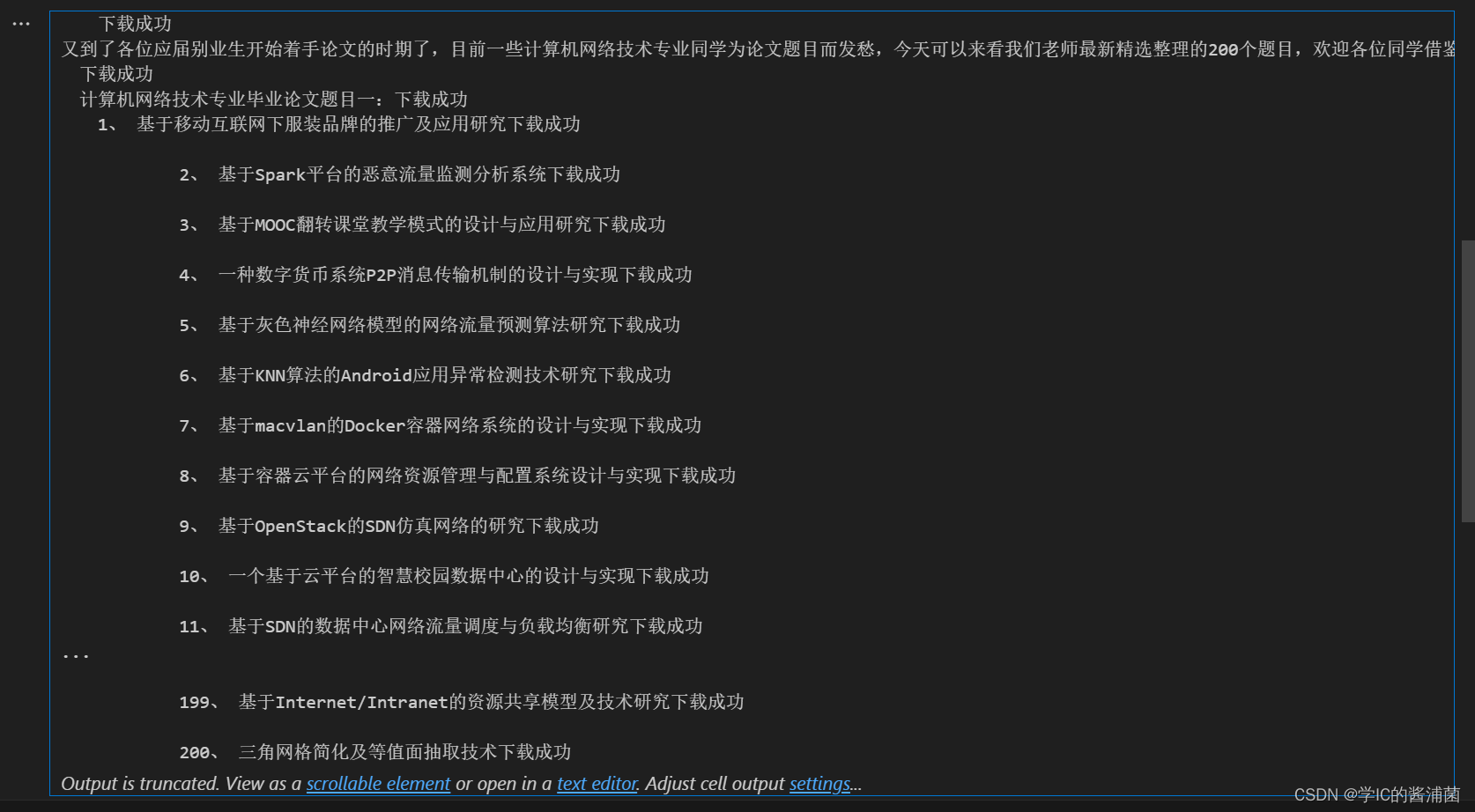
1. 首先,代码定义了一个名为
```
url
```
的变量,它是一个包含三个网址的集合(或者说是一个集合的字典)。这些网址分别是:
- ‘http://www.xueshut.com/lwtimu/127966.html’
- ‘http://www.xueshut.com/lwtimu/127966_2.html’
- ‘http://www.xueshut.com/lwtimu/127966_3.html’
2. 接下来,设置了一个HTTP请求的头部信息,模拟了一个Chrome浏览器的请求。
3. 然后,通过`requests.get()`方法,分别发送GET请求到这三个URL,并将响应内容保存在`response`变量中。
4. 由于网站的编码方式可能不同,这里使用了一些编码转换操作:
- `response.text.encode('iso-8859-1').decode('gbk')`将响应内容从ISO-8859-1编码转换为GBK编码。
5. 创建一个`parsel.Selector`对象,用于解析HTML内容。
6. 从HTML中选择所有满足条件的元素:
- 使用CSS选择器`'p span[style="font-family: 宋体"]'`,找到所有带有`style`属性值为“font-family: 宋体”的`<span>`元素。
- 使用XPath表达式`.//text()`,提取这些`<span>`元素内的文本内容。
7. 遍历每个提取到的文本:
- 打印文本内容,表示下载成功。
- 将文本内容追加到名为’pc_biye.text’的文件中(以UTF-8编码保存)。
8. 最后,完成了对这三个网址的文本下载操作。
完整代码如下:
import requests
import parsel
import os
url = {
'http://www.xueshut.com/lwtimu/127966.html',
'http://www.xueshut.com/lwtimu/127966_2.html',
'http://www.xueshut.com/lwtimu/127966_3.html'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
for url in url:
response = requests.get(url=url, headers=headers)
response_decoded = response.text.encode('iso-8859-1').decode('gbk')
selector = parsel.Selector(response_decoded)
text = selector.css('p span[style="font-family: 宋体"]').xpath('.//text()').extract()
for text in text:
print(f'{text}下载成功')
#print("\n")
with open('pc_biye.text','a',encoding='utf-8') as f:
f.write(text)运行效果如下: