接下来是我最想要分享的内容,梳理了YOLOv8预测的整个流程,以及训练的整个流程。
关于YOLOv8的主干网络在YOLOv8网络结构介绍-CSDN博客介绍了,为了更好地介绍本章内容,还是把YOLOv8网络结构图放在这里,方便查看。

1.YOLOv8预测流程原理
前面已经提到了Head层网络是根据类别数来设计生成特定的特征图,那么为什么要将预测box的特征图设计成64个维度?box特征图和预测Cls的特征图又是怎么解码用来预测图片中目标框的位置和类别的?这都是这一节要重点介绍的内容。
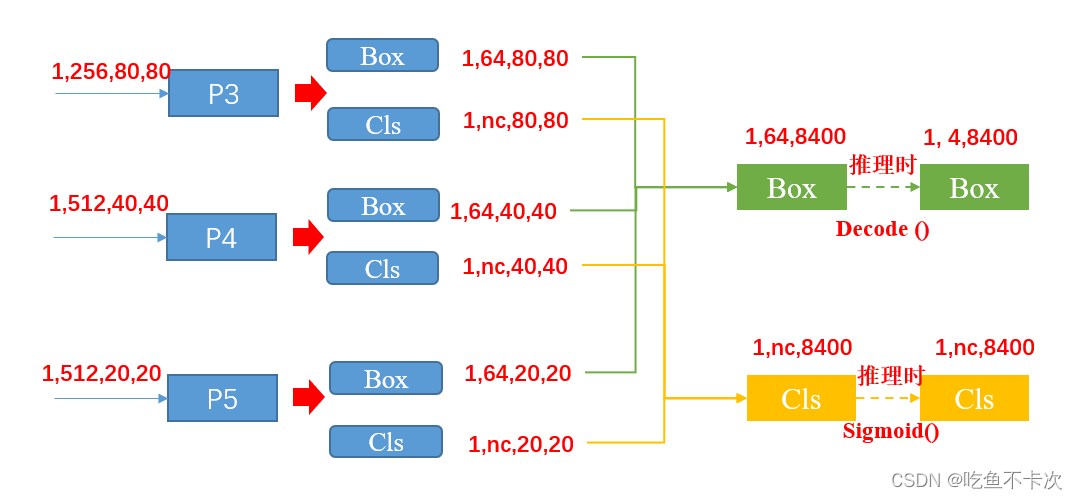
在对box和cls解码之前首先要把三个尺度的特征图展开,box变成(1,64,6400)、(1,64,1600)、(1,64,400),cls变成(1,nc,6400)、(1,nc,1600)、(1,nc,400),然后各自进行合并,从而得到box(1,64,8400),cls(1,nc,8400),一张图片在输入网络后就会得到这两个向量,分别用来预测目标的位置和类别,接下来看一下是如何对这两个向量解码得到预测的结果,并且了解下预测的完整流程。
预测模块分成了以下三个部分,图像预处理、模型推理以及后处理模块。接下来将按照这三个顺序来展开说明。

1.1图像预处理模块
图像预处理模块:对输入的图片进行预处理,包括letterBox、归一化等操作,这里主要介绍一下letterBox操作:(1)LetterBox的目的就是将原图的尺寸(1280,720)转换成网络输入尺寸(640,640);(2)缩放采用的是等比例缩放方式,即找出长边将其缩放成640,然后按照长边的缩放比例(1280/640=2),同时给短边进行缩放,得到720/2=360,然后把短边补充灰边至640;(3)如图所示经过LetterBox后的图片尺寸并不是640*640而是(640,384),这是为什么呢?这种是改进后的LetterBox,只要保证填充短边是32的倍数即可,这样可以加快推理速度。而至于为什么是32的倍数,我理解的是YOLOv8最大进行了5次下采样,为了保证每个像素都有效并且可以整除,那么输入尺寸必须是32的倍数。

1.2推理模块
推理模块:介绍下Box分支和Cls分支是如何进行解码的。
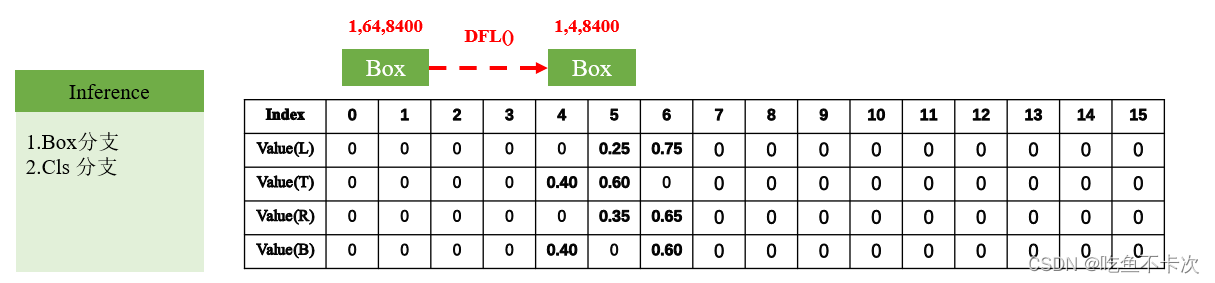
首先来看一下Box分支,由前面可知经过网络后会输出一个(1,64,8400)的向量,64是通过4*reg_max(reg_max=16)计算得到的,4是指预测的中心点到预测边框的左边(l)、上边(t)、右边(r)、下边(b)的距离,reg_max是指预测边框的范围,举个例子就很容易就能理解了。
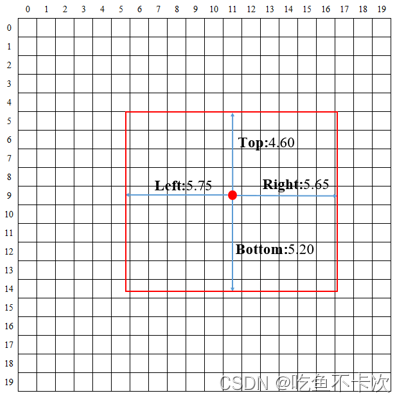
当reg_max=16时,在每个预测特征图下(20*20,40*40,80*80),能够预测的最大预测框的大小为30*30,如何理解30*30呢?如下表所示,4*16可以理解成一个4行16列的矩阵,l/t/r/b的值经过softmax后遵循着规定,并且最终预测的结果为Index和对应的value的乘积,比如网络预测的ltrb长度为:
Left: 5*0.25+6*0.75=5.75 ;Top: 4*0.40+5*0.60=4.60;
Right: 5*0.35+6*0.65=5.65;Bottom: 4*0.4+6*0.6=5.20;
既然如此,那么当Index=15时,value=1,此时预测的l、t、r、b均为最大值,且都为15,也就是说在每个特征图尺度下(20*20,40*40,80*80),能够预测的最大的边框大小均为30*30。比如在20*20尺寸的特征图中,这是专门用来预测大目标尺寸的特征图,而30*30已经超出了特征图20*20的尺寸,说明不会漏掉任何一个大目标。在40*40尺寸的特征图中,30*30能够预测大部分的中等目标(映射回640*640中,目标大小大概为480*480)。在80*80尺寸的特征图中,30*30主要也是用于预测小目标。
最后,会根据缩放比例,把8400个grid cell预测的边框大小映射回640*640尺度,即输入到网络的尺寸上,并且把预测的LTRB表示方式更改为XYWH方式,即中心点/宽高方式。
接着是cls分支,Cls分支仅是对所有元素做一个Sigmoid()操作,也就是说每个元素都会独立地经过Sigmoid()函数,从而得到一个(0,1)区间范围内的值。
1.3后处理模块
后处理模块:主要由两部分组成,分别是NMS模块和Scale_boxes.
NMS模块即非极大值抑制,NMS流程分成了三部分,第一部分主要是通过置信度阈值过滤掉一部分(每个gird cell会有nc个预测类别的值,且经过sigmoid后均在(0,1)之间,取nc个里面的最大值和阈值进行比较),并且将XYWH格式转换为XYXY格式,由此8400个grid cell经过过滤后只剩下29个。第二部分主要通过Cls张量挑出这29个grid cell的类别置信度及其标签下标。第三部分是给box加上一个偏移量通过torchvision自带的NMS来完成标签框的过滤,给不同类别加上一个偏移量是为了在区分不同的类别。最后将得到一个3行6列的矩阵,代表预测出的三个目标及其对应的XYXY格式的Box,类别的置信度,以及类别的下标。
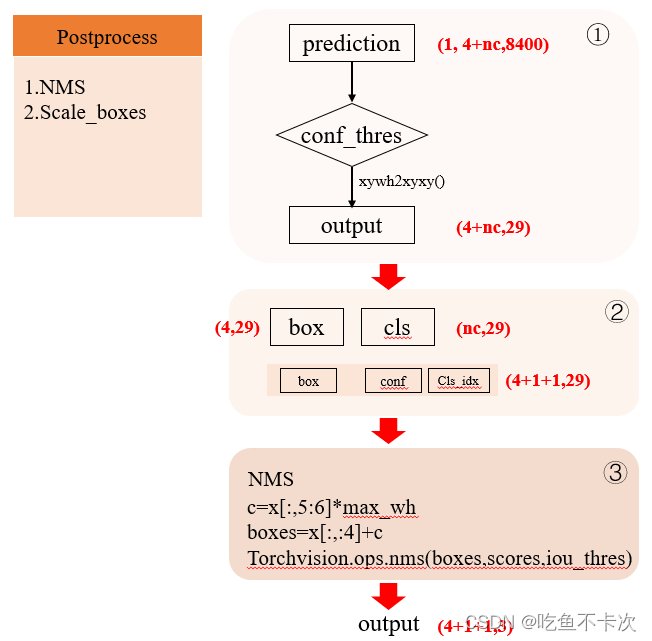
下面是对于不同类别需要加上一个偏移量的理解,见图知意。

Scale_boxes模块是将预测结果映射回到原始输入图片尺寸的,首先将预测的框减去因为latter box产生的偏移量,复原到等比例缩放(640,360)时的每个框的XYXY坐标,然后再将XYXY坐标等比例放大到原始图像(1280,720)的坐标,最后把得到的XYXY坐标信息进行裁剪到指定的图像尺寸范围内,确保边界框不会超出图像的实际尺寸,简而言之就是不让预测框超出原始图像尺寸。

至此,YOLOv8模块的预测部分就到此结束,下一章节将介绍目标检测任务中训练流程,有了对预测流程的理解,训练流程就比较容易理解了。
2.YOLOv8训练流程原理
未完待续...