哈夫曼树和哈夫曼编码
哈夫曼树
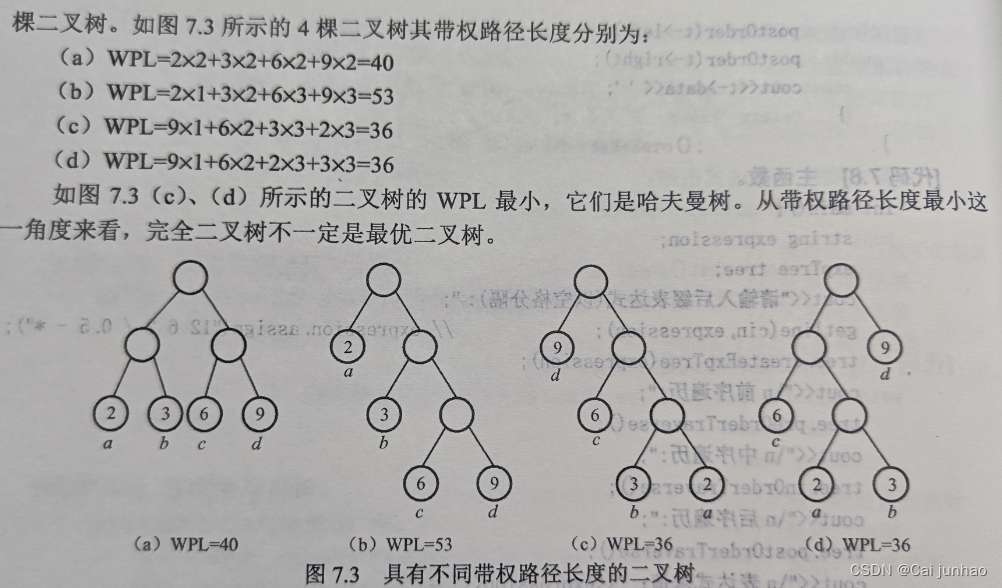
哈夫曼树又称为最优二叉树,是带权路径长度(WPL)最短的树
基本概念
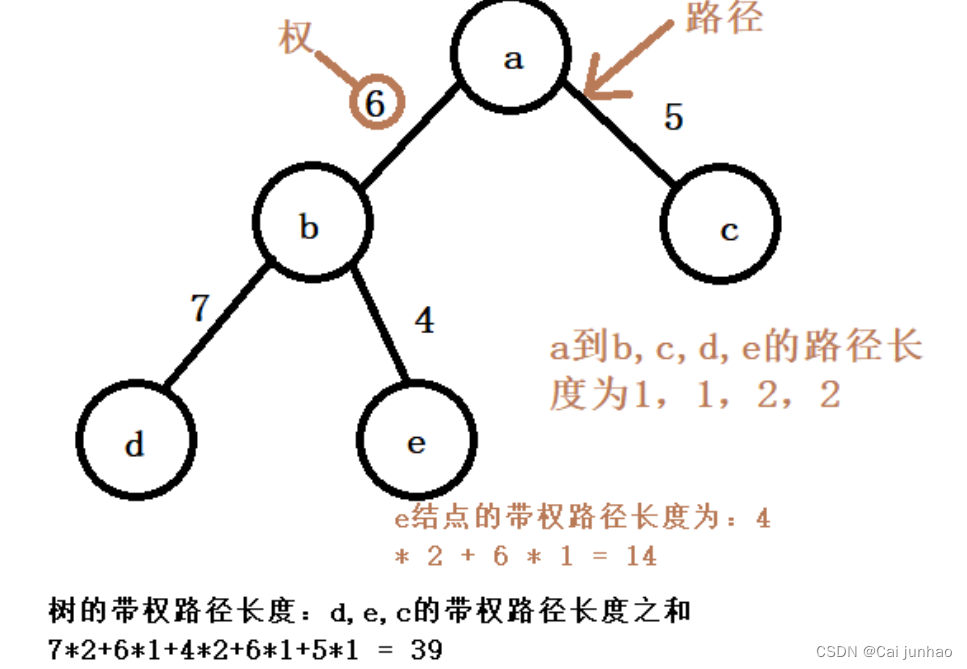
路径:从树中的一个结点到另一个结点之间的分支构成这两点之间的路径
路径长度:路径上的分支数目
权:赋予某个实体的一个量
树的路径长度:从树根到每一个结点的路径长度之和
结点的带权路径长度:从该结点到根结点之间的路径长度与结点上权的乘积
树的带权路径长度(WPL):树中所有叶子结点的带权路径长度之和
特点
(1)有n个叶结点的哈夫曼树共有2n-1个结点。
(2)权值越大的叶结点,离根节点越近;权值越小的叶结点,离根节点越远;
(3)哈夫曼树是正则二叉树,只有度为0和度为2的结点。
(4)哈夫曼树的左右子树可互换,形状不唯一,但WPL是相同。
构造哈夫曼树:
(1)把结点从小到大排序
(2)把权值最小的两个结点,分别作为左右子树构造一颗二叉树。
(3)在排序把删除步骤二用的两个小结点,添加他们的结点之和。
(4)重复步骤二、三。
具体例子可见:哈夫曼树原理、画法和具体例子
哈夫曼树的类型定义及运算如下:
#include<iostream>
#ifndef _HUFFMAN_TREE_H_
#define _HUFFMAN_TREE_H_
using namespace std;
template <class T>
class huffmanTree{
private:
struct Node{
T data; // 结点数据域
int weight; // 结点的权值
int parent, left, right; // 双亲及左右孩子的下标
Node() { // 构造函数
weight = parent = left = right = 0;
};
};
struct huffmanCode {
T data;
string code; // 保存data的哈夫曼编码
huffmanCode(){ code=""; } // 构造函数
};
Node *hfTree; // 顺序结构,保存huffman树
huffmanCode *hfCode; // 顺序结构,保存结点的huffman编码
int size; // 叶结点数
void selectMin(int m,int& p); // 选出当前集合中的最小元素
public:
huffmanTree(int initSize); // 构造函数
~huffmanTree() {delete [] hfTree;delete []hfCode;} // 析构函数
void createHuffmanTree(const T *d, const int *w);//创建哈夫曼树
void huffmanEncoding(); // 获取huffman编码
void printHuffmanCode(); // 输出huffman编码
};
(1)size个叶结点的哈夫曼树共有2size-1个结点,故哈夫曼树可用一个2size的数组hfTree来存储。数组下标为0的不用,根节点存放在下标为1的单元。
(2)parent域有两个作用:第一,在构造时,用于区别结点是否被使用过。parent=0表示该结点没有双亲,还未被使用过。第二,在构造后求哈夫曼编码,需从叶结点出发走一条从叶结点到根结点的路径,因此需要知道结点的双亲的信息。
(3)每个huffmanCode类型保存的信息有:数据域data以及编码code。因哈夫曼树有size个叶结点,故哈夫曼编码可以用一个大小为size的huffmanCode类型的数组hfCode来存储。
构造函数
template <class T>
huffmanTree<T>::huffmanTree(int initSize){
size = initSize; // size为初始集合中的结点数
hfTree = new Node[2*size]; //顺序存储结构
hfCode = new huffmanCode[size]; //哈夫曼编码
}
创建哈夫曼树
根据叶结点数据数组v及权值数w创建哈夫曼树
template <class T>
void huffmanTree<T>::createHuffmanTree(const T *d, const int *w) {
int i, min1, min2; //最小数、次最小数的下标
for (i = size;i < 2*size;++i) { //给size个叶结点赋值
hfTree[i].data = d[i-size];
hfTree[i].weight = w[i-size];
}
for (i = size-1;i > 0;--i) { //合并产生size-1个新结点
//选出选出paretent的值为0且权值最小的两个子树min1,min2作为结点i的左右孩子
selectMin(i+1,min1);
hfTree[min1].parent = i;
selectMin(i+1,min2);
hfTree[min2].parent = i;
hfTree[i].weight = hfTree[min1].weight + hfTree[min2].weight;
hfTree[i].left = min1;
hfTree[i].right = min2;
}
}
选出paretent的值为0且权值最小的子树的根节点,并记录下标。
template<class T>
void huffmanTree<T>::selectMin(int m,int& p){
int j = m;
while (hfTree[j].parent != 0) { //跳过已有双亲的结点
j++;
}
for (p = j,j+=1;j < 2*size;j++) { //向后扫描剩余元素
if ( (hfTree[j].weight < hfTree[p].weight) && 0 == hfTree[j].parent) {
p = j; //发现更小的记录,记录它的下标
}
}
}
函数selectMin被定义在名为huffmanTree的模板类中,该类用于构建 Huffman 树。
参数m表示当前已经构建的节点数目。
函数通过遍历hfTree数组来找到权重最小的节点。hfTree数组存储了 Huffman 树的节点信息,其中hfTree[i].weight表示第i个节点的权重,hfTree[i].parent表示第i个节点的父节点在数组中的索引,如果为 0 表示没有父节点。
首先,函数通过循环跳过已经有父节点的节点,以找到尚未构建子树的节点。这是因为在构建 Huffman 树时,每次都是选择两个权重最小的节点进行合并,而已经有父节点的节点已经被合并到其他节点中了,所以不再考虑。
然后,从剩余的未被合并的节点中选择权重最小的节点。它通过遍历数组并比较节点的权重来实现。在每次循环中,如果发现当前节点的权重比记录的最小权重还要小,并且该节点没有父节点(即还未被合并),则更新记录的最小权重节点的索引。
最终,函数返回权重最小的节点的索引p,用于后续的树节点合并操作
哈夫曼编码
前缀编码:任一字符的编码都不是另一个字符的编码的前缀。
哈夫曼编码:利用哈夫曼算法可以得到最优的前编码
构造哈夫曼编码的方式:
将信息中各字符出现的频率作为权值来构造一颗哈夫曼树,每个带权叶结点都对应一个字符,根结点到叶结点都有一条路径。我们约定指向左子树用0表示,右子树用1表示,则从根节点到每个叶结点的0、1码序列的字符为哈夫曼编码。
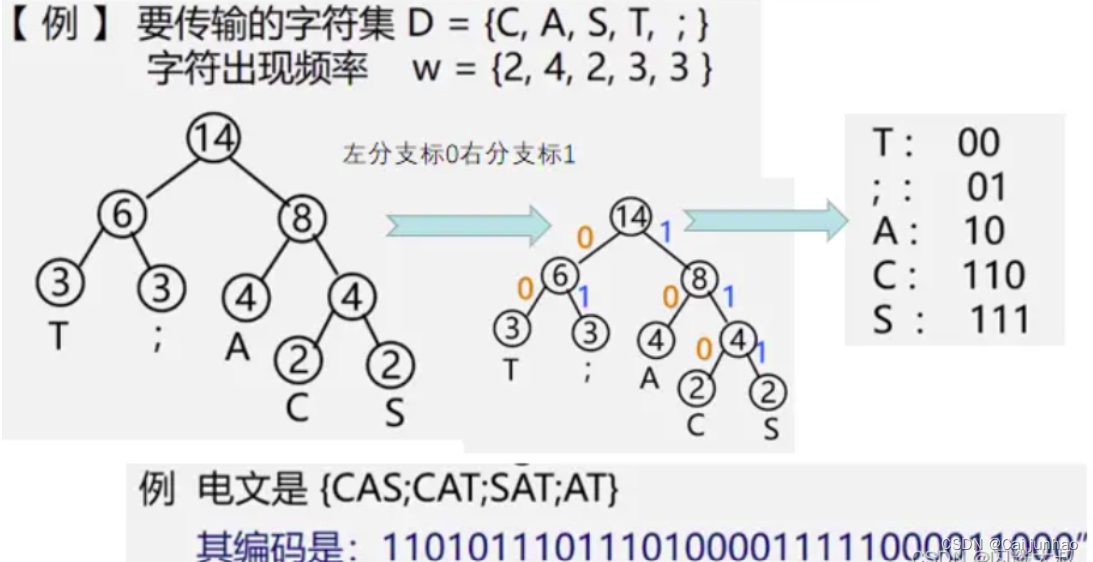
根据哈夫曼树的每个叶结点生成哈夫曼编码:
template <class T>
void huffmanTree<T>::huffmanEncoding(){
int f, p; //p是正在处理的结点,f是p的双亲的下标
for (int i = size;i < 2*size;++i) {
hfCode[i - size].data = hfTree[i].data;
p = i;
f = hfTree[p].parent;
while (f) {
if (hfTree[f].left == p) { //p是其双亲f的左孩子,编码+‘\0’
hfCode[i - size].code = '0' + hfCode[i - size].code;
} else { //p是其双亲f的右孩子,编码+‘1’
hfCode[i - size].code = '1' + hfCode[i - size].code;
}
p = f;
f = hfTree[p].parent;
}
}
}
输出叶结点及其哈夫曼编码
template<class T>
void huffmanTree<T>::printHuffmanCode(){
for (int i=0; i< size; i++)
cout<< hfCode[i].data <<' '<< hfCode[i].code << endl;
}
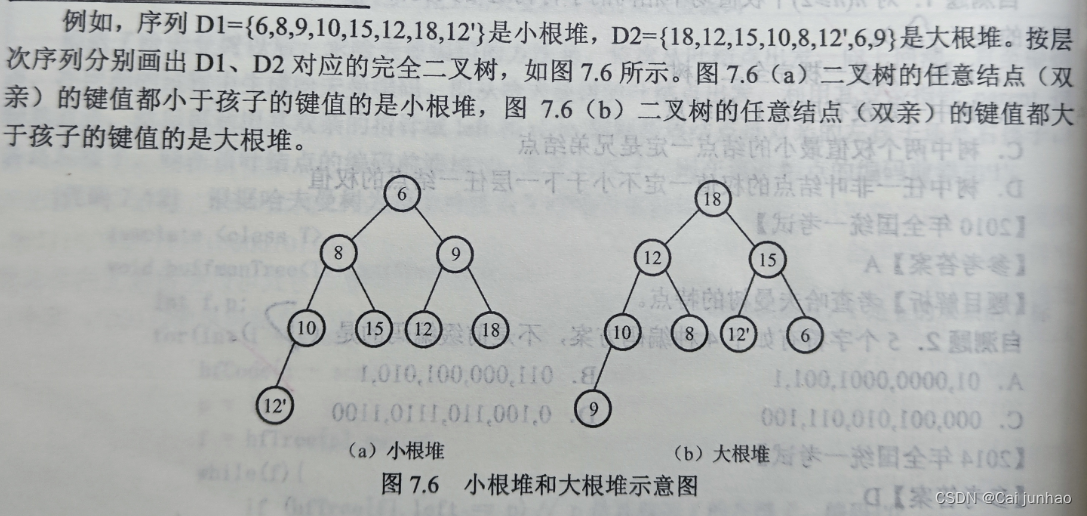
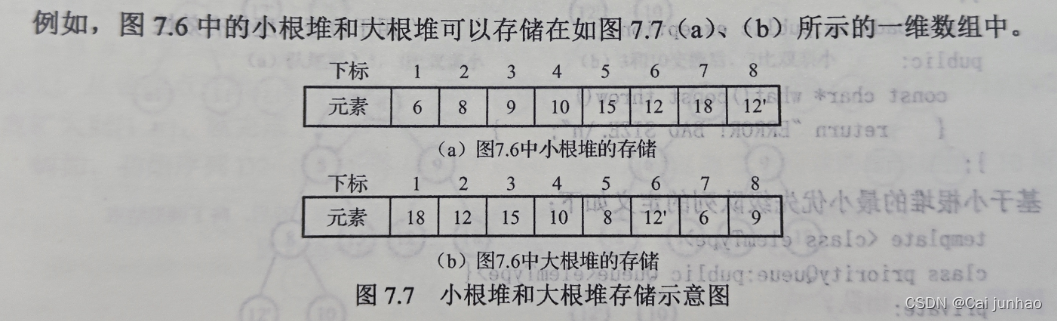
堆和优先级队列
堆
结构性:可看成一颗完全二叉树
有序性:任何一个结点的键值不大于(或不小于)其左、右孩子的键值
最大堆,也称大根堆或大堆:根结点是序列中的最大值。
最小堆,也称小根堆或小堆:根结点是序列中的最小值。
前面介绍过,完全二叉树适合用顺序存储结构表示和实现,因此堆可以用一维数组实现。
优先级队列
优先级队列每个元素都有一个优先级,元素出队的先后次序由优先级的高低决定,而不是由入队的先后次序决定。优先级高的先出队,优先级低的后出队。
特点:可以从一个集合快速地查找和删除具有最大值或最小值的元素。
最小优先级队列适合查找和删除最小元素。
最大优先级队列适合查找和删除最大元素。
对有n个结点的堆,从结点从1到n进行编号,数组0号单元不使用,对任意结点,若i=1,则结点i为根,无双亲;若i>1,则结点i的双亲的编号i/2。若2i<=n,则i的左孩子是2i;若2i+1<=n,则i的右孩子是2i+1。
对于一个树高度为h,包含了N=2h+1-1个结点的满二叉树,结点高度为N-h-1;
基于小根堆的最小优先级队列的定义:
template <class elemType>
class priorityQueue{
private:
int curLength; //队列中元素个数
elemType *data; //指向存放元素的数组
int maxSize; //队列的大小
void resize(); //扩大队列空间
void siftDown(int parent); //从parent位置向下调整优先级队列
void siftUp(int position); //从position位置向上调整优先级队列
public:
priorityQueue(int initSize=100); //创建容量为0的空的优先队列
priorityQueue(const elemType data[], int size); //用给定键值数据创建优先级队列
~priorityQueue(){ delete [] data; }
bool empty()const{ return curLength==0; } //判空
int size()const{ return curLength; } //求长度
void buildHeap(); //建堆
void enQueue(const elemType & x); //入队
elemType deQueue(); //出队
elemType getHead()const{ //取队首长度
if(empty()) throw outOfRange();
return data[1];
}
}
入队
算法思想:小根堆结点个数为n,插入一个新元素时,放在数组末尾,其编号为i=n+1。
如果结点i的键值小于其双亲i/2的键值,则交换元素,直到结点i的键值不小于双亲的键值或者i到达根结点。
时间复杂度O(logn)
template <class elemType>
void priorityQueue<elemType>::enQueue(const elemType & x){
if(curLength==maxSize-1) resize();
data[++curLength]=x; //下标从1开始
siftUp(curLength); //新入队元素需向上调整
}
向上调整堆
当双亲的键值大时,采用向下移动双亲数据的策略,而不是交换数据。
template <class elemType>
void priorityQueue<elemType>::siftUp(int position){ //从position开始向上调整
elemType temp=data[position]; //保存position位置元素
for(;position>1 && temp<data[position/2];position/=2)
data[position]=data[position/2]; //position位置元素比双亲小,双亲下移
data[position]=temp;
}
出队(删除)
算法思想:在小根堆删除一个元素时,该元素必定在数组下标为1处的根结点中;删除根结点后元素个数变为n-1,为保持完全二叉树,将下标为n的叶结点暂存在下标为1的根结点中。
如果结点i的键值大于其较小孩子的键值,则交换元素,直到结点i的键值不大于其较小孩子的键值或者i到达叶结点。
时间复杂度O(logn)
template <class elemType>
void priorityQueue<elemType>::deQueue(const elemType & x){
if(empty()) throw outOfRange();
elemTpye min;
min=data[1]; //保存最小元素
data[1]=data[curLength--]; //队尾元素存入下标1位置(堆顶)
siftDown(1); //从队首向下调整
return min; //返回队首元素
向下调整堆
当孩子的键值较小时,采用向上移动较少的孩子数据的策略,而不是交换数据。
template <class elemType>
void priorityQueue<elemType>::siftDown(int parent){
int child;
elemType temp=data[parent];
for(; parent*2<=curLength; parent=child){
child = parent * 2;
if(child != curLength && data[child+1] < data[child])
child++;
if(data[child]<tmp) data[parent]=data[child];
else break;
}
data[parent] = tmp;
}
建堆(自下而上)
自顶向下建堆法:首先初始化一个空的优先级队列,然后连续性进行n次入队操作。
时间复杂度O(NlogN)
自下向上建堆法:将给定的序列看成一颗完全二叉树,然后从最后一个分支结点一直根结点,调用n/2次向下调整算法,把它调整为堆.
时间复杂度O(n)
template <class elemType>
void priorityQueue<elemType>::buildHeap(){
for(int i =curLength/2; i>0; i--)
siftDown(i); //[curLength/2...1]从下标最大的分支结点开始调整
}
其他
构造空堆
只有初始大小,无初始序列,建堆时需调用入队操作。
template <class elemType>
priorityQueue<elemType>::priorityQueue(int initSize=100){
if(initSize<=0) throw badSize();
data = new elemType[initSize];
maxSize = initSize;
curLength=0;
}
构造无序堆
有初始大小和初始序列,使用堆之前需要调用buildHeap()建堆。
template <class elemType>
priorityQueue<elemType>::priorityQueue(const elemType *item, int size){
data = new elemType[maxSize];
for(int i=0;i<size; i++)
data[i+1]=items[i];
}
扩大堆空间
template <class elemType>
void priorityQueue<elemType>::resize(){
elemType * tmp = data; //tmp指向原堆空间
maxSize *=2; //堆空间扩大2倍
data = new elemType[maxSize]; //data指向新的堆空间
for(int i=0; i<curLength ; ++i)
data[i]=tmp[i];
delete [] tmp;
}
习题(含408)
1.【408真题】下列选项给出的是从根分别到达两个叶结点路径上的权值序列,能属于同一棵哈夫曼树的是()
A.24,10,5和24,10,7
B.24,10,5和24,12,7
C.24,10,10和24,14,11
D.24,10,5和24,14,6

选D
2.求根据以权值{2,5,7,9,12}构造的哈夫曼树所构造的哈夫曼编码中最大的长度。
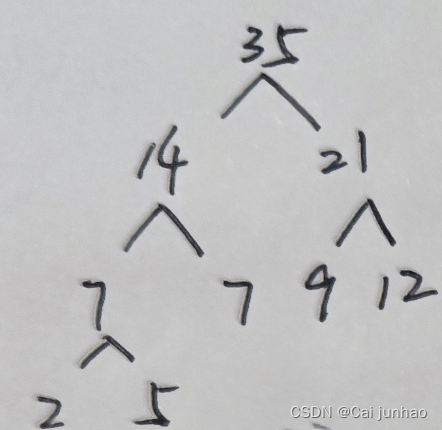
注意求的是编码的长度。
3.一份电文中右6个字符:a,b,c,d,e,f,他们的出现频率依次为2,3,4,7,8,9,构造一颗哈夫曼树,并求WPL和字符c的编码。

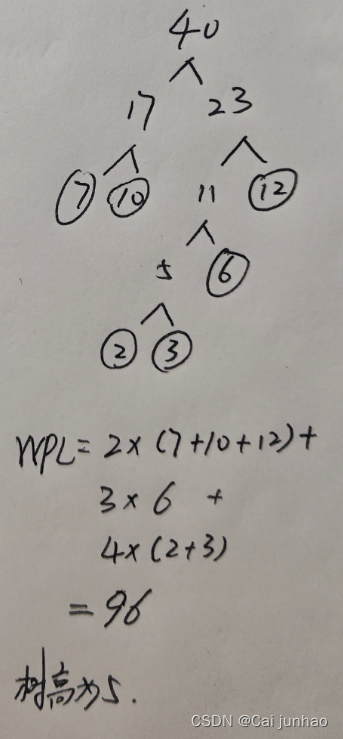
WPL=80; c的编码为110
4.一组数据{6,2,7,10,3,12},用其构造一颗哈夫曼树,求树高和WPL