论文地址
论文地址:
[1805.06413] CASCADE: Contextual Sarcasm Detection in Online Discussion Forums (arxiv.org)CASCADE: Contextual Sarcasm Detection in Online Discussion Forums - ACL Anthology
论文首页

笔记大纲
CASCADE:在线论坛中的语境讽刺检测
📅出版年份:2018
📖出版期刊:
📈影响因子:
🧑文章作者:Hazarika Devamanyu,Poria Soujanya,Gorantla Sruthi,Cambria Erik,Zimmermann Roger,Mihalcea Rada
🔎摘要:
自动讽刺检测方面的文献主要集中在对文本进行词法、句法和语义层面的分析。然而,讽刺句子可以用上下文预设、背景和常识知识来表达。在本文中,我们提出了一种语境讽刺检测器(ContextuAl SarCasm DEtector,简称 CASCADE),它采用了内容和语境驱动建模的混合方法,用于在线社交媒体讨论中的讽刺检测。对于后者,CASCADE 的目的是从讨论主题的话语中提取上下文信息。此外,由于讽刺的性质和表达形式因人而异,CASCADE 利用用户嵌入对用户的风格和个性特征进行编码。当与卷积神经网络等基于内容的特征提取器一起使用时,我们发现在大型 Reddit 语料库中的分类性能得到了显著提升。
🌐研究目的:
主要研究检测在线论坛中的讽刺语言
📰研究背景:
当句子中出现这些词汇线索时,讽刺检测就能达到很高的准确率。然而,讽刺也可以隐晦地表达,即不存在此类词汇线索。这种讽刺的使用也依赖于语境,其中涉及对事件的常识和背景知识的推测。
🔬研究方法:
提出了CASCADE的混合网络,它同时利用了讽刺检测所需的内容和上下文。
它通过两种方式处理上下文信息。首先,它对用户进行分析,创建用户嵌入,捕捉讽刺的指示行为特征。它利用用户的历史帖子来模拟他们的写作风格(文体测量)和个性指标,然后使用多视图融合方法(称为典型相关分析法(CCA))将其融合为全面的用户嵌入。其次,它还能从论坛中的评论话语中提取上下文信息。这是通过对属于同一论坛的这些合并评论进行文档建模来实现的。
🔩模型架构:

学习情境特征
主要是提取用户嵌入和话语特征,用户嵌入是根据每个用户累积的历史帖子创建的,试图捕捉与其讽刺倾向相关的用户特征;话语特征是从每个讨论区的评论话语中提取上下文信息。
用户嵌入
对用户的风格和个性特征进行建模,然后使用 CCA 对其进行融合,以创建一个单一的表征。
话语特征
将用户的在线评论整合到文档中来学习用户的文体特征,再利用无监督表示学习方法 ,为每个用户生成一个固定大小的向量。这里的关键思路是使用相关文档的文档向量作为上下文词的一部分。
个性特征
我们在用户嵌入中加入了个性特征。对于用户,首先遍历提前撰写好的所有评论,将每条评论作为输入提供给预先训练好的 CNN,该 CNN 是根据多标签个性检测任务训练的。训练完成后,CNN 模型将用于推断每条评论中的人格特质。具体方法是提取 CNN 最后一个隐藏层向量的激活量(个性向量)
CNN:
每个单词 wi 使用预先训练好的 FastText 嵌入表示为单词嵌入⃗。首先,应用一个卷积层,其中有三个滤波器 F[1,2,3],高度分别为 h[1,2,3]。对于每个 k ∈ {1, 2, 3},过滤器 Fk 在 S 上滑动,提取每个实例的 hk-gram 特征。
每个滤波器 Fk 会生成 M 个特征图,总共输出 3M 个特征图。然后,对每个特征图的长度进行最大池化操作。从 Fk 计算出的所有 M 个特征图,输出 o⃗ k。最后,⃗o 被投射到一个由 dp 神经元组成的密集层上,然后是由 5 个表示五种人格特质的类别组成的最后的 sigmoid 预测层(Matthews 等人,2003 年)。
融合
我们采用多视角学习方法,使用 CCA将造型特征和个性特征结合到每个用户的综合嵌入中进行融合。
话语特征
对于所有 Nt 讨论区,我们通过附加其中的评论来组成每个讨论区的文档。与之前一样,我们使用段落向量(ParagraphVector)为每个文档生成话语表征。
最终预测
将提取评论、作者的用户嵌入向量⃗和论坛 的话语特征向量⃗,这三个向量连接起来,形成统一的文本表示。用于提取⃗的CNN 与第 3.4.2 节中描述的用于提取个性特征的 CNN 设计相同。最后将统一的文本被投射到具有两个软最大激活神经元的输出层。这样就得到了评论是否具有讽刺意味的软最大概率。这个概率估计值随后被用来计算分类交叉熵,并将其作为损失函数。
🧪实验:
📏评估指标:
📇 数据集:
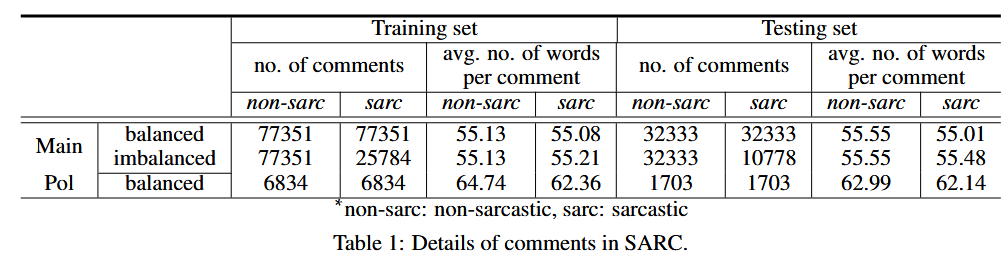
大规模的自注释讽刺语料库 SARC3(Khodak 等人,2017 年)
该数据集包含 Reddit 上超过一百万个讽刺/非讽刺语句实例。Reddit 由特定主题的讨论区(也称为子论坛)组成,每个论坛都有一个帖子标题。在每个论坛中,用户通过对标题帖子或其他人的评论进行交流,从而形成树状对话结构。
值得注意的是,SARC 中的几乎所有评论都由单句组成。我们在实验中考虑了 SARC 数据集的三种变体。
在现实世界中,讽刺性评论通常少于非讽刺性评论,为了模拟这种情况,我们使用了不平衡版本的 Main 数据集。具体来说,我们将训练/测试集中讽刺性评论和非讽刺性评论的比例保持在 20 ∶ 80(大约)
10% 的验证数据
📉 优化器&超参数:
Adam优化器
每条评论会被限制或填充为 100 个单词
最佳超参数为 {ds, dp, dt, K} = 100, dem = 300, ks = 2, M = 128, α = ReLU。 我们手动分析了不同大小的用户嵌入维度 K(图 3a)和话语特征向量大小 dt(图 3b)对验证性能的影响。
📊 消融实验:
我们对 CASCADE 的多个变体进行实验,以分析其架构中存在的各种功能的重要性。
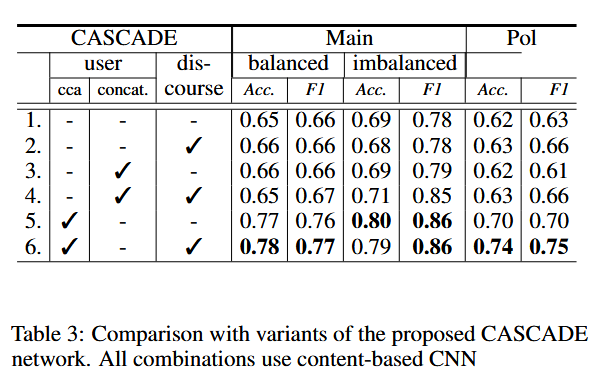
首先,我们仅测试基于内容的 CNN 的性能(第 1 行)。此设置提供最差的相对性能,准确度比最佳设置低近 10%。接下来,我们将上下文特征添加到该网络中。在这里,话语特征的影响主要体现在 Pol 数据集中,F1 增加了 3%(第 2 行)。当引入用户嵌入时(第 5 行),可以观察到性能的显着提升(准确度为 8 - 12%,F1)。
总体而言,由具有用户嵌入和上下文话语特征的 CNN 组成的 CASCADE 在所有三个数据集中提供了最佳性能(第 6 行)。
📋 实验结果:
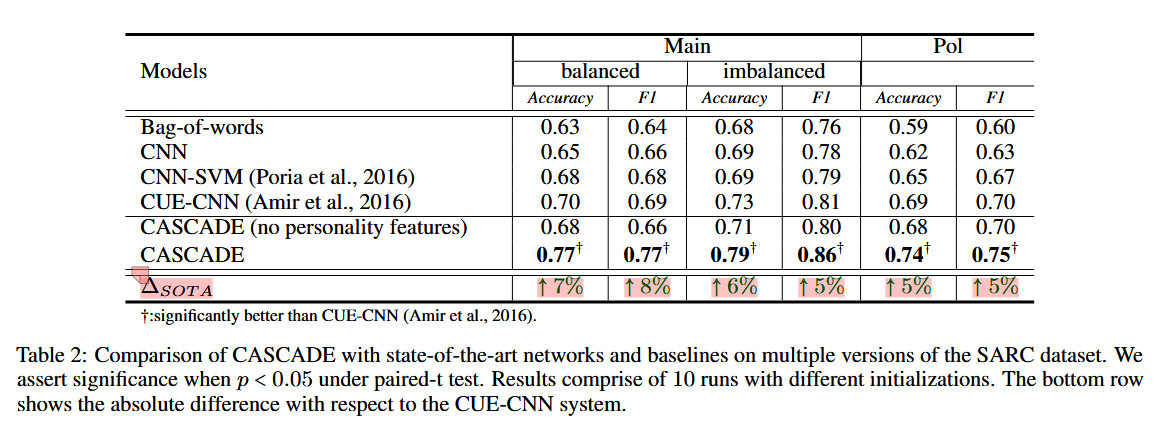
CASCADE 成功地在所有具有统计意义的数据集上实现了重大改进。词袋方法获得的性能最低,而所有神经架构的性能都优于它。
它在主不平衡数据集上的性能改进也反映了它对类别不平衡的鲁棒性,并将其确立为现实世界的可部署网络。
没有个性特征的 CASCADE 性能下降到与 CUE-CNN 类似的范围。这表明风格和个性特征的结合对于 CASCADE 性能的提高确实至关重要。
🚩研究结论:
在本文中,我们介绍了 CASCADE--一种上下文讽刺检测器,它利用内容和上下文信息进行分类。对于上下文细节,我们通过讨论主题中的评论进行用户分析和话语建模。当这些信息与基于 CNN 的文本模型联合使用时,我们在大规模 Reddit 语料库中获得了最先进的性能。
📝总结
💡创新点:
采用了内容和语境驱动建模的混合方法
使用多视图融合方法(称为典型相关分析法(CCA))将其融合为全面的用户嵌入
利用用户嵌入对用户的风格和个性特征进行编码
我们还学习了话语特征,话语特征是从每个讨论区的评论话语中提取上下文信息
对属于同一论坛的这些合并评论进行文档建模
⚠局限性:
然而,有时由于缺乏必要的常识和有关讨论主题的背景知识,从以前的评论中获得的上下文线索不够充分,因此会出现分类错误。
对长篇幅评论的分类还是不足
对历史帖子较少的用户进行错误分类也很常见
🔧改进方法:
通过社区嵌入(Cavallari et al.)
🖍️知识补充:
自动讽刺检测是一个相对较新的研究领域。以往的研究可分为两大类:基于内容的讽刺检测模型和基于上下文的讽刺检测模型。