1. 思路分析
首先,在小红书 APP 中点击分享,获取到它的链接分享,如:www.xiaohongshu.com/discovery/i…
然后把它在浏览器中(我用的是 chrome 浏览器)打开。

按 F12 或者 Ctrl + shift + i 打开 开发者工具,切换到 Network 类型,过滤器选择 Img,如图所示,
 刷新一下网页,可以很轻松的提取到我们要的图片的链接。
刷新一下网页,可以很轻松的提取到我们要的图片的链接。
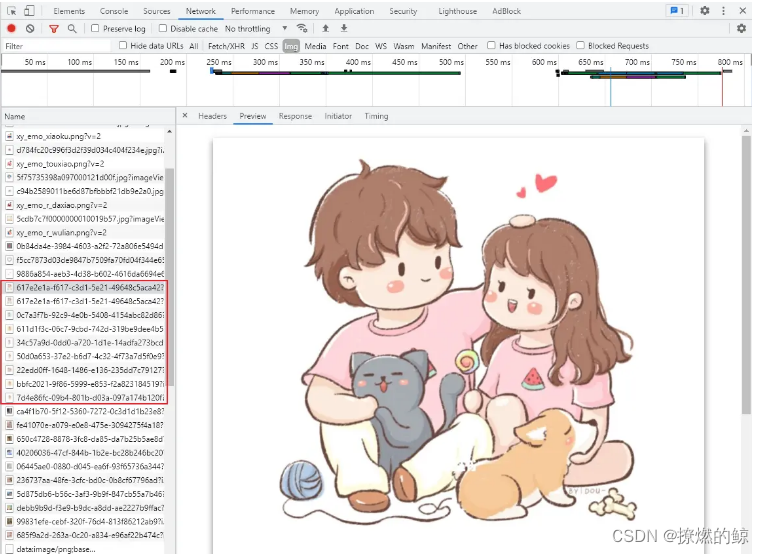
在 Preview 中可以预览图片,在 Headers 中可以查看到图片的 请求头 等信息。
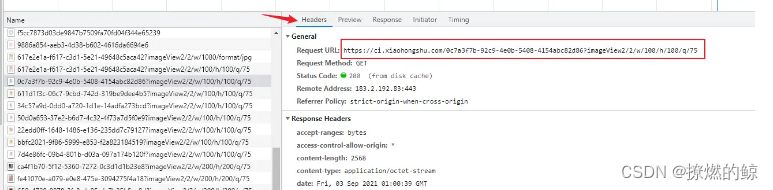
如上图,就可以知道图片的下载链接了。
ci.xiaohongshu.com/0c7a3f7b-92…
简单分析一下,链接由以下几部分组成,域名(https://ci.xiaohongshu.com/) + 图片id(0c7a3f7b-92c9-4e0b-5408-4154abc82d86) + ? + 压缩格式(imageView2/2/w/100/h/100/q/75)。
Tips:浏览器中直接访问
https://ci.xiaohongshu.com/0c7a3f7b-92c9-4e0b-5408-4154abc82d86?imageView2/2/w/100/h/100/q/75会弹出下载界面;而去掉?后面的部分,访问https://ci.xiaohongshu.com/0c7a3f7b-92c9-4e0b-5408-4154abc82d86会在浏览器中打开图片。

通过上面的链接直接下载到的图片,我们发现是有水印的,那无水印的图片怎么去获取呢?
我们继续分析。
我们已经知道了,图片的链接是由 域名 + ID + 压缩格式 组成的,而后面的压缩格式字段只影响图片的尺寸和质量,并不影响有无水印,甚至去掉都没关系(貌似去掉以后获取到的是压缩前的原图)。
所以,无水印的图片,一定是通过 ID 来控制的。而且作为程序员的直觉,这个无水印图片 ID (如果有的话)一定是跟有水印的图片 ID 放一起的。
接下来,我们复制 0c7a3f7b-92c9-4e0b-5408-4154abc82d86(有水印的图片ID) 去网页源码里搜索,看有无收获。
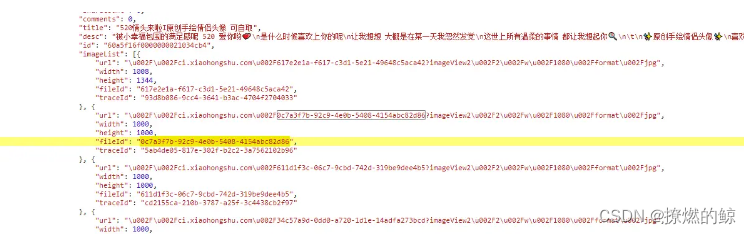
经过一番寻找,终于找到一个地方很可疑,是一个 json 格式的文本,在 imageList 下有很多元素,每一项里都有 url ,宽高,fieldId,traceId 信息。
我们发现,url 就是我们刚才找到的图片链接(里面的 \u002F 是 斜杠 / 的 URL编码),fieldId 就是我们找到的图片的 ID。
这时候,就有一个字段很可疑了,traceId 是什么呢?
抱着试试的心态,我把 url 里的 图片id 换成了 traceId 的值,复制到浏览器中查看一下
ci.xiaohongshu.com/5ab4de05-81…
嘿,您猜怎么着?水印没啦!!哈哈哈哈