实现高效特征选择与模型优化
在大数据时代,我们面临着从海量特征中筛选出关键信息,以构建高效预测模型的挑战。拉索回归(Lasso Regression)作为一种正则化技术,通过引入L1范数作为惩罚项,不仅有助于克服多重共线性问题,还能实现特征选择,提升模型的泛化能力。本文将结合实例和代码,深入探讨拉索回归及其关键算法——坐标下降法的原理和应用。
一、拉索回归的原理与优势
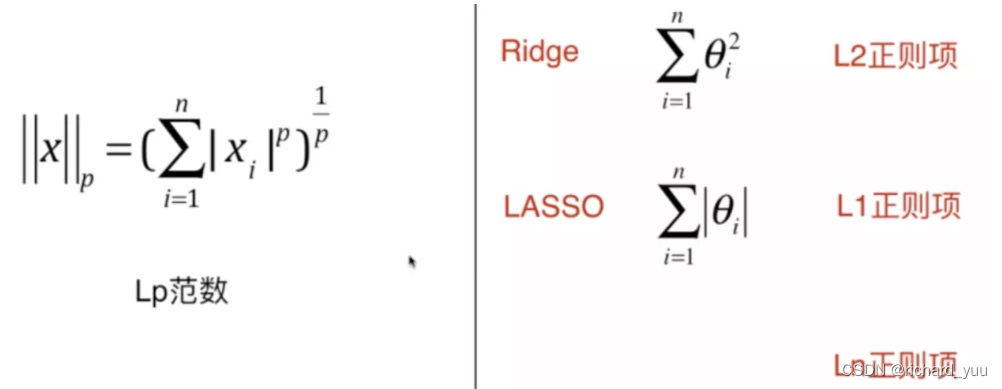
拉索回归是一种线性回归模型的扩展,其目标函数在最小二乘损失的基础上增加了一个L1正则化项。这个正则化项是所有系数绝对值的和,乘以一个非负的调节参数λ。通过调整λ的值,我们可以在拟合数据和简化模型之间找到平衡。
拉索回归的关键优势在于其稀疏性。当λ足够大时,一些系数会被压缩至零,从而实现特征选择。这不仅降低了模型的复杂度,还提高了模型的可解释性。在高维数据中,这种自动特征选择的能力尤为重要,因为它能帮助我们识别出真正对预测结果有影响的变量。
二、坐标下降法的实现
坐标下降法是一种用于求解优化问题的迭代算法,特别适用于具有可分离结构的凸优化问题。在拉索回归中,我们可以使用坐标下降法来高效求解带有L1正则化项的目标函数。
下面是一个简单的Python代码示例,展示了如何使用坐标下降法实现拉索回归:
python
import numpy as np
def lasso_coordinate_descent(X, y, lambda_param, max_iter=1000, tol=1e-4):
"""
使用坐标下降法实现拉索回归
X: 特征矩阵
y: 目标变量
lambda_param: 正则化参数λ
max_iter: 最大迭代次数
tol: 收敛阈值
"""
n_samples, n_features = X.shape
w = np.zeros(n_features) # 初始化权重向量
for _ in range(max_iter):
for i in range(n_features):
# 计算残差
r = y - np.dot(X, w) + w[i] * X[:, i]
# 计算相关系数
corr = np.dot(X[:, i], r)
# 计算软阈值
soft_threshold = np.sign(corr) * np.maximum(0, np.abs(corr) - lambda_param)
# 更新权重
w[i] = soft_threshold / np.dot(X[:, i], X[:, i])
# 检查收敛性
if np.linalg.norm(w - w_old) < tol:
break
w_old = w.copy()
return w
# 示例数据
X = np.array([[1, 2], [3, 4], [5, 6]])
y = np.array([7, 8, 9])
lambda_param = 0.1
# 使用坐标下降法求解拉索回归
w = lasso_coordinate_descent(X, y, lambda_param)
print("Lasso coefficients:", w)
在上面的代码中,我们定义了一个lasso_coordinate_descent函数,它接受特征矩阵X、目标变量y、正则化参数lambda_param、最大迭代次数max_iter和收敛阈值tol作为输入。函数内部通过两层循环实现坐标下降法的迭代过程,外层循环控制迭代次数,内层循环依次更新每个权重系数。在每次内层循环中,我们计算残差、相关系数和软阈值,并据此更新权重系数。最后,我们检查权重向量的变化是否小于收敛阈值,以判断算法是否收敛。
三、总结与展望
拉索回归通过引入L1正则化项,实现了特征选择和模型优化的双重目标。坐标下降法作为一种高效的优化算法,为拉索回归的求解提供了有力支持。通过结合实例和代码,本文展示了拉索回归和坐标下降法的原理及实现过程。未来,随着大数据和机器学习技术的不断发展,我们期待拉索回归及其相关算法在更多领域得到应用,为数据分析和决策支持提供更加精准和高效的工具。