获取本文论文原文PDF,请公众号【AI论文解读】留言:论文解读

引言:重新审视语言模型的预训练策略
在人工智能领域,大型语言模型(LLMs)的发展一直是一个不断进步的旅程。随着模型参数和数据集规模的增加,下一个词的预测准确性不断提高,从而推动了人工智能的显著进步。然而,传统的语言模型预训练方法将相同的下一个词预测损失应用于所有训练令牌,这种做法可能并非总是最优的。事实上,即使是经过精心筛选的高质量数据集,也仍然包含许多可能对训练产生负面影响的噪声令牌。这些噪声令牌可能会浪费计算资源,并可能限制语言模型潜在的能力。
在这种背景下,我们提出了一个新的观点:“并非语料库中的所有令牌对于语言模型训练都同等重要”。通过对语言模型在令牌级别的训练动态进行深入分析,我们发现不同令牌的损失模式存在显著差异。这些洞察促使我们引入了一种新的语言模型预训练策略——选择性语言建模(Selective Language Modeling, SLM)。与传统的语言模型不同,SLM策略通过评分预训练令牌并专注于对那些与期望分布一致的有用令牌进行训练,从而提高了预训练的效率和性能。
本章节将探讨这种新的预训练策略,并通过实验结果展示其在数学任务和一般任务中的有效性。通过对数学领域和一般领域的持续预训练,我们的模型在多个任务上取得了显著的性能提升,这进一步证明了SLM策略的有效性。
论文标题、机构、论文链接
- 论文标题:RHO-1: Not All Tokens Are What You Need
- 机构:Xiamen University, Tsinghua University, Microsoft
- 论文链接:https://arxiv.org/pdf/2404.07965.pdf
RHO-1模型与选择性语言建模(SLM)的介绍
1. 传统语言模型预训练的局限性
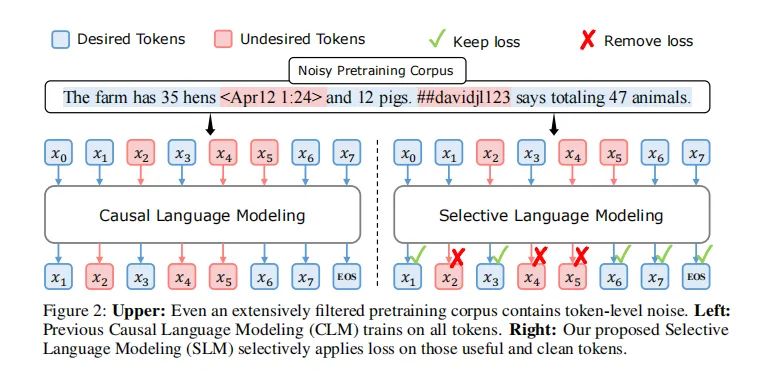
传统的语言模型预训练方法普遍采用对所有训练token应用下一个token预测损失的方式。这种方法虽然简单直接,但并不总是最优或可行的。尽管通过各种启发式方法和分类器对训练文档进行筛选已经成为提升数据质量、增强模型性能的重要手段,高质量数据集中仍然存在许多噪声token,这些token可能会对训练产生负面影响。研究表明,网络数据的分布并不总是与下游应用的理想分布一致,普通语料库中的token可能包含不希望的内容,如幻觉或难以预测的高度模糊token。对所有token应用相同的损失可能会在非益处token上浪费计算资源,限制语言模型的潜力。
2. SLM的核心理念与方法概述
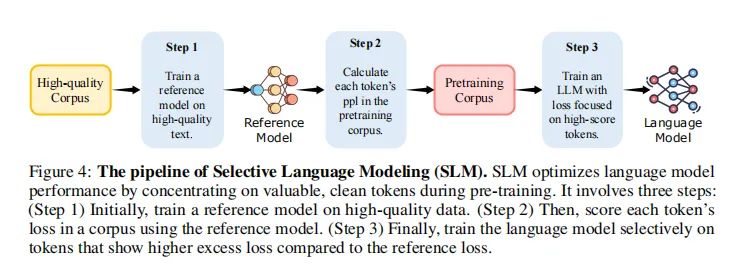
选择性语言建模(SLM)是一种新颖的语言模型训练方法,它通过选择性地训练对期望分布有用的token来提高预训练的效率和性能。SLM的核心思想是,不是在语料库中预测每个下一个token,而是使用参考模型对预训练token进行评分,然后只对那些与参考模型相比有较高额外损失的token进行训练。这种方法涉及三个步骤:首先,在高质量数据集上训练一个参考模型;然后,使用参考模型评分每个token的损失;最后,只训练那些显示出高额外损失的token。通过这种方式,SLM有效地识别出与目标分布相关的token,从而在模型训练中专注于这些token,提高了token效率并改善了下游任务的性能。
训练动态分析:不同类别的Token损失变化
1. Token损失分类及其在训练中的变化模式
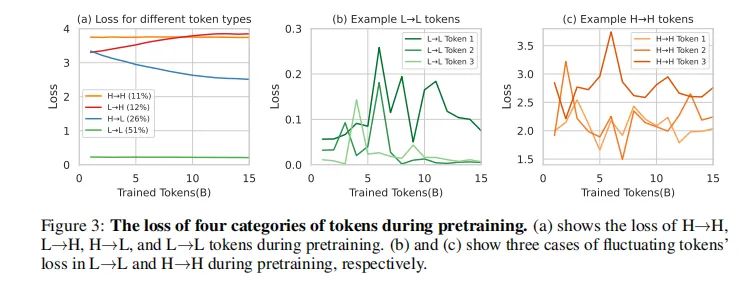
在标准预训练过程中,对单个token的损失如何演变进行了深入分析。通过在OpenWebMath的15B token上继续预训练Tinyllama-1B模型,并在每训练1B token后保存检查点,然后使用验证集评估这些间隔处的token级别损失。发现token根据其损失轨迹分为四类:持续高损失(H→H)、增加损失(L→H)、减少损失(H→L)和持续低损失(L→L)。显著的是,只有少数token(26%)在训练中显示出显著的损失减少(H→L),而大多数token(51%)保持在L→L类别,表明它们已经被学习。此外,11%的token持续面临挑战(H→H),可能是由于高不确定性。
2. 高损失与低损失Token的训练动态
显著数量的token损失在训练中表现出持续的波动,并抵抗收敛。L→L和H→H类别的token损失在训练中显示出高方差。通过可视化和分析这些token的内容,发现许多噪声token,这与我们的假设一致。因此,训练中每个token的损失并不像总体损失那样平滑减少;相反,不同token之间存在复杂的训练动态。如果能够选择适当的token让模型在训练中专注于它们,可能会稳定模型的训练轨迹并提高其效率。
SLM的实现流程
1. 参考模型的建立与Token评分
在实现选择性语言模型(SLM)的过程中,首先需要建立一个参考模型(RM)。这个模型是在精心筛选的高质量数据集上训练的,它的目的是为了评估预训练语料库中每个Token的损失。通过计算参考模型对每个Token分配的概率,我们可以得到每个Token的参考损失(Lref)。这个评分过程帮助我们确定了哪些Token对于语言模型训练最有影响力。
2. 基于过量损失的Token选择
在Token评分的基础上,SLM方法进一步定义了过量损失(L∆),即当前训练模型的损失(Lθ)与参考损失(Lref)之间的差异。通过引入Token选择比例(k%),我们可以确定基于过量损失排名前k%的Token。这些Token被认为是对于语言模型学习最有益的,因此在训练过程中会重点关注这些Token。
3. 选择性损失的应用与效率提升
最后,SLM方法通过仅在选定的Token上应用损失来训练语言模型。这个过程通过排名批次中的Token并仅使用过量损失最高的k%的Token进行训练来实现。这种方法有效地排除了不需要的Token,同时在预训练过程中不会产生额外的成本,使得这种方法既高效又易于集成。
数学领域预训练结果
1. RHO-1在数学任务中的表现与效率
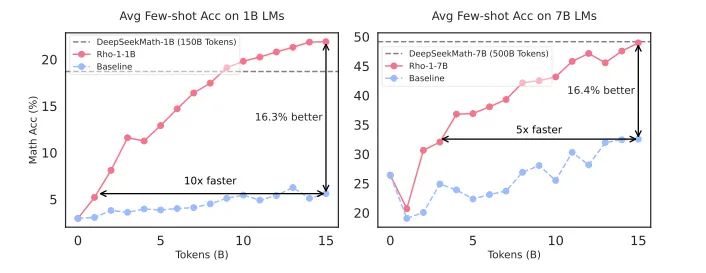
在数学领域的持续预训练中,RHO-1模型展现了显著的效率和性能。在使用15B OpenWebMath语料库进行预训练时,RHO-1在9个数学任务中的少数样本准确率上实现了高达30%的绝对提升。在微调后,RHO-1-1B和7B模型在MATH数据集上分别达到了40.6%和51.8%的最新水平,与DeepSeekMath-7B相当,但仅使用了DeepSeekMath所需预训练Token的3%。
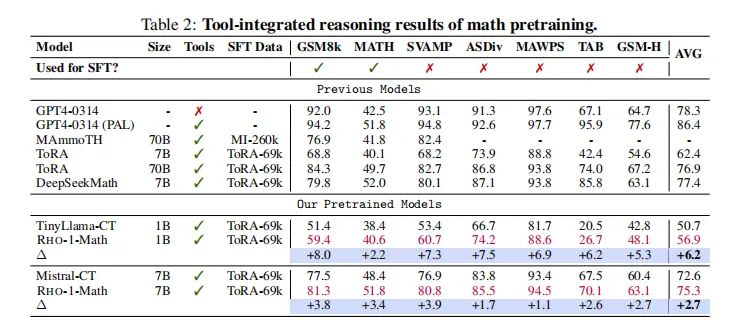
2. 与其他模型的比较与状态分析
与其他知名和表现优异的基线模型相比,RHO-1在数学任务中的表现尤为突出。在少数样本链式推理(CoT)任务中,与直接持续预训练相比,RHO-1在1B和7B模型上分别实现了16.5%和10.4%的平均准确率提升。此外,在工具集成推理结果中,RHO-1-1B和RHO-1-7B在MATH数据集上分别实现了40.6%和51.8%的最新水平,证明了SLM方法在数学领域预训练中的有效性。
通用领域预训练结果
1. SLM在通用任务中的应用与性能提升
在通用领域的预训练中,SLM(Selective Language Modeling)方法被用于优化语言模型的训练效率。通过对15B OpenWebMath语料库的持续预训练,SLM在9项数学任务中实现了高达30%的绝对准确率提升。在细化调整(fine-tuning)后,1B和7B参数规模的RHO-1模型在MATH数据集上分别达到了40.6%和51.8%的准确率,与DeepSeekMath相当,但仅使用了3%的预训练语料。此外,在80B通用语料上的预训练中,SLM使得模型在15项不同任务上平均提升了6.8%,这表明SLM不仅提高了预训练的效率,还提升了模型的性能。
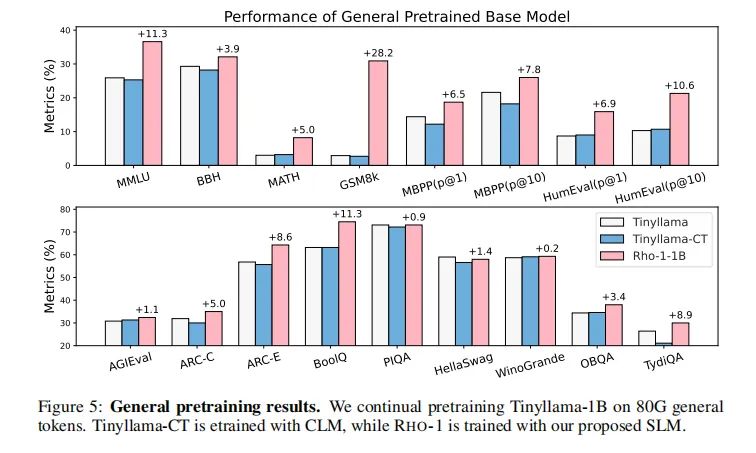
2. 选择性Token训练对模型性能的影响
选择性Token训练是SLM的核心,它通过对预训练语料中的Token进行评分,只对那些与期望分布更加一致的Token施加损失。这种方法自然地过滤掉了不干净或不相关的Token。实验结果显示,SLM在数学持续预训练中显著提高了Token的效率,并在下游任务上取得了更好的性能。例如,在Tinyllama-1B模型上,使用SLM对80B通用Token进行预训练,与直接持续预训练相比,在15个基准测试中平均提高了6.8%,尤其在代码和数学任务中提升超过了10%。
分析与讨论
1. 选择性Token损失与下游任务性能的关联
SLM通过参考模型筛选Token,并观察在所有选定Token上训练后的验证损失变化,同时监测它们与下游损失的关系。结果表明,在参考模型选定的Token上,RHO-1的平均损失下降比常规预训练更为显著。相反,在未被选定的Token上,常规预训练的平均损失下降更为显著。这意味着,选择性预训练不仅在训练阶段降低了特定Token的平均损失,而且在下游任务中也实现了显著的损失降低,从而提高了预训练的效率。
2. SLM选择的Token特征与训练效率
SLM在预训练中选择的Token主要与数学内容紧密相关,这有效地训练了模型关注原始语料库中与数学相关的部分。此外,随着训练过程的推进,模型倾向于优先选择在训练后期具有更高困惑度(perplexity)的Token,这表明模型首先优化了具有较大可学习空间的Token,从而提高了学习效率。
3. Token选择比例对模型性能的影响
Token选择比例是SLM中的一个重要参数,它决定了基于过剩损失被纳入训练的Token比例。实验表明,选择比例约为60%时,选定的Token最适合模型学习,这进一步证实了SLM方法在提高预训练效率方面的有效性。
相关工作与未来展望
1. 数据选择与语言模型训练动态的研究进展
近年来,大型语言模型(LLM)的研究取得了显著进展,尤其是在模型参数和数据集规模的扩展方面。然而,对所有可用数据进行训练并不总是最优或可行的。因此,数据过滤的实践变得至关重要,使用各种启发式和分类器来选择训练文档。这些技术显著提高了数据质量并提升了模型性能。
尽管进行了彻底的文档级过滤,高质量数据集仍然包含许多可能对训练产生负面影响的噪声令牌。为了探索语言模型在令牌级别的学习方式,我们对训练动态进行了初步分析,特别是令牌级别损失的演变。我们发现,在训练过程中,显著的损失减少仅限于一小部分令牌。许多令牌是“已经学会的简单令牌”,而一些是“难令牌”,表现出变化的损失并抵抗收敛。这些令牌可能导致大量无效的梯度更新。
基于这些分析,我们引入了一种名为RHO-1的新型语言模型,该模型采用了一种新颖的选择性语言建模(SLM)目标。与传统的语言模型不同,SLM通过选择性地训练与期望分布一致的有用令牌来提高预训练的效率和性能。
2. SLM的潜在应用与改进方向
SLM的潜在应用非常广泛,它不仅能够提高预训练的效率,还能改善下游任务的性能。在数学持续预训练方面,1B和7B的RHO-1模型在GSM8k和MATH数据集上的平均少样本准确率提高了超过16%,并且在达到基线性能上比传统方法快5到10倍。此外,RHO-1-7B仅使用15B令牌与DeepSeekMath-7B的性能相当,后者预训练了500B令牌,这证明了我们方法的高效性。
在通用预训练方面,通过在80B通用令牌上持续训练Tinyllama-1B模型,SLM在15个基准测试中平均提高了6.8%,尤其在代码和数学任务中提升超过10%。这些结果表明,SLM有效地识别了与目标分布相关的令牌,从而在基准测试中改善了模型的困惑度得分。
未来的改进方向可能包括:使用SLM进行监督式微调,以解决许多SFT数据集中的噪声和分布不匹配问题;将SLM扩展到对齐领域,例如通过训练一个强调有益、真实和无害的参考模型,我们可能会在预训练阶段获得一个天然对齐的基础模型;探索使用多个参考模型来减少过拟合;设计令牌级别的课程学习和迭代策略以实现持续改进等。
总结
本文介绍了一种新型的选择性语言建模(SLM)方法,该方法通过选择性地训练对下游任务有益的令牌来优化语言模型的预训练。我们的研究表明,SLM能够显著提高预训练的效率,并在各种任务上提升模型的性能。未来的工作将探索SLM的进一步应用和改进方向,以实现更高效、更有效的语言模型训练。