目录
1.索引
1.1索引的介绍
在关系型数据库中,如果一张表中的数据过多,那么在查找的时候会很慢, 这是因为数据库查询的时候,会便利表中的数据. 而且数据库中的数据是在硬盘中存储的,硬盘的IO操作时间是远远低于内存的. 所以就很影响用户体验. 针对这种情况,我们引入了索引这种概念,-Index ,index在英文中也叫目录,就和我们翻看书的时候,可以查看目录,就可以很快的查找到我们想要的数据了.
1.2 索引的特点
索引的特点就是可以加快查询速度,但是它自身也是一种数据结构(b+树,哈希索引) 所以会占据内存空间,当我们在进行查询操作比较多的时候(大部分情况是这样),就适合对这个列加入一个索引, 如果是增加,删除,修改操作比较多的时候就不太适合加入索引了.因为在这些操作的时候,除了会对数据本身进行操作,也会对索引进行修改.所以就会有一些额外的开销.
1.3索引的使用场景以及关于索引的sql语句
在前面索引的特点中我们说到了,索引是一种占据内存空间的数据结构,并且查询较快.所以在我们硬盘空间比较充裕的时候,可以空间换时间,我们可以加上索引. 或者就是一个业务中的查询操作比较多的时候,我们就可以使用索引
关于索引的sql语句:
1.3.1查看索引
show index from 表名

在MySQL中 primary和unique 还有foreign key 会自动生成索引
1.3.2创建索引
create index 索引名 on 表名(列名);
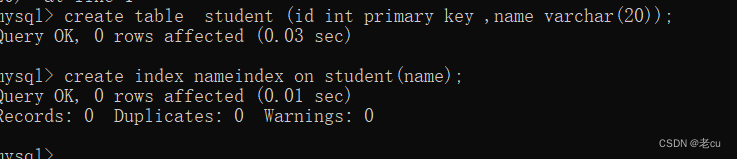
我们查看一下这个表的索引:

可以看出有两个索引了已经 这个创建索引的操作其实也很危险,因为如果表中的数据很多的话,就会触发大量的磁盘io,一不小心就可能把数据库搞挂了. 所以创建索引这个操作,尽量是在表中数据比较少 或者空着的时候创建. 在数据库设计的时候就给它设计好
1.3.3 删除索引
drop index 索引名 on 表名;

可以看出 ,我们删除索引了以后,在查询这个表的索引,已经查询不到了.
1.4 索引底层的数据结构实现
我们在上面对索引的介绍中,聊到了索引这种东西也会有数据结构,会占用内存空间.那么索引具体是哪种数据结构呢?为什么要用这种数据结构.
像链表,队列,栈 ,数组这些 不适合查找当然不在我们的考虑中. 而二叉搜索树这种,倒也可以,查询效率是log2n,但是它的高度会很高. 也不太适合, 哈希表虽然查询是o(1)的效率,但是它只支持点对点查询,当我们查询一个集合 比如 select * from student where id>=1; 的时候就不太适合了.
因此, 数据库的索引,使用了B+树作为数据结构,B+树,相当于是针对数据库这个场景量身定做的一样.
要想了解B+树,我们得先了解B树.接下来我会用画板来画一下
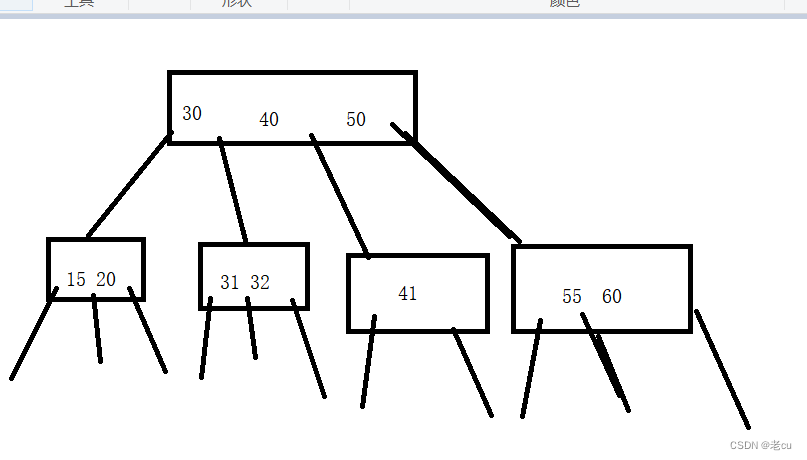
通过上图,我们可以得出以下几点信息
1.一样高度的树,能表示的元素就比二叉搜索树要多很多
2. 轮比较次数比二叉搜索树要多
3.同一个节点的这些key 都是一次硬盘IO就出来了. 即使总的比较次数增加了.但是硬盘IO次数减少了.内存的比较速度比硬盘IO要快得多.
但是也有几个问题,比如我们要找到15-40之间的树,就不太方便,首先得从30的左边下去,在从30的右边下去找,还有四十这个数字.而且不是很稳定,
相比之下,B+树就做了不少的优化了.我们来看看B+树是什么样子.
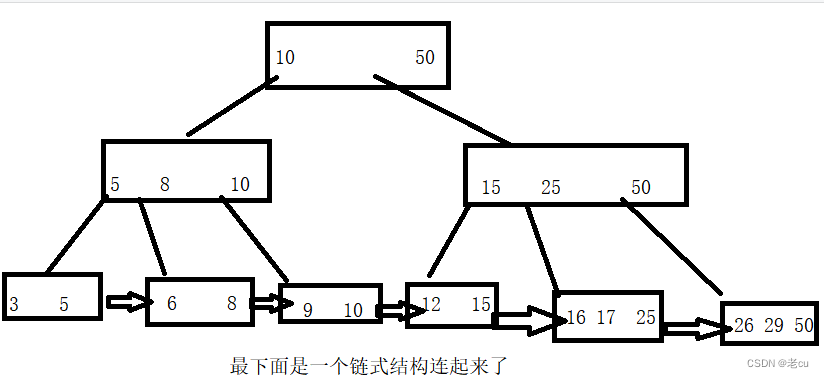
我们可以看出B+树有以下特点:
1.每一个子节点都有其父节点的最大值.
2.叶子节点包含了所有的值
3. 查找比较稳定
在我们查找比如 5 - 15的时候,只需要向下找到5,在往右遍历即刻找到我们想要的集合.
B+树存的非叶子节点只包含键值信息,而不包含数据信息,这样可以使得每个节点能够存储更多的键值对,从而减少树的高度,提高查询效率。
2.事务
1.什么是事务
我们在进行sql语句数据库操作的时候,有时候会出现错误的情况.一个经典的场景就是转账,比如我有两个用户 ,张三和李四,张三向李四转了5000 块钱,
update account set banlance = banlance -5000 where name = '张三';
update account set banlance = banlance + 5000 where name = '李四';
如果我们第一个sql语句成功执行了,在这时候,数据库突然挂二零,第二个并没有成功执行,那就出问题了, 这5000块钱凭空消失了.
所以我们就引入了事务这一概念来解决上述问题,我们希望这两个sql语句的执行具有原子性,即要么都成功,要么都不成功(不成功就有可能会触发回滚),事务的原子性,本质上就是依托于回滚的.
我们可以查看日志,如果数据库好了以后,看如果有这种执行了一半的事务,就给它回滚.
2.事务的四大特性
2.1四大特性(原子性,一致性,持久性,隔离性)
1.原子性,通过事务, 把多个操作打包在一起(最重要的特性)
2.一致性,原子性的扩充,不会出现上述那种钱凭空消失这种情况. 还可以通过约束,避免一些非法的情况
3.持久性: 事务的任何修改,都是持久化存在的,无论是重启程序还是主机,修改都不会消失.
4.隔离性,多个事务同时并发的时候,可能会带来一些问题,通过隔离性对这里的问题进行权衡.
到了事务并发这块,我们可以讲述几个因为并发而产生的典型bug.来更深刻的理解这一特性
2.2典型bug
1.脏读问题
所谓的脏读问题,就是假设当前有两个事务,事务1在写数据的时候,还没提交.事务二就读取了这个数据了.但是后续事务1又改了数据, 此时,事务二读取到的这个数据就是错误的.一个脏的数据.
举个栗子来描述一下脏读问题,就好比我是一个网文作者,在写一本小说,一开始打算把女主写死,正写着呢,结果就让粉丝读到了,给我寄了刀片,但我转念一想,容易被粉丝寄刀片,我就改了一下在提交,但是粉丝这时候已经把刀片寄过来了,这就有了很大的麻烦.
我们可以对写操作进行加锁,在事务一写数据的时候,禁止其它事务进行访问,就可以避免这个问题.
2.不可重复读
不可重复读是建立在脏读问题的基础上,我们对写操作加锁了.比如我们现在有三个事务,
事务一写完并提交了,此时事务二可以读这个数据了.
事务二在读数据,读的过程中,事务三又对这个数据进行修改了. 就会造成读的数据不一致. 同一个事务读的数据不是一样的,这就是不可重复读bug
举个栗子, 我在逛淘宝的时候,看到了一些学习资料,售价五毛钱,哪怕我平时不怎么看学习资料,但是因为价格的诱惑,忍不住出手,下单了.但是在付钱的时候,突然价格变成50块钱了. 这心理落差太大了,用户难以接受.
为了解决这个问题,我们可以对读也加锁,简称为'读加锁',就是一个事务在读数据的时候,其它事务不能对这个数据进行写操作.
让并发的程度降低了,但是数据的准确性增强了.
3.幻读问题.
幻读问题也是在简历解决了不可重复读问题的基础上,比如我们有三个事务
事务1提交了数据,然后事务二读取到了这个修改到的数据,在读这个数据的时候,事务三又提交了一个数据,这个时候,数据二读到的结果集就不一样,比如selecet *的时候 本来有两行数据, 突然变成了三行了,这个问题是不是一个bug也要看具体的业务场景.
2.3MySQL提供的隔离级别
在MySQL中,我们针对这些bug,和并发的情况,提供了不同的隔离级别.以供我们应对更多的业务场景
分别是:
1.读未提交,这种是最不安全,但是效率最高的.(不加锁)
2.读已提交,这种也有点不安全,但是比读未提交安全一些,效率较高(加入了写操作的锁)
3.可重复读,这种比较安全,性能稍弱 MySQL默认提供的隔离级别就是可重复读 (加了读操作和写操作的锁)
4.串行化,放弃了并发执行事务,让事务串行化执行,如事务1执行完,在执行事务2,事务2执行完才能执行事务三, 这种效率最低,但也是最安全的.
上述的隔离级别是MySQL给我们提供的,我们在针对不同的业务场景 , 可以设置不同的隔离级别
2.4开启事务
开启事务非常简单,我们用一个例子来演示一下:
strat transation;--开启事务
sql1; --sql语句
sql2; --sql语句
sql3;... (把这些sql语句打包成一个整体)
commint; --告诉服务器,事务提交了
(rollback) --告诉服务器,进行回滚