论文:《Recent Advances in 3D Gaussian Splatting》
作者:Tong Wu, Yu-Jie Yuan, Ling-Xiao Zhang, Jie Yang 等
链接:https://arxiv.org/abs/2403.11134
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
三维Gaussian Splatting(3DGS)的出现,大大加快了新视图合成的渲染速度。与神经辐射场(NeRF)等神经隐式表示表示具有位置和视点条件神经网络的三维场景不同,3DGS利用一组高斯椭球来建模场景,从而通过将高斯椭球栅格化成图像来实现有效的渲染。除了快速的渲染速度外,3DGS的显式表示促进了下游任务,如动态重建、几何编辑和物理模拟。本文对近年来的3DGS 方法进行了文献综述,大致可分为三维重建、三维编辑等下游应用。
一、三维重建
1.1 质量增强
尽管3DGS能够产生高质量的重建结果,但其渲染仍有改进空间。例如, Mip-Splatting 观察到改变采样率,例如焦距,可能会引入高频高斯形状样式的伪影或强烈的膨胀效果,从而极大地影响渲染图像的质量。为了消除高频高斯形状样式的伪影,Mip-Splatting将3D表示的频率限制在训练图像确定的最大采样频率的一半以下。此外,为了避免膨胀效果,它还引入了另一个二维Mip滤波器,将投影的高斯椭球体近似为类似于EWA-Splatting的箱式滤波器。
MS3DGS也旨在解决原始3DGS中的混叠问题,并引入了多尺度高斯splats表示,在以新的分辨率级别渲染场景时,它从不同尺度级别选择高斯以产生无混叠的图像。
除了混叠问题,还需要改进渲染视角相关效果的能力。为了产生更加真实的视角相关效果,VDGS 使用类似于NeRF的神经网络来表示3D形状,并预测视角相关颜色和不透明度等属性,而不是原始3DGS中的球谐函数(SH)系数。Scaffold-GS提出了初始化体素网格,并将可学习特征附加到每个体素点上,高斯的所有属性都由插值特征和轻量级神经网络确定。
StopThePop指出,3DGS倾向于通过弹出;3DGS来欺骗视角相关效果,由于每个射线的深度排序,这导致当视点旋转时结果不够真实。。为了减轻弹出3DGS的潜在问题,StopThePop将每个射线的深度排序替换为基于tile的排序,以确保在局部区域内一致的排序顺序。为了更好地指导3DGS渲染,GaussianPro引入了一种渐进传播策略,通过考虑相邻视图之间的法线一致性并添加平面约束来更新高斯函数。为了处理更复杂的光照效果,如镜面反射和各向异性成分,Spec-Gaussian提出利用各向异性球形高斯来近似3D场景的外观。
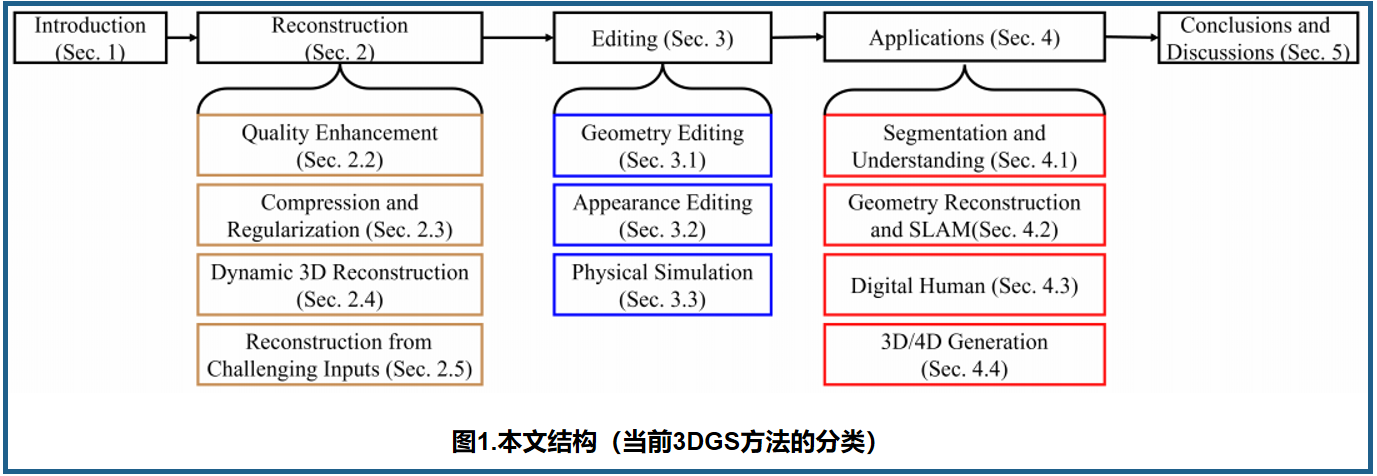
不同重建方法的定量结果:
1.2 压缩与正则化
尽管3DGS实现了实时渲染,但在降低计算要求和改善点分布方面仍有改进空间。一些方法专注于改变原始表示以减少计算资源。其中,矢量量化是信号处理中的传统压缩方法,涉及将多维数据聚类到有限的表示集中,主要用于高斯函数中。
具体来说,C3DGS采用残差矢量量化(R-VQ)来表示几何属性,包括缩放和旋转。而SASCGS则利用矢量聚类将颜色和几何属性编码到两个码本中,采用了感知敏感的K均值方法EAGLES则将所有属性量化,包括颜色、位置、不透明度、旋转和缩放。相反,Compact3D则不量化不透明度和位置,因为共享它们会导致高斯重叠。在数据存储方面,LightGaussian采用基于八叉树的无损压缩来处理位置属性。而SOGS则采用了一种与矢量量化不同的方法,将高斯属性排列成多个2D网格,对这些网格进行排序,并应用平滑度正则化来惩罚在2D网格上与其局部邻域值非常不同的所有像素。对于磁盘数据存储,SASCGS利用DEFLATE熵编码方法来压缩数据,而SOGS则将RGB网格压缩为JPEG XL格式,并将所有其他属性存储为带有zip压缩的32位OpenEXR图像。
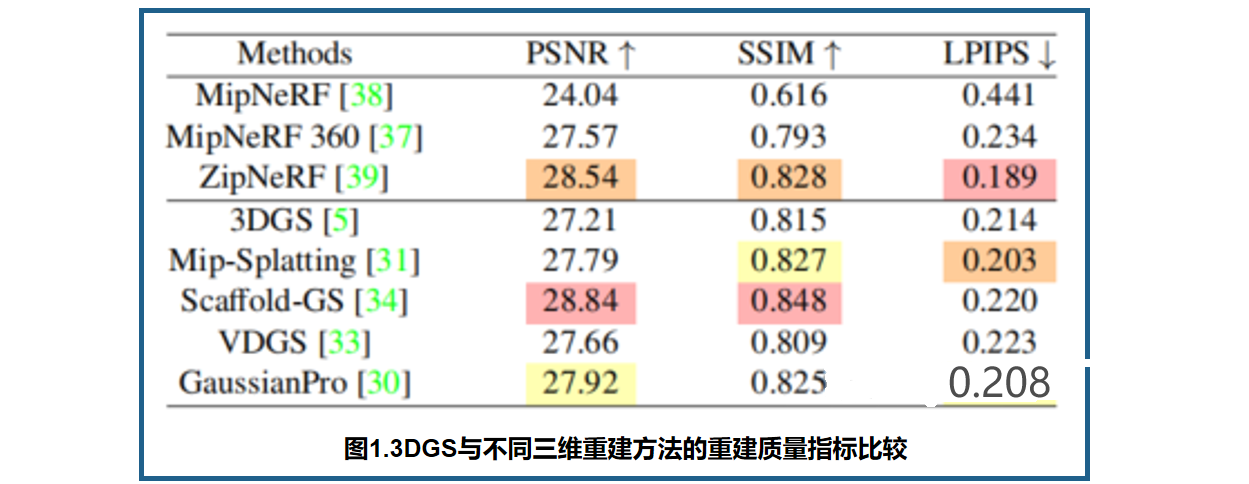
图2中展示量化重建结果和压缩后3D场景的大小:
1.3 动态三维重建
与NeRF表示相同,3DGS也可以扩展到重建动态场景。动态3DGS斑点渲染的核心在于如何模拟高斯属性值随时间变化的变化。最直接的方法是在不同的时间步长中为3DGS分配不同的属性值。Luiten等人将3DGS的中心和旋转(四元数)视为随时间变化的变量,而其他属性在所有时间步长上保持不变,从而通过重建动态场景实现6自由度跟踪。然而,逐帧离散定义缺乏连续性,可能导致长期跟踪结果不佳。因此,引入了基于物理的约束,包括短期局部刚性和局部旋转相似性损失以及长期局部等距损失。然而,该方法仍然缺乏帧间相关性,并且对于长期序列需要高存储开销。
因此,将空间和时间信息分解 并分别用规范空间和变形场建模已成为另一种探索方向。规范空间是静态的3DGS斑点渲染,然后问题就变成了如何建模变形场。一种方法是使用MLP网络来隐式拟合它,类似于动态NeRF。杨等人 提出动态GS,提出将位置编码高斯位置和时间步长 t t t 输入MLP,输出高斯的位置、旋转和缩放的偏移量。然而,不准确的姿态可能会影响渲染质量。这在连续建模NeRF中不是很明显,但是离散的3DGS斑点渲染可能会放大这个问题,尤其是在时间插值任务中。因此,他们在编码的时间向量中添加了一个线性衰减的高斯噪声,以提高时间平滑度,而无需额外的计算开销。
GauFRe 对缩放和旋转进行了指数化和归一化操作,然后添加了MLP预测的增量值,以确保便捷和合理的优化。由于动态场景包含大量的静态部分,它将点云随机初始化为动态点云和静态点云,然后分别进行优化,并将它们一起渲染,以实现动态部分和静态部分的解耦。
与NeRF不同,3DGS渲染是显式表示,而隐式变形建模需要大量的参数,可能会产生过拟合。以下是一些显式变形建模方法,以确保快速训练。
Katsumata等人建议使用傅立叶级数来拟合高斯位置的变化,灵感来自于人类和关节对象的运动有时是周期性的事实。旋转由线性函数近似。其他属性随时间保持不变。因此,动态优化是优化傅立叶级数和线性函数的参数,参数数量与时间无关。这些参数化函数是关于时间的连续函数,确保了时间上的连续性,从而确保了新视图合成的鲁棒性。除了图像损失外,还引入了双向光流损失。多项式拟合和傅里叶近似在建模平滑运动和激烈运动方面具有优势。因此,Gaussian-Flow在时间和频率域中将这两种方法结合起来,以捕获属性的时间相关残差,称为双域变形模型(DDDM)。位置、旋转和颜色被认为随时间改变。为了防止由均匀时间分割引起的优化问题,该工作采用自适应时间步长缩放。最后,优化在静态优化和动态优化之间迭代,并引入了时间平滑损失和KNN刚性损失。
Li等人 引入了时间径向基函数来表示时间不透明度,它可以有效地模拟出现或消失的场景内容。然后,利用多项式函数来模拟3DGS的运动和旋转。他们还使用特征代替球谐函数来表示与视图和时间相关的颜色。这些特征包括三个部分:基色、与视图相关的特征和与时间相关的特征。后两者通过添加到基色的MLP来转换为残差颜色,从而得到最终的颜色。在优化过程中,根据训练误差和粗深度,在未优化的位置上对新的3DGS进行采样。上述方法中使用的显式建模方法都基于常用函数。
DynMF 假设每个动态场景由有限的固定数量的运动轨迹组成,并认为学习到的轨迹 basis将更平滑且更具表现力。场景中的所有运动轨迹都可以通过学习到的基和一个小型时间MLP进行线性表示。位置和旋转随时间变化,两者都使用不同运动基础的运动系数。在优化过程中,介绍了运动系数的正则化、稀疏性和局部刚性项。还有一些其他探索方式。
4DGS(3DGS加上时间维度 t t t)将场景的时空视为整体,并将3DGS转换为4D高斯,即将定义在高斯上的属性值转换为4D空间。例如,缩放矩阵是对角的,因此在对角线上添加时间维度的缩放因子形成4D空间中的缩放矩阵。球谐函数的4D扩展可以表示为与1D基函数的组合。SWAGS 根据运动量的大小将动态序列划分为不同的窗口,并在不同的窗口中训练单独的动态3DGS模型,具有不同的规范空间和变形场。变形场使用可调节的MLP,更侧重于对场景的动态部分进行建模。最后,通过重叠帧添加约束确保了窗口之间的时间一致性。MLP固定,只有规范表示在微调过程中进行优化。这些动态建模方法可以进一步应用于医学领域,例如用于婴儿和新生儿运动分析的无标记运动重建,引入额外的掩模和深度监督,以及单眼内窥镜重建。
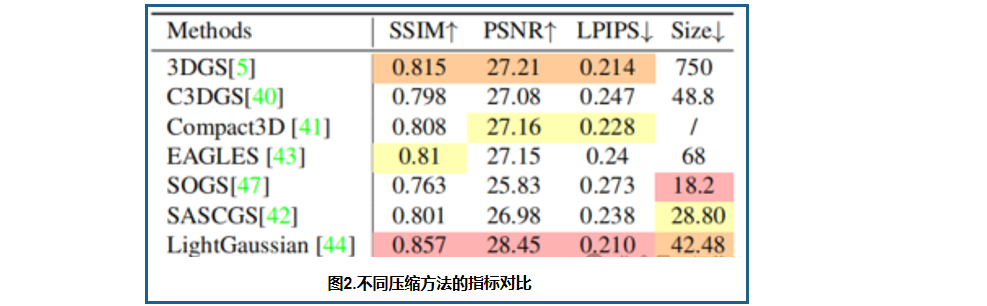
图3展示了代表性的NeRF和3DGS斑点渲染方法的定量动态重建结果。
1.4 挑战性的输入
挑战性的输入,如稀疏视图输入、没有摄像机参数的数据,以及更大的场景,如城市街道。FSGS 是第一个探索从稀疏视图输入重建三维场景的人。它从结构运动(SfM)方法初始化稀疏高斯,并通过unpooling现有的高斯来识别它们。为了实现忠实的几何重建,一个额外的预训练的二维深度估计网络帮助监督渲染的深度图像。SparseGS、CoherentGS, 和DNGaussian也通过引入预训练的二维网络估计的深度输入来从稀疏视图输入进行三维重建。它进一步删除了具有不正确深度值的高斯分布,并利用分数蒸馏采样(SDS)损失[97]来鼓励来自新视角的渲染结果更加忠实。GaussainObject[98]用visual hull初始化高斯,并微调预训练的ControlNet修复,修复退化的(通过向高斯属性添加噪声生成的)渲染图像,这优于以前基于NeRF 的稀疏视图重建方法,如图6所示。

pixelSplat 从没有任何数据先验的单视图输入重建3D场景。它提取类似于PixelNeRF [101]的像素对齐图像特征,并利用神经网络预测每个高斯分布的属性。MVSplat [102]将代价体表示带到稀疏视图重构中,作为高斯分布属性预测网络的输入。 SplatterImage[103]也适用于单视图数据,利用U-Net 网络将输入图像转换为高斯的属性。它可以通过扭曲操作将从不同视点的预测高斯数据聚合,扩展到多视图输入。
对于城市场景数据 ,PVG [107]使高斯均值和不透明度值与时间相关的函数集中在相应的高斯峰值(随时间变化的最大突出度)。DrivingGaussian[108]和HUGS [109]首先对动态驱动数据进行增量优化,然后与动态对象的三维高斯数据组合。这个过程也由SAM[110]和输入激光雷达深度数据辅助。StreetGaussians[111]用动态3DGS建模静态3DGS和动态对象,其中高斯被跟踪的车辆姿态变换,它们的外观与时间相关的球谐波(SH)系数近似。SGD [112]将扩散先验与街景重建相结合,以改进类似于ReconFusion 的新视图合成结果。HGS-Mapping[114]分别建模无纹理的天空、地面平面和其他对象,以获得更忠实的重建。VastGaussian[115]根据地面上投影的摄像机分布将一个大场景划分为多个区域,并根据可见性标准在训练中迭代添加更多的视点来学习重建场景。此外,它还为每个视图使用一个可优化的外观嵌入来为外观变化建模。CityGaussian[116]还采用分治策略对大规模场景进行建模,并进一步引入了基于摄像机与高斯图像之间距离的水平细节渲染。为了便于比较3DGS方法的城市场景,GauU-Scene [117]提供了一个覆盖超过1.5km2 的大规模数据集。
除上述工作外,其他方法还关注特殊的输入数据,包括无相机图像、模糊输入、非约束图像、镜像输入、CT扫描、全景图像和卫星图像。
二、基于3DGS的3D编辑
基于3DGS的3D编辑,这在AR、VR、游戏领域十分重要。
2.1 几何编辑
在几何方面,GaussianEditor 使用文本提示和从提出的高斯语义追踪中获取的语义信息来控制 splats 渲染,从而实现了 3D 修复、对象移除和组合。Gaussian Grouping 同时在 SAM 的 2D 掩模预测和 3D 空间一致性约束的监督下重建和分割开放世界 3D 对象,进一步实现了包括 3D 对象移除、补白和组合在内的多样化编辑应用,并具有高质量的视觉效果和时间效率。
Point’n Move 结合了交互式场景对象操作和暴露区域修复。由于 3D 高斯的显式表示,提出了双阶段的自提示掩模传播过程(dual-stage self-prompting mask propagation process),将给定的 2D 提示点转换为 3D mask 分割,从而实现了用户友好的编辑体验,并获得了高质量的效果。虽然以上方法实现了对 3D 高斯斑点渲染的编辑,但仍然局限于一些简单的编辑操作(移除、旋转和平移)用于 3D 对象。
SuGaR 通过规范化表面上的高斯来从 3DGS渲染中提取显式网格。此外,它依赖于基于变形网格的高斯参数的手动调整,以实现所需的几何编辑,但在大规模变形方面存在困难。SC-GS 学习一组稀疏的控制点来描述 3D 场景的动态,但在面对剧烈运动和详细表面变形时面临挑战。GaMeS 引入了一种新的基于 GS 的模型,结合了传统网格和基本的 GS。
显式网格被用作输入,并使用顶点参数化高斯组件,可以通过在推理过程中更改网格组件来实时修改高斯。然而,它无法处理显著的变形或更改,特别是大面积的变形,因为它无法在训练期间改变网格拓扑。虽然以上方法可以完成一些简单的刚性变换和非刚性变形,但它们在编辑效果和大规模变形方面仍面临挑战。
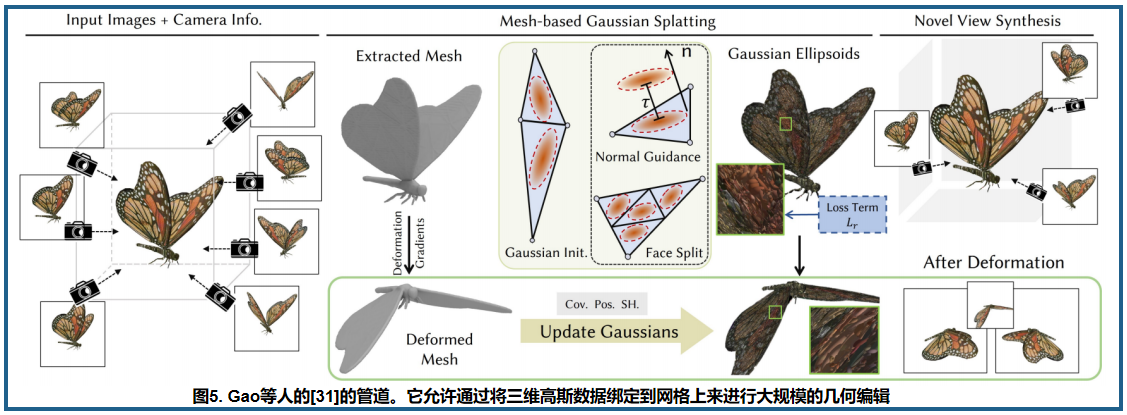
正如 Gao 等人 在图5中所示,他们也利用了显式表示的先验信息(网格的表面属性,如法线,以及显式变形方法产生的梯度),通过学习面的分割来优化参数和高斯的数量,从而将基于网格的变形适应到 3D 高斯斑点渲染中,为 3D GS渲染提供了足够的拓扑信息,提高了两者的质量。
2.2 表面编辑
在表面编辑方面,GaussianEditor 提出首先使用扩散模型在最近的 2D 分割模型生成的掩模区域中,根据语言输入修改 2D 图像,然后再次更新高斯的属性,类似于之前的 NeRF 编辑工作 Instruct-NeRF2NeRF。另一个独立的研究工作,也称为 GaussianEditor,操作方式类似,但它进一步引入了分层高斯斑点渲染 (HGS),以实现类似于对象补白的 3D 编辑。
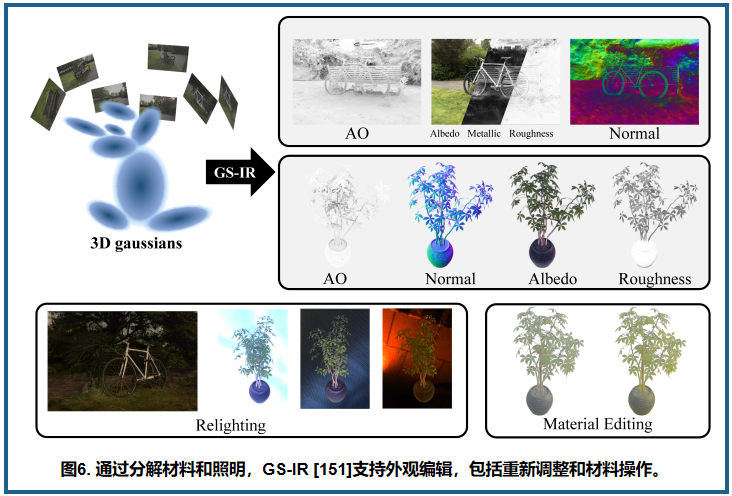
为了更方便地控制纹理和光照,研究人员开始将纹理和光照进行解耦,以实现独立编辑。如图 6 所示,GS-IR 和 RelightableGaussian 分别对纹理和光照进行建模。额外的材料参数被定义在每个高斯上,以表示纹理,而光照则由可学习的环境映射来近似。GIR 和 GaussianShader 通过将材料参数绑定到 3D 高斯上,共享相同的解耦范例,但为了处理更具挑战性的反射场景,它们给高斯添加了与 Ref-NeRF 相似的法线方向约束。在纹理和光照解耦之后,这些方法可以独立修改纹理或光照,而不影响其他方面。
2.3 基于物理信息的编辑
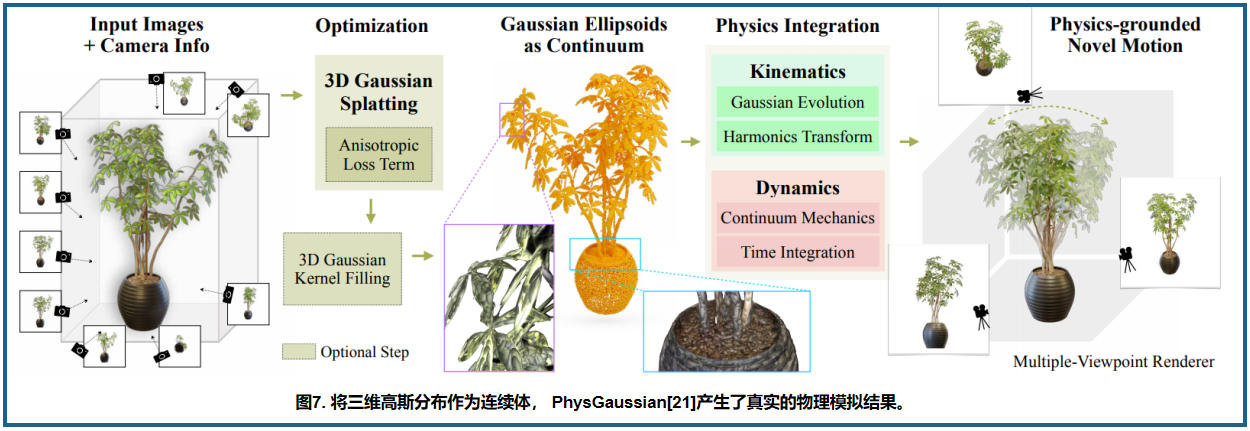
在基于物理的 3DGS 编辑方面,如图7所示,PhysGaussian 使用来自 3DGS 的离散粒子云进行基于物理的动态和通过高斯核的连续变形进行照片逼真渲染。Gaussian Splashing 结合了 3DGS 和基于位置的动力学 (PBD) 来协同管理渲染、视图合成和固体/流体动力学。与 Gaussian shaders 类似,法线被应用于每个高斯核,以将其方向与表面法线对齐并改进 PBD 仿真,还允许基于物理的渲染增强流体上的动态表面反射。VR-GS 是一种基于物理动力学感知的交互式高斯斑点系统,用于虚拟现实,解决了实时编辑高保真度虚拟内容的难题。VR-GS 利用 3DGS 缩小了生成和手工制作的 3D 内容之间的质量差距。通过利用基于物理的动态效果,增强沉浸感,并提供精确的交互和操作可控性。
三、3DGS在CV领域的前沿应用
3.1 SLAM方向
SLAM领域大部分的研究还是用基于NeRF的神经隐式SLAM的思路进行的,所以取得的效果并没有十分SOTA,只是将3DGS替换了NeRF,是一种比较生硬的松耦合。
GS-SLAM 提出了一种自适应的 3D 高斯扩展策略,通过捕获的深度和渲染的不透明度值将新的 3D 高斯添加到训练阶段,并删除不可靠的高斯。为了避免重复的密集化,SplaTAM 使用视角无关的颜色来表示高斯,并创建了一个密集化遮罩。该遮罩通过考虑当前高斯和新帧的捕获深度来确定新帧中的像素是否需要密集化。
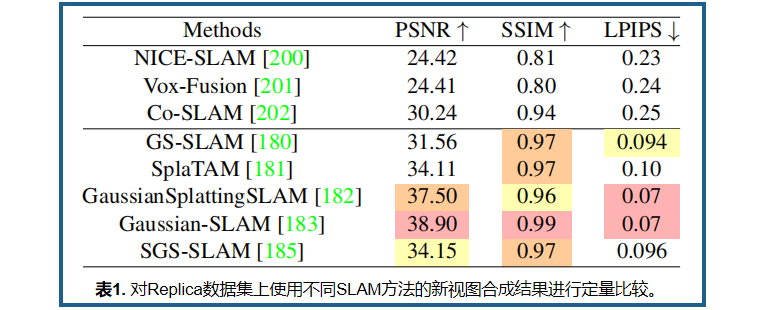
为了稳定定位和地图构建,GaussianSplattingSLAM 和 Gaussian-SLAM 在高斯的尺度上额外添加了一个尺度正则化损失,以鼓励各向同性的高斯。为了更容易地初始化,LIV-GaussMap 使用 LiDAR 点云初始化高斯,并为全局地图构建一个可优化的尺寸自适应体素网格。SGS-SLAM 在同时定位和映射过程中进一步考虑了高斯的语义信息。它通过提炼 2D 语义信息来实现,该信息可以使用 2D 分割方法获取,或者由数据集提供。我们在表4中报告了不同 SLAM 方法在重建任务中的定量结果。
表1展示了基于 3DGS 的 SLAM 和基于 NeRF 的 SLAM 的指标对比。从重建结果上看,3DGS 比 NeRF 表现更出色:
3.2 虚拟人体重建方向
在AR和VR领域,如何重建一个逼真的虚拟人体一直都是一个难题,因为人体是非刚性物体,有柔软的皮肤,宽松的衣物,飘逸的长发,帅气的脸庞,不管是纹理细节,还是五官面部的表达,单独拎出来一个都是一个大课题,而3DGS在这个领域则是打破了以往方法的限制,能够对人体进行较为逼真的重建。由于头部(五官,表情,头发)和身体(衣物,动作,关节骨架)的重建各自有各自的难点,因此研究都是将这两个部分分开进行,笔者也按照这个惯例,将这两个部分分开进行介绍。
3.2.1 头部重建
针对使用3DGS进行人头建模,MonoGaussianAvatar首先应用3DGS进行动态头部重建,使用规范空间建模和变形预测。此外,PSAvatar引入了显式Flame面部模型来初始化高斯,可以捕捉高保真的面部几何形状,甚至是复杂的体积对象(例如眼镜)。GaussianHead利用三平面表示和运动场来模拟连续运动中几何变化的头部,并渲染丰富的纹理,包括皮肤和头发。为了更容易地控制头部表情,GaussianAvatars将几何先验(Flame参数化面部模型)引入到3DGS中,将高斯绑定到显式网格上,并优化高斯椭圆体的参数。
Rig3DGS采用可学习的变形来为新颖的表情、头部姿势和观察方向提供稳定性和泛化性,从而在便携设备上实现可控的肖像。HeadGas将3DGS赋予一组基于潜在特征的基础,这些特征由3DMMs的表情向量加权,实现了实时可动头部重建。
FlashAvatar进一步将均匀的3DGS场嵌入到参数化面部模型中,并学习额外的空间偏移来捕捉面部细节,成功将渲染速度推到300 FPS。为了合成高分辨率结果,Gaussian Head Avatar采用超分辨网络实现高保真头像学习。
GaussianHair首次将Marschner头发模型与UE4的实时头发渲染相结合,创建了高斯头发散射模型。它捕捉了复杂的头发几何和外观,以实现快速光栅化和体积渲染,从而实现了包括编辑和重新照明在内的应用。
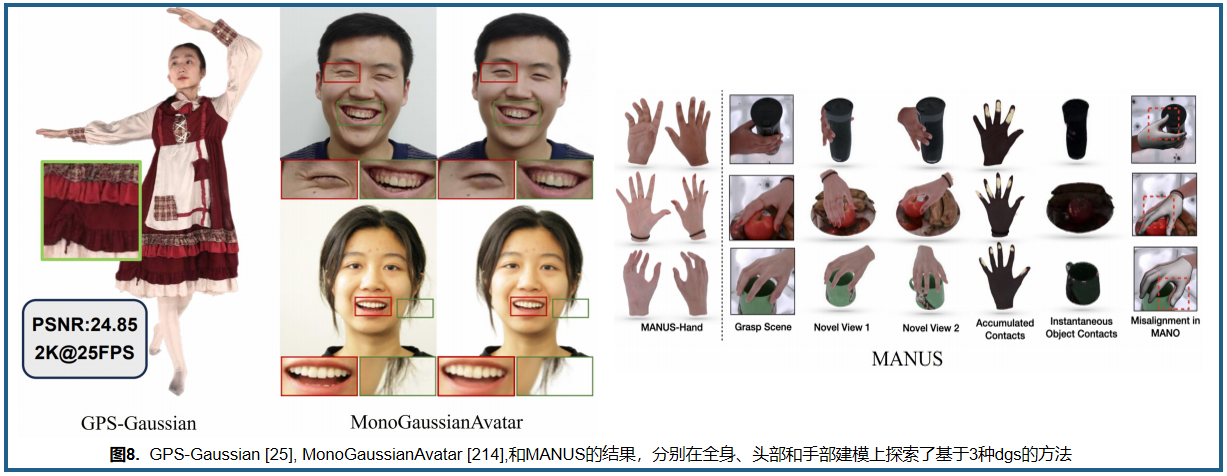
3.2.2 身体重建
在CVPR2024中,就有两项关于3DGS虚拟人体身体重建的工作,可见这部分的研究十分受到国际重视。在全身建模方面,研究旨在从多视角视频中重建动态人体。
D3GA首先使用可驾驶的3DGS和四面体笼创建可动态调整的人体化身,实现了有前景的几何和外观建模。为了捕捉更多的动态细节,SplatArmor利用两个不同的MLP基于SMPL和规范空间来预测大运动,并通过提出的SE(3)场允许姿势依赖性效果,从而实现了更详细的结果。HuGS使用线性混合蒙皮和基于局部学习的精细化方法创建了一个由粗到细的变形模块,用于基于3DGS建模构建和动画化虚拟人体化身。它在20 FPS下实现了最先进的人体神经渲染性能。类似地,HUGS利用三平面表示来分解规范空间,可以在30分钟内从单目视频(50-100帧)中重建人物和场景。
由于3DGS学习了大量的高斯椭球体,HiFi4G将3DGS与其双图形机制提供的非刚性跟踪相结合,用于高保真度渲染,成功地以更紧凑的方式保留了时空一致性。为了在消费级设备上实现更高分辨率的更快渲染速度,GPS-Gaussian在稀疏的源视图上引入了高斯参数映射,与深度估计模块一起联合回归高斯参数,无需任何微调或优化。除此之外,GART基于3DGS表示将人类扩展到更多关节模型(例如动物)。为了充分利用来自多视角图像的信息,Animatable Gaussians将3DGS和2D CNN结合起来,使用模板引导参数化和姿势投影机制实现更准确的人类外观和逼真的服装动态。
Gaussian Shell Maps (GSMs)结合了基于CNN的生成器和3DGS,以重新创建具有复杂细节的虚拟人类,例如服装和配饰。ASH通过将3DGS学习投影到2D纹理空间,使用网格UV参数化来捕捉外观,实现了实时和高质量的动画人体。此外,为了重建人体的丰富细节,如服装,3DGS-Avatar引入了一个浅层MLP来建模3DGS的颜色,并通过几何先验对变形进行正则化,提供了具有姿势依赖性布料变形的逼真渲染,并有效地推广到新颖的姿势中。针对基于单目视频的动态数字人体建模,GaussianBody进一步利用基于物理的先验对规范空间中的高斯进行规范化,以避免单目视频中动态布料的伪影。
GauHuman重新设计了原始3DGS的修剪/分割/克隆,以实现高效优化,并结合了姿势细化和权重场模块进行细节学习。它实现了分钟级的训练和实时渲染(166 FPS)。GaussianAvatar将可优化的张量与动态外观网络结合起来,更好地捕捉动态,允许实时进行动态角色重建和逼真的新颖动画。图10为虚拟人体重建的pipeline示意。
3.3 3D/4D 生成
利用扩散模型[140],跨模态图像的生成取得了惊人的结果。然而,由于缺乏三维数据,很难直接训练一个大规模的三维生成模型。DreamFusion [97]利用了预先训练的2D扩散模型,提出了分数蒸馏采样(SDS)损失,将2D生成先验提取为3D,而不需要3D数据进行训练,实现了文本到3D的生成。然而,NeRF渲染带来了沉重的渲染开销。每种情况的优化时间需要几个小时,渲染分辨率较低,导致结果质量不佳。虽然一些改进的方法从训练过的NeRF中提取网格表示来进行微调,以提高[241]的质量,但这种方法将进一步增加优化时间。3DGS表示可以渲染具有高FPS和小内存的高分辨率图像,因此在最近的一些3D/4D生成方法中,它取代了NeRF作为3D表示。
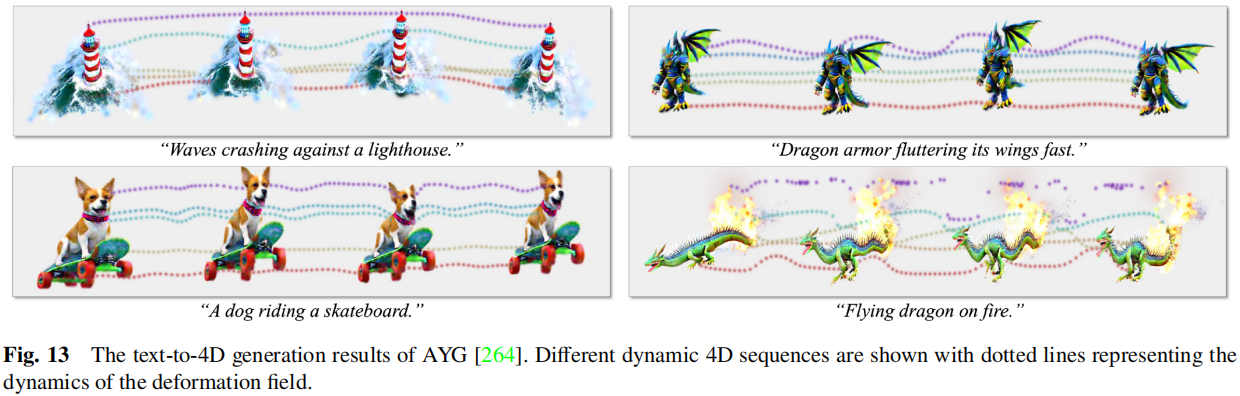
DreamGaussian [20]用3DGS取代了梦融合[97]框架中的MipNeRF [52]表示,它使用SDS损失来优化三维高斯分布。3DGS的分割过程非常适合于生成设置下的优化过程,因此3DGS的效率优势可以引入基于SDS损失的文本到3d生成中。为了提高最终的质量,这项工作遵循了Magic3D [241]的想法,它从生成的3DGS中提取网格,并通过像素级的均方误差(MSE)损失来优化UV纹理来细化纹理细节。除了2D SDS,GSGEN [242]还引入了一个基于Point-E [243]的3D SDS损失,一个文本到点云的扩散模型,以减轻多面或Janus问题。采用点e初始化点云作为初始几何形状进行优化,并仅使用二维图像先验对外观进行细化。DreamGaussian[244]还结合了二维和三维扩散模型的先验。它利用Shap-E [245]生成初始点云,并使用2D SDS优化3DGS。然而,生成的初始点云相对稀疏,因此进一步提出了噪声点增长和颜色扰动来使其密度化。然而,即使引入了三维SDS损失,在优化过程中也可能仍然存在Janus问题,因为视图是逐个采样的。一些方法对二维扩散模型[140]进行微调,同时生成多视图图像,从而在SDS优化过程中实现多视图监督。或者,BoostDream [248]提出的多视图SDS通过拼接4个采样视图的渲染图像,直接创建一个大的2×2图像,并在多视图法线图的条件下计算梯度。这是一种即插即用的方法,首先可以通过渲染监督将3D资产转换为可微表示,包括NeRF、3DGS和DMTet [249],然后对它们进行优化,以提高3D资产的质量。一些方法已经改进了SDS的损失。Luciddreamer[250]提出了间隔分数匹配(ISM),它用DDIM反演取代了SDS中的DDPM,并引入了对扩散过程的间隔步骤的监督,以避免一步重建中的高误差。部分生成结果如图12所示。高斯扩散[251]提出结合从多个角度的结构噪声来缓解Janus问题和变分3DGS,通过缓解飞蚊来获得更好的生成结果。Yang等[252]指出,扩散先验与扩散模型训练过程的差异会影响三维生成的质量,因此他们提出了三维模型和扩散先验的迭代优化。具体来说,在无分类器指导公式中引入了两个额外的可学习参数,一个是可学习的无条件嵌入,另一个是添加到网络中的附加参数,如LoRA [253]参数。这些方法并不局限于3DGS,其他最初基于nerf的方法,包括VSD [254]和CSD [255],旨在提高SDS损失,可以用于3DGS的生成。高斯立方体[256]训练了一个基于高斯立方体表示的三维扩散模型,该模型通过最优传输从常数的高斯数转换为体素化。GVGEN [257]也可以在三维空间中工作,但它是基于三维高斯体积表示的。

四、总结
本文综述了3DGS的最新研究进展,展示了其在三维重建、3D编辑、SLAM、AR和VR等领域的有效应用及其广阔的未来发展前景。值得注意的是,3DGS是在2023年8月发布的新技术。短短不到一年的时间里,它已经对传统计算机视觉方法在各自的应用领域产生了影响。相信3DGS的未来发展会持续颠覆传统的CV行业。
d \sqrt{d} d 1 0.24 \frac {1}{0.24} 0.241 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilon ϵ
ϕ \phi ϕ log a b \log_{a}^{b} logab ▽ \bigtriangledown ▽