笔者不是专业的实时数仓架构,这是笔者从其他人经验和网上资料整理而来,仅供参考。写此文章意义,加深对实时数仓理解。
实时数仓背景和场景
一、实时数仓架构技术演进
1.1、四种架构演进
1)离线大数据架构
一种批处理离线数据分析架构,通过采用Hadoop技术栈,采用任务调度工具+小时/分钟级别调度任务方式,达到小时/分钟级别的实时数据分析。
2)Lambda架构
一种以批处理为主的离线数据分析架构,它将数据处理分为实时和离线两部分,其中离线部分通过批量计算来处理数据,实时部分则通过增量追加方式将数据合并到批处理结果中。

优势:满足实时处理低延迟需要,数据修正计算资源消耗少。
劣势:同样的需求需要开发两套一样的代码。后期维护困难,数据一致性得不到保证。
3)Kappa架构
一种以流处理为主的实时数据分析框架,它将实时数据直接存储在Kafka等消息队列中,并通过流处理器将数据转换为目标数据模型。
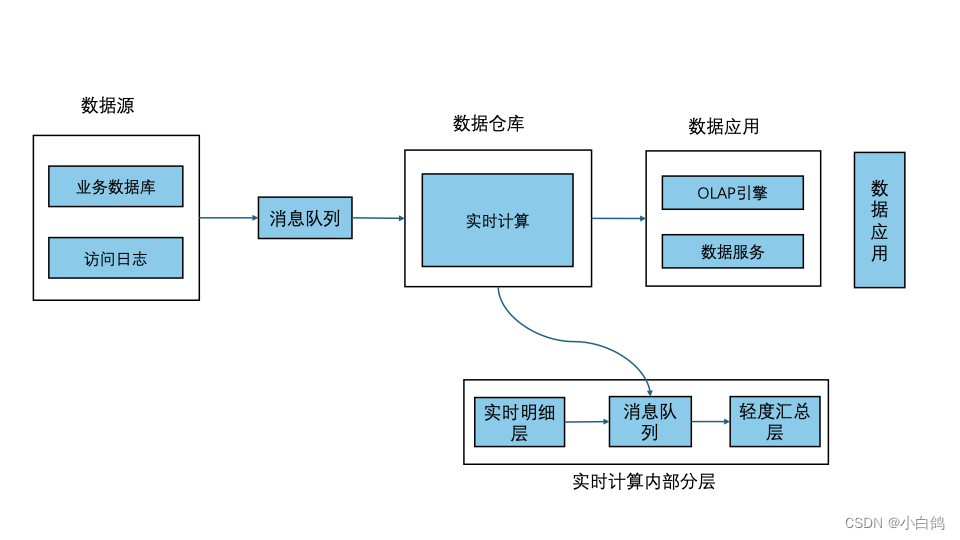
优势:架构简单,避免了维护两套系统还需要保持结果一致的问题,也很好解决了数据订正问题。
劣势:在 Kappa 架构中,需求修改或历史数据重新处理都通过上游重放完成。Kappa 架构最大的问题是流式重新处理历史的吞吐能力会低于批处理。消息中间件缓存的数据量和回溯数据有性能瓶颈。
4)数据湖架构
一种存算分离为主的统一存储(数据湖格式满足ACID)、多样化计算引擎的数据分析架构,它将实时数据的明细、中间、结果写入同一存储,供多样化计算引擎实时查询和访问。
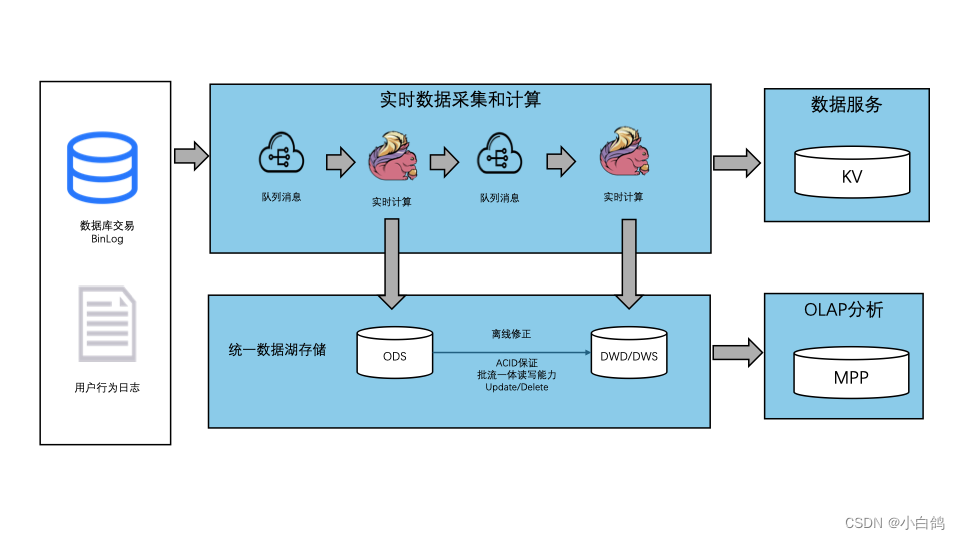
优势:hudi、 iceberg 本身提供了ACID属性,这些特性可以解决数据回溯成本高,OLAP引擎结合困难的问题。
劣势:采用Copy-on-Wite (COW)会造成写放大,影响写入的性能;采用Merge-on-Read(MOR)会造成读放大,影响实时数据的查询分析性能:而湖格式存储,通常采用COW或者MOR,不可两者兼得,会造成性能不足以满足实施业务需求,通常存在分钟级别或者是小时级别的延迟。
1.2、架构能力对比
技术组件和实效性对比
| 离线大数据 | Lambda架构 | Kappa架构 | 数据湖架构 | |
|---|---|---|---|---|
| 典型技术组合 | 离线:Hadoop+Spark; 调度工具:Azkaban; OLAP引擎:Impala/presto; 数据服务:HBase |
离线:Hadoop+Hive/Spark 流处理; Flink OLAP引擎:ClickHouse; 数据服务:HBase |
流处理:Flink; OLAP引擎:Doris; 数据服务:HBase |
湖格式:Hudi/iceberg/Delta on HDFS; 流处理:Flink; OLAP引擎:Impala/Pretsto; 数据服务:HBase |
| 数据源 | 结构化/半结构化 | 结构化/半结构化 | 结构化/半结构化 | 结构化/半结构化、非结构化 |
| 实时处理技术栈 | 无 | 典型代表:Spark Streaming、Flink | 典型代表:Flink | 典型代表:Flink |
| 实时性 | 小时/分 | 秒/毫秒 | 秒/毫秒 | 小时/分 |
实时数据分析对比
| 离线大数据 | Lambda架构 | Kappa架构 | 数据湖架构 | |
|---|---|---|---|---|
| 实时数据存储 | HDFS,且OLAP&HBase基于HDFS | 离线数据:HDFS; 实时数据:CK+HDFS(HBase底层存储) |
OLAP引擎:Doris | HDFS |
| 实时数据更新能力 | HDFS: Overwrite | HDFS: Overwrite; CK:更新能力不完善; HBase: Upsert |
Doris: Upsert | Hudi/Iceberg/Delta : Upsert |
| 实时查询DWD、DWS中间层结果 | 支持查询 | 中间结果一般不写入OLAP引擎; 写入HDFS,则支持查询 |
中间结果存储Kafka,不支持查询 | 支持查询 |
| 实时性 | 小时/分 | 秒/毫秒 | 秒/毫秒 | 小时/分 |
| OLAP引擎 | Impala/presto查询性能弱,适合联邦查询 | CK适合单表聚合,多表Join能力差 | Doris单表和多表Join查询能力较好 | 湖格式有相关索引能力,查询性能优Impala/Presto on HDFS |
| 数据服务 | 使用HBase,支持高并发,离线实时数据都可查 | 使用HBase,支持高并发,只能查实时数据 | 使用HBase,支持高并发,只能查实时数据 | 使用HBase,支持高并发,离线实时数据都可查 |
| 实时AI分析 | 基于Spark ML/TF/PyTorch离线训练和推理 | 基于Flink ML/TF/PyTorch实时训练和推理 | 基于Flink MLTF/PyTorch实时训练和推理 | 基于Flink MLTF/PyTorch实时训练和推理 |
管理对比
| 离线大数据 | Lambda架构 | Kappa架构 | 数据湖架构 | |
|---|---|---|---|---|
| 运维成本 | 维护一套代码,难度较小 | 维护两套代码,难度较小 | 维护一套代码,难度较小 | 维护一套代码,难度较小 |
| 数据孤岛 | 离线实时数据在同一个存储介质 | 离线实时数据在不同存储介质 | 离线实时数据在同一个存储介质 | 离线实时数据在同一个存储介质 |
| 数据一致性 | 离线、实时数据和指标不一致概率小 | 离线、实时数据和指标不一致概率大 | 离线、实时数据和指标不一致概率小,少量修正 | 离线、实时数据和指标不一致概率小,少量修正 |
1.3、实时数仓
1.3.1 实时数仓定义
遵循数据仓库的建设规范,一种支持事件发生后立即或不久对事件数据进行处理和分析的解决方案,数据实时采集、写入、加工、分析、应用都是连续,提供数据产生到应用的端到端秒级响应能力,以最小的延迟产出数据见解驱动业务行动。
1.3.2 实时数仓特点
1、毫米级延迟
低延迟主要体现三方面:
1)整体链路:端到端毫秒延迟;
2)数仓层级:层级毫秒级延迟;
3)数仓数据:实时写入/更新/可见/可查,数据毫米级延迟。
2、高吞吐写和高QPS度
3、智能化
实时数仓能够做到智能自适应,根据业务数据波峰波谷,自动调用计算资源;统计数据访问频次,自动完成冷热数据切换,兼顾性能、成本、自运维。
4、高可用架构
实时数仓应该具备高可用,通过架构部署或者产品能力实现从集群、负载格力、服务主备等手段,避免单一故障,有应急系统可切换使用,服务不断。
5、高水平数据管理
实时数仓需要建立完善的数据资产管理,包括但不限于源数据管理、数据安全、数据脱敏、数据备份、数据血缘、数据目录等,实现数据可查、能用、可用、好用。
6、支持混合负载
实时数仓期望能多种类型的混合负载一体化支持,不同负载能够做到相互隔离不干扰,即一个引擎支持多种场景,简化架构、保证数据一致性。
1.4、实时数仓典型业务场景
通常来讲,企业构建实时数仓,有以下几大类业务场景和技术需求。
1.4.1六类场景
1)实时描述类:
场景描述:通过数据实时反馈业务正在发生什么,协助管理层第一时间做出业务决策。
教育行业场景-数据看板:采集企业的B段业务数据,包含交易、教学、人员等数据,按照不同的条件和学习层级等,形成营收、教学等实时报表。
核心技术需求:实时预计算分析、离线实时数据关联分析
2)实时运营类
场景描述:通过数据实时诊断业务为什么发生,找到差异性和根因,协助执行层实时决策和实时调控相关策略。
电商行业场景-精准营销:产出实时用户标签数据,然后做人群圈选、用户画像分析、对不同的人群、不同的活动策略做AB测试,实时评估活动效果和差异性,实时调整人群包和营销活动。
核心技术需求:OLAP分析、多维分析、即时分析、标签护具高效分析。
3)实时监控类
场景描述:通过数据实时识别业务正在发生的风险,及时预警供相关人实时干预。
行业场景-链路监控:直播行业的网络异常监控,及时处理较少投诉率。物流行业实时整合多源数据,结合出入库、仓库作业等实时数据协助小二日常物流订单分析、订单派送。
核心技术需求:高QPS的在线数据服务、实时规则引擎、实时复杂时间处理
4)实时预测类
场景描述:通过数据实时预测业务未来可能发生的风险或者行为,提前干预降低风险成本,促进业务规模化增长。
行业场景-实时推荐:在搜索、推荐、广告行业,实时采集用户行为数据,计算实时特征,预测用户点击率/转化率,然后做个性化推荐,提升业务效果。
核心技术需求:实时特征/样本计算、实时AI、高QPS的在线数据服务、向量召回。
5)实时自动决策类
场景描述:通过对市场的实时事件的数据分析,快速响应市场变化,自动完成相关交易和价格调整。
金融行业场景-金融量化投资:基于提前建立的交易模型实现交易执行的自动化,通过对市场数据的实时监控和分析,快速响应市场变化,减少人为干扰和误操作,提高交易效率和准确率。
核心技术需求:实时特征/样本计算、实时AI、高QPS的在线数据服务
6)实时用户增长类
场景描述:通过对用户实时行为数据,在用户拉新、促活、流失、召回环节实时决策,实现日活、月活用户量的增长。
游戏行业场景-游戏发现:基于用户实时行为数据,通过广告只能投放优化买量,提升用户拉新ROI。通过实时个性化推荐,促活。其他等。
核心技术需求:实时特征/标签计算、OLAP分析、高QPS在线数据服务、向量召回、高效的留存/漏斗分析函数。
1.4.2 实时看板/大屏
此类需求在技术上,常需要业务交易数据,设计高层管理人群关注的核心指标,基于实时数据计算毫秒级计算指标值,存储是OLAP引擎中,最终在展示工具设计出数据看板和大屏访问。
1.4.3 实时OLAP分析
此类需求在技术上,需要查询业务总体情况,发现差异,然后基于数据立方体能力,从多维度、多指标对比分析,找到差异原因,反向指导业务的运作。
1.4.4 实时风险监测
该场景下,首先实时采集设备、交易数据、结合交易数据,其次通过实时规则+AI算饭的智能识别,将风险、故障灯行为数据和用户,汇总推到相关人群做后续执行动作,完成风险识别、推送、执行的闭环链路。
1.4.5 实时推荐
实时推荐场景下,首先采集用户行为数据进消息队列,其次基于实时数据计算完成实时特征计算,结合静态(离线)特征一起存储,即用户标签和画像,此时实时推荐的推理服务即可利用实时+离线特征进行物品推荐。更进一步,会结合实时特征+明细行为数据,基于Base离线模型,周期训一个实时模型,然后跟已经上线模型做对比,效果优则上线,此时完成实时推荐AI模型的更新。
二、需求分析
2.1、功能性需求
这些需求通常是可以明确的,可以被度量。主要包含以下几个方面:
1、实时数据采集
1)离线数据同步
2)实时数据同步:基于消息中间件的数据实时入仓;基于CDC数据实时入仓。
2、实时数据计算
3、实时数据存储
4、实时数据分析服务
5、实时数据接口
6、数据资产管理
2.2、非功能性需求
1、可用性
1)服务可用性;2)容灾备份
2、安全性
1)系统安全;2)数据安全;3)网络安全;
3、高性能
1)数据延迟性能;2)数据实时采集性能;3)数据实时计算性能;4)实时数据存储性能;5)分析服务性能
4、成本可控
未完。。。