背景:
网上找了好些博客,但是实现的都不全,或者压根不太对,代码书写也不太规范,所以自己参考这些博客以及C语言词法规则,用qt重新写了这么一个词法分析器。
目标:
读取程序,自动进行词法拆分,输出拆分结果,包括11种词法结果:
0 非法
1 关键字
2 标识符
3 常数
4 运算符
5 分隔符
6 特殊字符
7 预处理命令
8 单行注释
9 多行注释
10 字符串
实现原理:
其实就是一个状态机进行识别,这个网上可以找到很多资料,不赘述了。
话不多说,先看效果,然后直接上源码,自我认为本人写的比较清晰,方便阅读和复用的。
效果图如下:
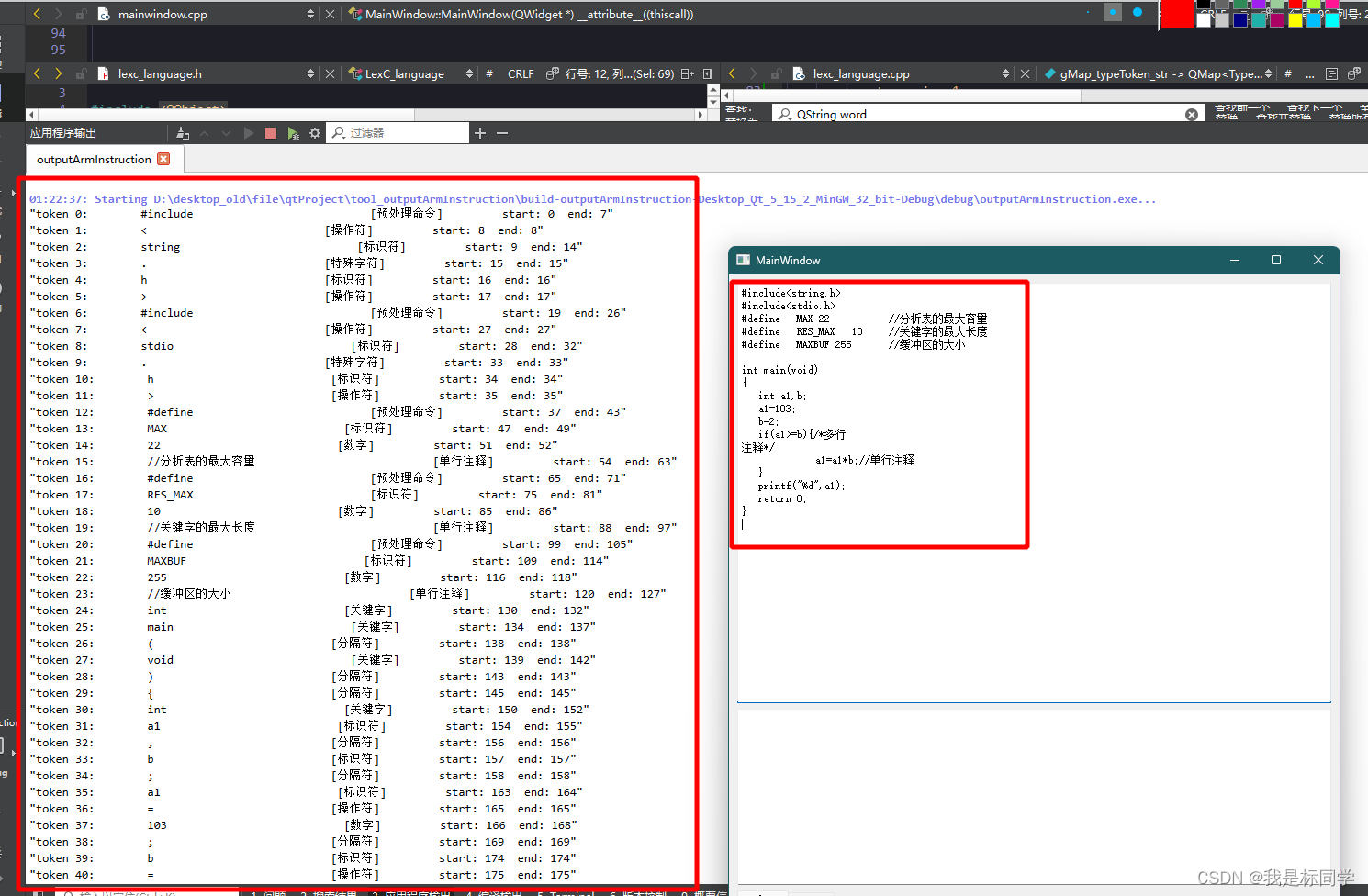
源码如下:
包括 lexc_language.h 和 lexc_language.cpp 两个文件,总计约600行代码。
首先是 lexc_language.h:
#ifndef LEXC_LANGUAGE_H
#define LEXC_LANGUAGE_H
#include <QObject>
#include <QDebug>
/*
编译原理实验一:词法分析器
要求:编制一个读单词过程,从输入的C语言源程序中,识别出各个具有独立意义的单词,即:
0 非法
1 关键字
2 标识符
3 常数
4 运算符
5 分隔符
6 特殊字符
7 预处理命令
8 单行注释
9 多行注释
10 字符串
*/
/*
强类型枚举(enum class) 的主要优势在于:
提供了更好的类型安全:不能直接看做整型数据,枚举就是枚举,不能做整型相关的运算
以及更严格的作用域控制:带作用域,其类名就是作用域
可以显示指定其底层存储类型,默认为int。(为其他的比如char的话 有什么作用和意义我不太清楚,也没见过)
缺点:
你希望你的枚举值支持位运算,如果用enum class,你需要重载你所需要的位运算操作符
*/
enum class TypeToken
{
Illegal = 0,
Keyword = 1,
Identifier = 2,
Number,
Operator,
Delimiter,
SpecialSym,
CmdPreprocess,
CommentSingle,
CommentMulti,
String //10
};
struct Token
{
Token() {_type = TypeToken::Illegal; _start_end.first = 0; _start_end.second = 0;}
Token(QString str, TypeToken type, QPair<int, int> start_end)
{_str = str; _type = type; _start_end = start_end;}
QString _str;
TypeToken _type;
QPair<int, int> _start_end;
};
extern QMap<TypeToken, QString> gMap_typeToken_str;
class LexC_language : public QObject
{
Q_OBJECT
public:
explicit LexC_language(QString str, QObject *parent = nullptr);
QList<Token> getTokens(bool skipComment = true)
{
if(skipComment)
{
QList<Token> tokens;
for (int i = 0; i < _tokens.size(); ++i) {
if(_tokens.at(i)._type != TypeToken::CommentSingle && _tokens.at(i)._type != TypeToken::CommentMulti)
tokens.append(_tokens.at(i));
}
return tokens;
}
return _tokens;
}
Token getNextToken(bool skipComment = true)
{
if(_index >= _tokens.size())
return Token();
if(skipComment)
{
Token tok = _tokens.at(_index);
while(tok._type == TypeToken::CommentSingle || tok._type == TypeToken::CommentMulti)
{
_index++;
if(_index >= _tokens.size())
return Token();
tok = _tokens.at(_index);
}
_index++;
return tok;
}
return _tokens.at(_index++);
}
Token getToken(int index)
{
if(index < _tokens.size())
return _tokens.at(index);
return Token();
}
void reset(){_index = 0;}
void printTokens()
{
for (int i = 0; i < _tokens.size(); ++i)
{
QString str = "token %1: %2 [%3] start: %4 end: %5";
Token tok = _tokens.at(i);
qDebug()<<str.arg(i).arg(tok._str).arg(gMap_typeToken_str.value(tok._type))
.arg(tok._start_end.first).arg(tok._start_end.second);
}
}
private:
void analyse();
//判断是否为字母
bool isChar(char ch)
{
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'))
return true;
return false;
}
//判断是否为数字
bool isDigit(char ch)
{
if (ch >= '0' && ch <= '9')
return true;
return false;
}
//判断是否为定界符等
bool isDelimiters(char ch)
{
if(_delimiters.contains(QString(ch)))
return true;
return false;
}
//判断是否为控制命令
bool isCmdPreprocess(QString str)
{
if(_cmdPreprocess.contains(str))
return true;
return false;
}
//判断是否为关键字
bool isKeyword(QString str)
{
if(_keyword.contains(str))
return true;
return false;
}
//判断是否为运算符
bool isOperators(char ch)
{
if(_operators.contains(QString(ch)))
return true;
return false;
}
//判断是否为特殊字符
int isSpesymbols(char ch)
{
if(_specialSym.contains(QString(ch)))
return true;
return false;
}
private:
int _index = 0; //以token为单位的序号,而不是字符指针位置
QList<Token> _tokens;
QString _str;
//关键字
QStringList _keyword = {"main", "int", "double", "struct", "if", "else", "char", "return", "const", "float",
"short", "void", "while", "for", "break", "then", "long", "switch", "case", "do", "static", "typedef", "continue",
"default", "sizeof", "do", "extern", "static", "auto", "register", "sizeof"};
//运算符
QStringList _operators = {"+", "-", "*", "/", "=", ">", "<", "^", "&", "|", "!"};
//分割符
QStringList _delimiters = {",", "(", ")", "{", "}", "[", "]", ";"};
//特殊字符
QStringList _specialSym = {".", "$", "?", "~", "^", "%", "\\", ":", "`", "@"};
//预处理命令
QStringList _cmdPreprocess = {"#include", "#define", "#undef", "#asm", "#endasm", "#ifdef", "#ifndef", "#else", "#endif"};
};
#endif // LEXC_LANGUAGE_H
然后是 lexc_language.cpp:
#include "lexc_language.h"
#include <sys/types.h>
//还能做更多的功能,例如所有的单行注释形式,一次性转为多行注释形式,都是能自己能扩展的
//科学计数法
// 数字
//const char* number_rule="^([+-]?\\d+\\.\\d+)|([+-]?\\d+)|([+-]?\\.\\d+)$";
//const std::regex pattern_number(number_rule, regex::icase);
//科学计数
//const char* scientific_rule="^[+-]?((\\d+\\.?\\d*)|(\\.\\d+))[Ee][+-]?\\d+$";
//const regex pattern_scientific(scientific_rule, regex::icase);
// 十六进制
//const char* hex_rule="^[+-]?0[xX]([A-Fa-f0-9])+$";
//const regex pattern_hex(hex_rule, regex::icase);
// 八进制
//const char* oct_rule="^0([0-7])+$";
//const regex pattern_oct(oct_rule, regex::icase);
QMap<TypeToken, QString> gMap_typeToken_str =
{
{TypeToken::Illegal, "非法符号"},
{TypeToken::Keyword, "关键字"},
{TypeToken::Identifier, "标识符"},
{TypeToken::Number, "数字"},
{TypeToken::Operator, "操作符"},
{TypeToken::Delimiter, "分隔符"},
{TypeToken::SpecialSym, "特殊字符"},
{TypeToken::CmdPreprocess, "预处理命令"},
{TypeToken::CommentSingle, "单行注释"},
{TypeToken::CommentMulti, "多行注释"},
{TypeToken::String, "字符串"}
};
LexC_language::LexC_language(QString str, QObject *parent)
: QObject{parent}
{
_str = str;
analyse();
}
void LexC_language::analyse()
{
int line = 0;
int tmp = 0;
for (int i = 0; i < _str.size(); ++i)
{
//每次循环回来,都是新的token开始了的
char ch = _str.at(i).toLatin1();
if(ch==' ' || ch=='\t')
continue;
else if(ch == '\n')
line++;
else if(isChar(ch) || ch == '_') //合法标识符开始了,但可能是标识符或者关键字
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
while(isChar(ch) || isDigit(ch) || ch == '_') //只要接下来的当前字符是 字符,或者 数字,都属于该标识符
{
tmp++;
if(tmp >= _str.size())
break;
ch = _str.at(tmp).toLatin1();
}
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Identifier, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
if(isKeyword(word))
tok._type = TypeToken::Keyword;
_tokens.append(tok);
}
else if(ch == '#') //预处理器符号
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
while(isChar(ch)) //只要接下来的当前字符是 字符,都属于该预处理器符号
{
tmp++;
if(tmp >= _str.size())
break;
ch = _str.at(tmp).toLatin1();
}
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Illegal, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
if(isCmdPreprocess(word))
tok._type = TypeToken::CmdPreprocess;
_tokens.append(tok);
}
else if(ch == '"') //字符串
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
while(1) //只要接下来的当前字符都属于该字符串,除非遇到 "
{
tmp++;
if(tmp >= _str.size())
break;
ch = _str.at(tmp).toLatin1();
if(ch == '"')
{
tmp++; //注意,这里需要++,因为"也是属于字符串的内容的
break;
}
}
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::String, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
}
//数字。注意:数字的合法性判定比较复杂,因为有小数,科学计数,负数,十六进制数,二进制数等,形式多样,所以下面仅做了常见非法情况的判定而已
else if ( (ch == '-' && (i+1<_str.size()) && isDigit(_str.at(i+1).toLatin1())) //负号打头那么后面就一定等跟着数字才行
|| isDigit(ch) ) //或者直接是数字打头
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
while(isDigit(ch) || ch == '.' || isChar(ch))
{
tmp++;
if(tmp >= _str.size())
break;
ch = _str.at(tmp).toLatin1();
}
}
QString word = _str.mid(i, tmp-i);
TypeToken type = TypeToken::Number;
if(isChar(ch) && ch != 'e' && ch != 'E' && ch != 'f' && ch != 'F' && ch != 'l' && ch != 'L') //如果数字的结尾,是一个字母,但是不是 e, E等,说明非法符号
type = TypeToken::Illegal;
else if(word.count('.') > 1) //小数点大于1一个,也非法
type = TypeToken::Illegal;
Token tok(word, type, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
}
else if (isDelimiters(ch)) //分隔符
{
tmp = i + 1;
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Delimiter, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
}
else if (isSpesymbols(ch)) //分隔符
{
tmp = i + 1;
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::SpecialSym, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
}
else if (isOperators(ch)) //操作符,由于操作符需要超前一个字符才能判断的,例如|和||就是不同的操作符
{
switch (ch) //其他字符
{
case'<':
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
if (ch == '=' || ch == '<')
tmp++;
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Operator, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
break;
}
case'>':
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
if (ch == '=' || ch == '>')
tmp++;
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Operator, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
break;
}
case'|':
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
if (ch == '|')
tmp++;
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Operator, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
break;
}
case'&':
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
if (ch == '&')
tmp++;
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Operator, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
break;
}
case'!':
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
if (ch == '=')
tmp++;
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Operator, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
break;
}
case'+':
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
if (ch == '+')
tmp++;
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Operator, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
break;
}
case'-':
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
if (ch == '-')
tmp++;
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Operator, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
break;
}
case'=':
{
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
if (ch == '=')
tmp++;
}
QString word = _str.mid(i, tmp-i);
Token tok(word, TypeToken::Operator, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
break;
}
case'/':
{
TypeToken type = TypeToken::Illegal;
tmp = i + 1;
if(tmp < _str.size())
{
ch = _str.at(tmp).toLatin1();
if (ch == '*')
{
type = TypeToken::CommentMulti;
while(1) //只要接下来的当前字符都属于该多行注释,除非遇到 */
{
tmp++;
if(tmp >= _str.size())
break;
tmp++;
if(tmp >= _str.size())
break;
ch = _str.at(tmp-1).toLatin1();
char chNext = _str.at(tmp).toLatin1();
if(ch == '*' && chNext == '/')
{
tmp++; //注意,这里需要++,因为 / 也是属于字符串的内容的
break;
}
tmp--; //注意,这里需要--,防止两个字符两个字符的跳过进行判断,可能会导致刚好错位了 */ 这两个目标字符
}
}
else if (ch == '/')
{
type = TypeToken::CommentSingle;
while(1) //只要接下来的当前字符都属于该多行注释,除非遇到 */
{
tmp++;
if(tmp >= _str.size())
break;
ch = _str.at(tmp).toLatin1();
if(ch == '\n')
break;
}
}
}
QString word = _str.mid(i, tmp-i);
Token tok(word, type, QPair<int,int>(i, tmp-1));
i = tmp - 1; //这里需要回退一个,因为上面的for循环会+1的
_tokens.append(tok);
break;
}
default:
{
QString word = _str.mid(i, 1);
Token tok(word, TypeToken::Operator, QPair<int,int>(i, i));
_tokens.append(tok);
break;
}
}
}
}
}
用法:
LexC_language lexC(ui->plainTextEdit->toPlainText(), this);
lexC.printTokens();参考博客:
- 词法分析器--C实现_词法分析器c语言编写-CSDN博客 该博客实现还算比较全,但是先删掉了空格等预处理,然后再扫一遍程序进行词法拆分,这是不对的,因为识别不了共同前缀的标识符,此外,性能也较低。
- 编译原理:c语言词法分析器的实现_编译原理词法分析器c语言-CSDN博客 该博客实现是正确的,但是功能不全。
- 用C语言实现简单的词法分析器_词法分析器c语言编写-CSDN博客 也是不太全。
- c语言实现词法分析器_词法分析器c语言编写-CSDN博客 与上同理。