模型与产品。