hadoop各组件工作流程分析
HDFS YARN MapReduce三者关系
关系图
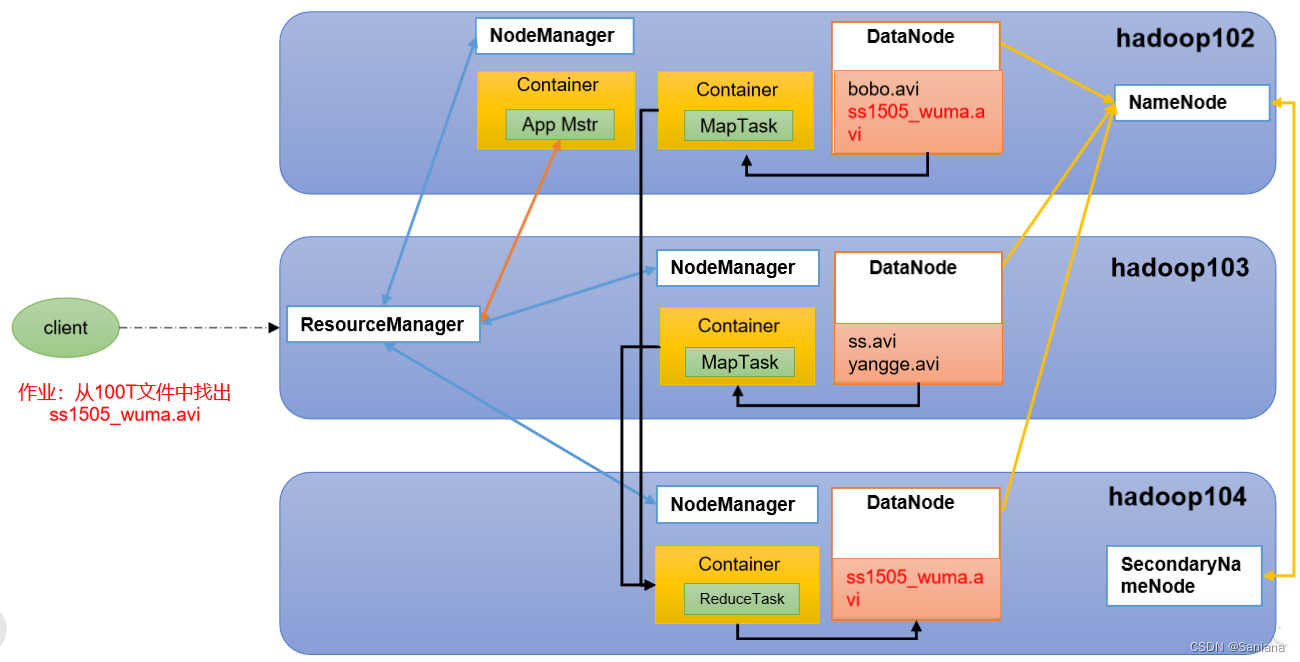
文字描述
- 客户端提交文件给Hadoop -> Yarn -> ResourceManager
- ResourceManager启动App Master
- App Master 申请资源给Container
- 在Container中跑MapTask(数据分成了几片就有几个Map Task)
- Map Task 中的数据从DataNode中来
- Map Task 跑完把数据结果传给Reducer Task
- Reducer Task跑完把结果存入HDFS
HDFS写数据流程
流程图
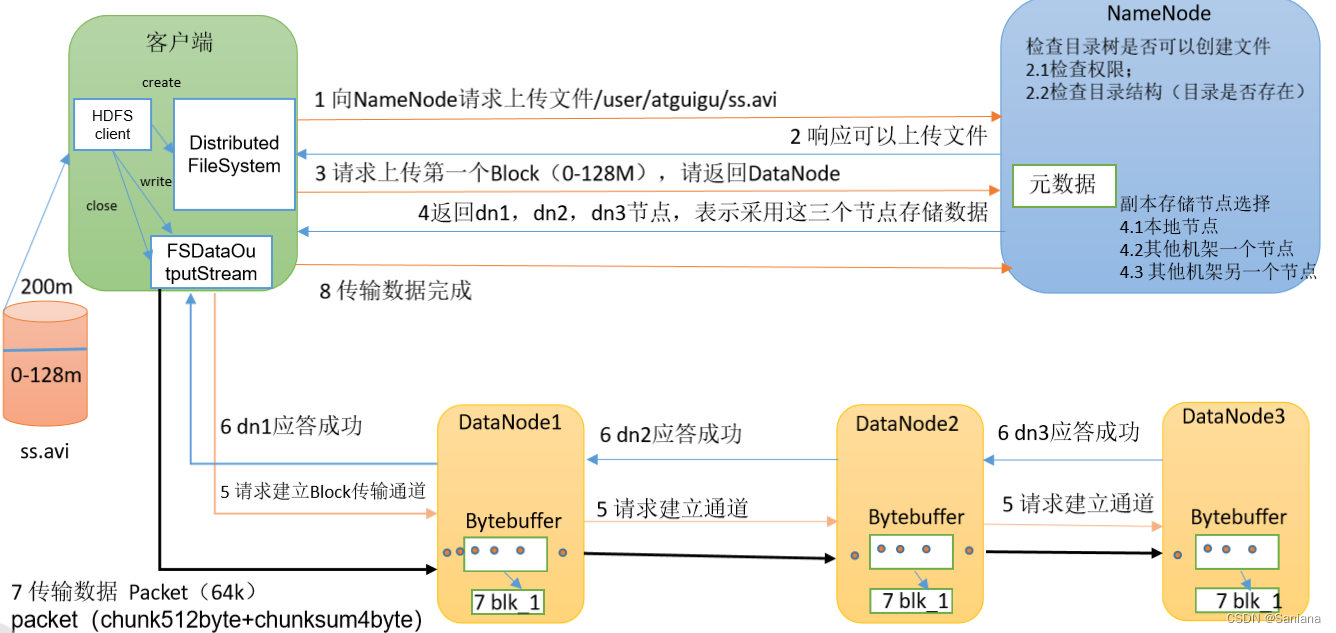
过程描述
- 客户端创建一个 分布式文件系统对象 通过它向NameNode请求上传文件D:\io\input\a.txt
- NameNode检查目录树是否可以上传(权限、目录是否已经存在等),响应可以上传
- 客户端向NameNode请求上传Block(0-128M)
- NameNode返回dn1 dn2 dn3节点 (副本节点选择:本地节点 其他机架一个节点 其他机架另一个节点 选距离最近的 拓扑)
- 客户端和DataNode1建立传输通道,然后DataNode1和DataNode2建立传输通道,DataNode2和DataNode3建立传输通道,应答成功就可以开始传输数据了
- 从本地读取数据后开始传输,一个包一个包的传。Packet 64k 含 chunk512byte + chunksum4byte
- DataNode节点会一个一个的把Packet写在磁盘上(落盘)
- 传输完成后若还有块er没传完,回到第三步直到所以块都传输完成
HDFS读数据流程
流程图
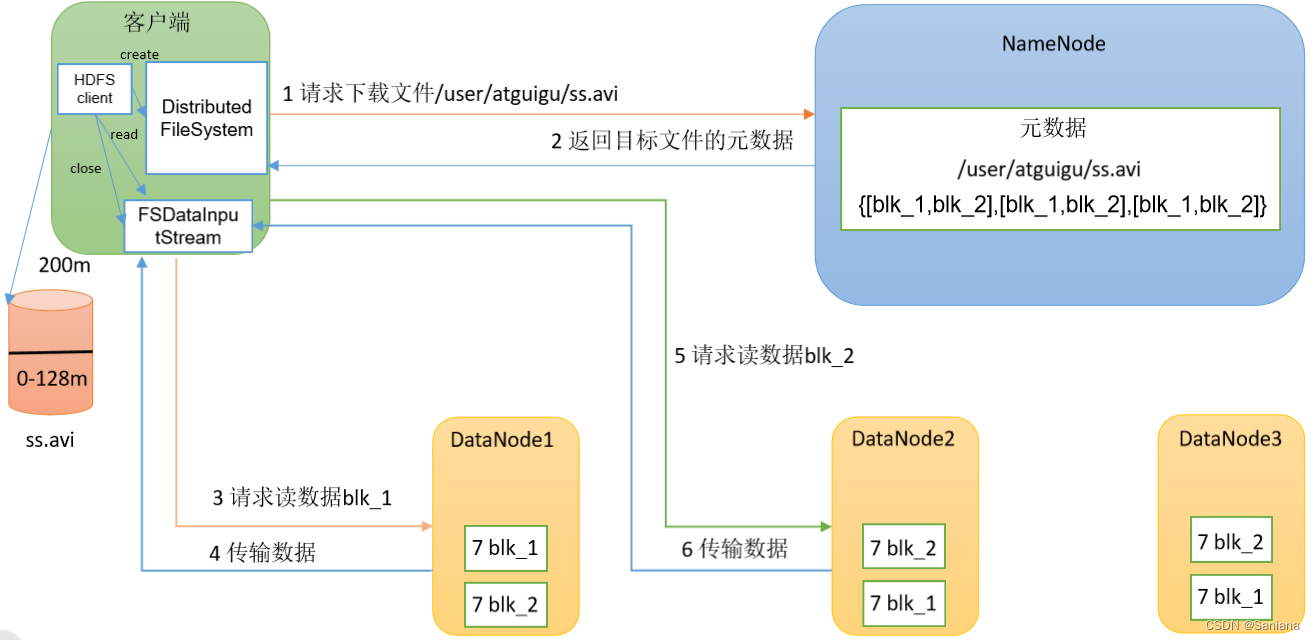
过程描述
- 客户端创建文件系统对象 Distributed FileSystem 向NameNode发送读数据请求
- NameNode看客户端有没有读权限并看看自己有没有该数据,返回目标文件的 元数据
- 客户端创建流 读数据流
- 向目标DataNode节点发送读数据请求(块信息等)
- 目标节点向客户端传输数据
- 传输完成若还有块等待读取数据就重复步骤4直到数据都读完
- 将文件改名后关闭流
切片源码
/*
getFormatMinSplitSize() : 返回1
getMinSplitSize(job) :如果配置了mapreduce.input.fileinputformat.split.minsize参数返回参数设置的值
否则返回默认值1
*/
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
/*
如果设置了mapreduce.input.fileinputformat.split.maxsize参数那么返回该参数设置的值
否则返回Long.MAX_VALUE
*/
long maxSize = getMaxSplitSize(job);
//该集合用来存放切片信息(一个切片就是一个对象)
//放入到该集合的对象是FileSplit 但是泛型是InputSplit 说明FileSplit和InputSplit有继承关系
//FileSplit是InputSplit的子类
List<InputSplit> splits = new ArrayList<InputSplit>();
//获取输入目录中所有的文件或目录状态
List<FileStatus> files = listStatus(job);
//获取文件的路径
Path path = file.getPath();
//获取文件的大小
long length = file.getLen();
//块大小
long blockSize = file.getBlockSize();
/*
切片大小
默认 : 片大小 = 块大小
需求:
片大小 > 块大小 :修改minSize大小
片大小 < 块大小 :修改maxSize大小
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
*/
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
//剩余文件大小
long bytesRemaining = length;
/*
开始切片 :
((double) bytesRemaining)/splitSize > SPLIT_SLOP : 剩余文件大小 / 切片大小 > 1.1 (为了防止最后1片太小)
*/
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
/*
makeSplit : 创建FileSplit对象
参数length-bytesRemaining :片的起始位置
参数splitSize :切片大小
将FileSplit对象放入到splits集合中
*/
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
//重新计算剩余文件大小 :将片大小从剩余文件大小减掉
bytesRemaining -= splitSize;
}
//将剩余文件大小整体切一片
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
not splitable
//如果文件不可切整个文件是1片
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
InputFormat
一 InputFormat : 抽象类
作用 :①切片 ②读取数据
//切片
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
//创建RecordReader对象 该对象用来读取数据
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
二 InputFormat的继承树
|-----InputFormat 抽象类
|------FileInputFormat 抽象类
|-------TextInputFormat 默认使用的InputFormat的类
三 FileInputFormat 抽象类
1.FileInputFormat是抽象类 继承了 InputFormat
2.FileInputFormat实现了父类的getSplits方法
四 TextInputFormat 默认使用的InputFormat的类
1.TextInputFormat是默认使用的InputFormat的类 继承了FileInputFormat
2.TextInputFormat实现了createRecordReader方法
3.createRecordReader方法返回了LineRecordReader,LineRecordReader是RecordReader的子类
4.LineRecordReader是真正用来读取文件中的数据的那个对象的所属类
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
return new LineRecordReader(recordDelimiterBytes);
}
conbineTextInputFormat切片机制
将大量的小文件合并成一个大的Map Task的过程
虚拟存储过程 切片过程
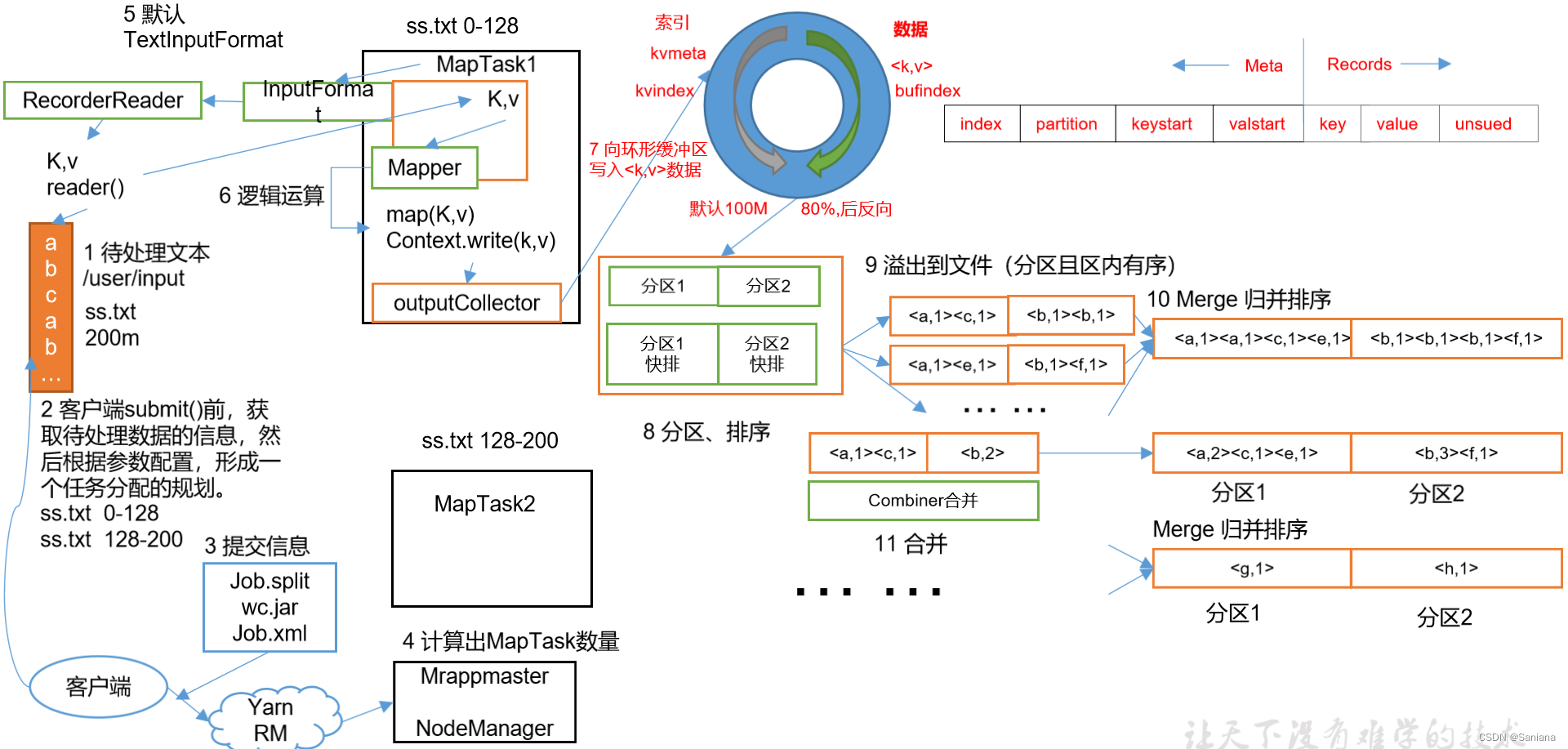
MapReduce工作流程
概念图
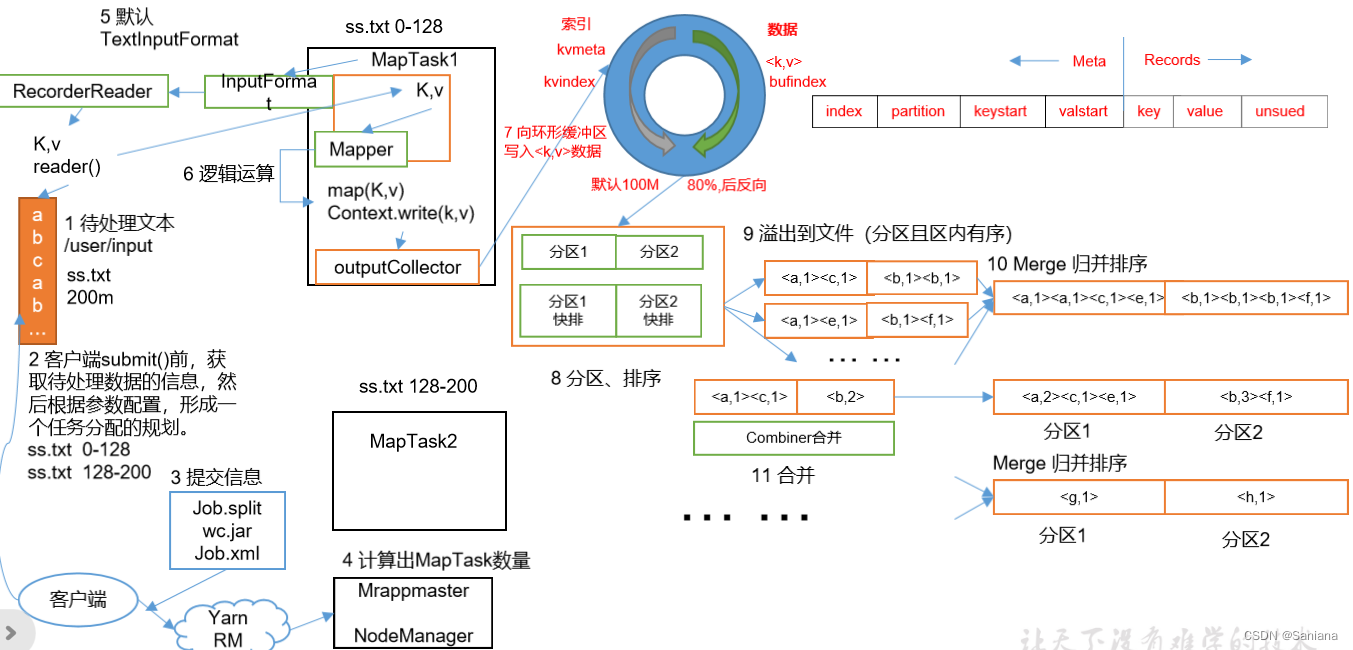
过程描述
- 准备待处理数据a.txt 200M 块大小是128M 切两片(若想改变切片大小就设置conf参数,具体修改见切片源码)
- InputFormat -> FileInputFormat -> TextInputFormat -> getSplit 对数据进行切片处理,上传jar包,提交job信息给YarnRunner 创建App Master
- App Master 申请资源,生成两个Map Task
- Map Task 用 InputFormat -> RecordReader -> LineRecondReader 读数据
- 然后使用Mapper的map方法进行数据处理
- 接下来就是shuffle过程,在下一章节详细讲解
shuffle机制
shuffle流程图解
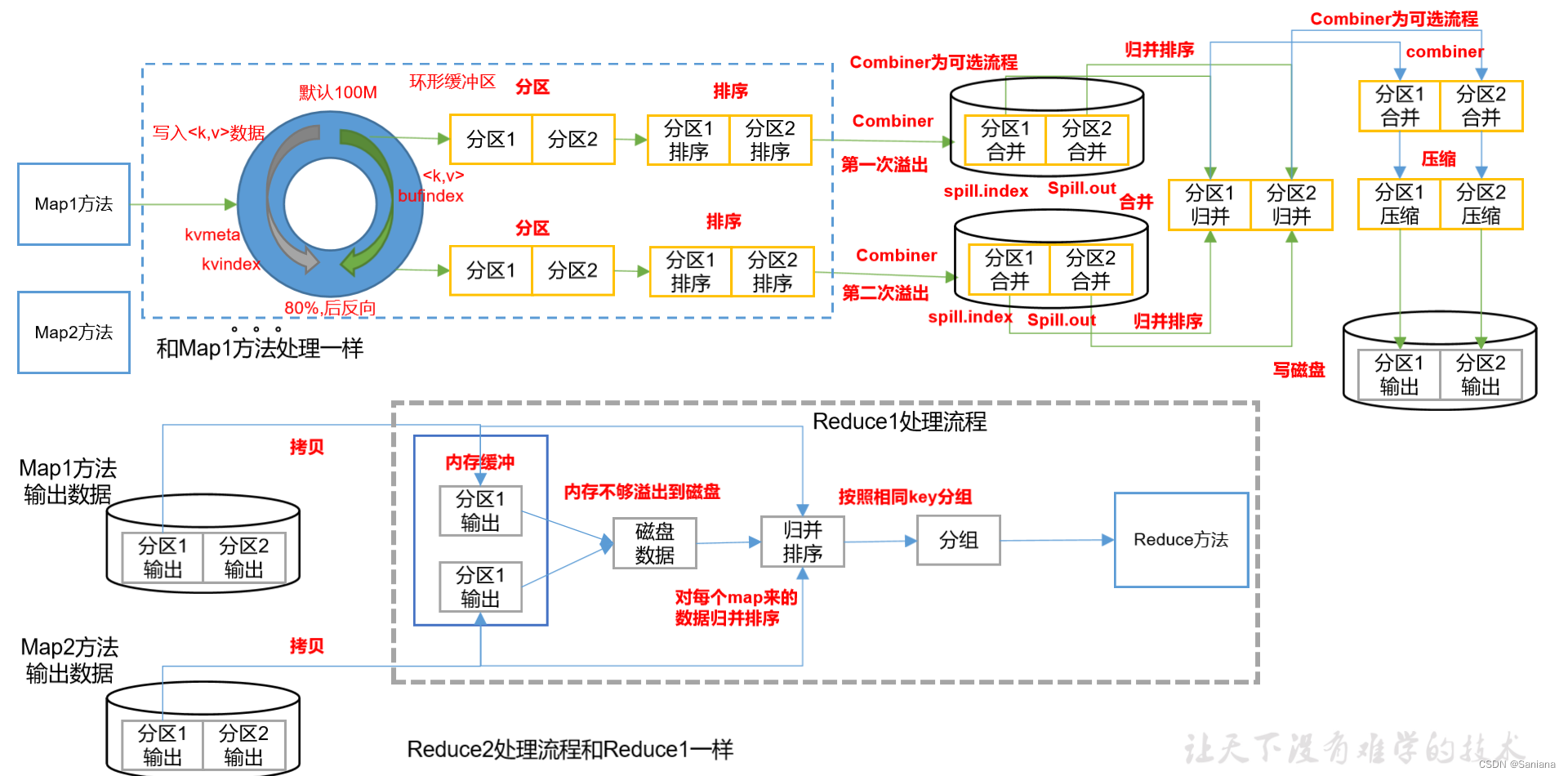
文字描述
- map方法写出的数据流向了缓冲区
- 该缓冲区在数据量达到80%时会进行排序,排序完成的数据会形成多个分区直接写入磁盘,每轮数据都会按该分区算法进行分区,方便下一步归并
- 所有数据都处理完成后就会进行归并排序,相同分区的数据进行归并
- 归并完成后按分区进行combiner合并压缩即:将1万条aaa 1 -> aaa 10000
- 将处理结果写入磁盘
- 进行过上述操作后将所有 Map Task 的相同分区放在一起进行的归并排序
- 最后数据进入 reduce 方法
Yarn工作机制
流程图
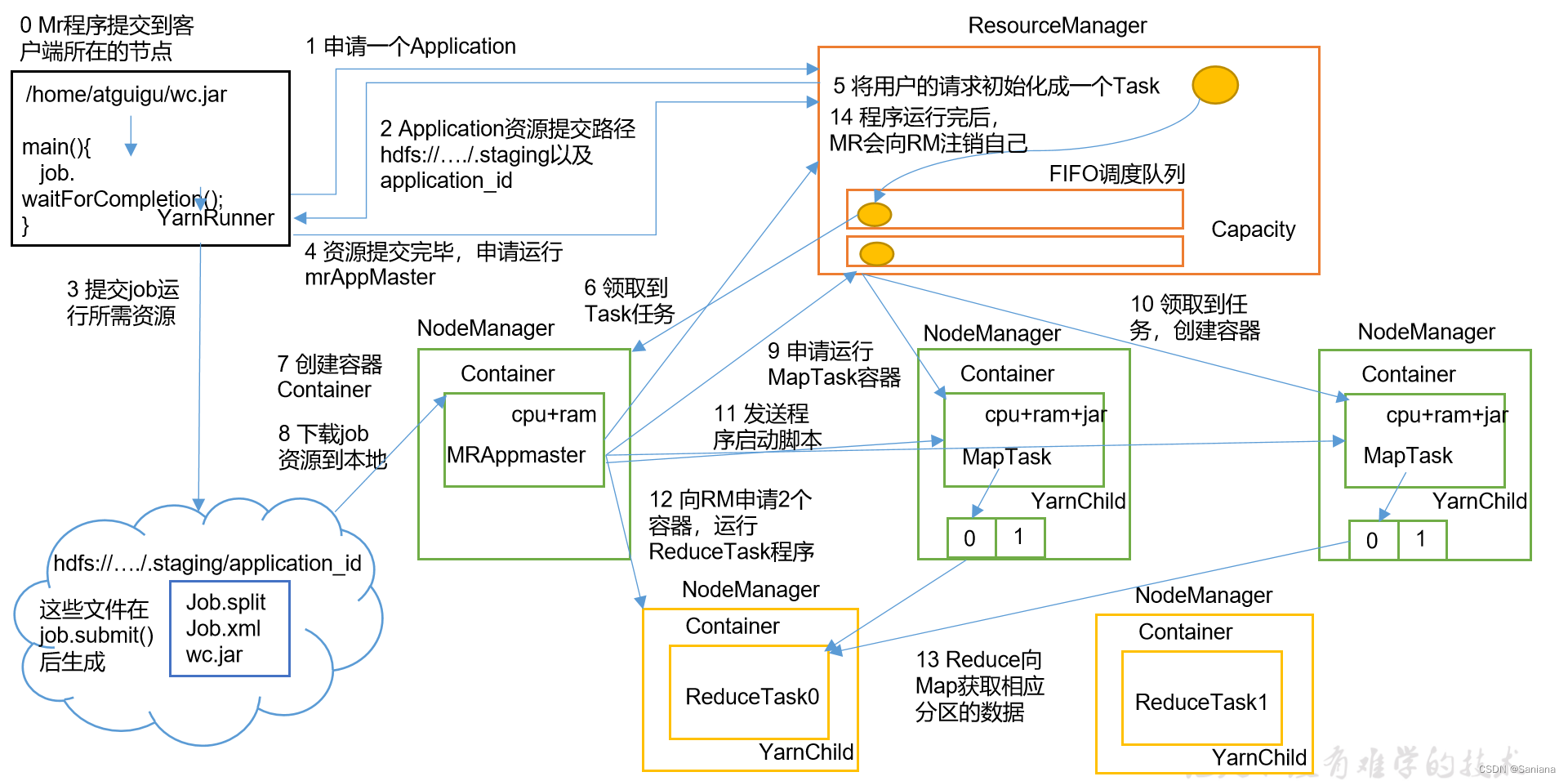
调度算法
先进先出调度器(FIFO)
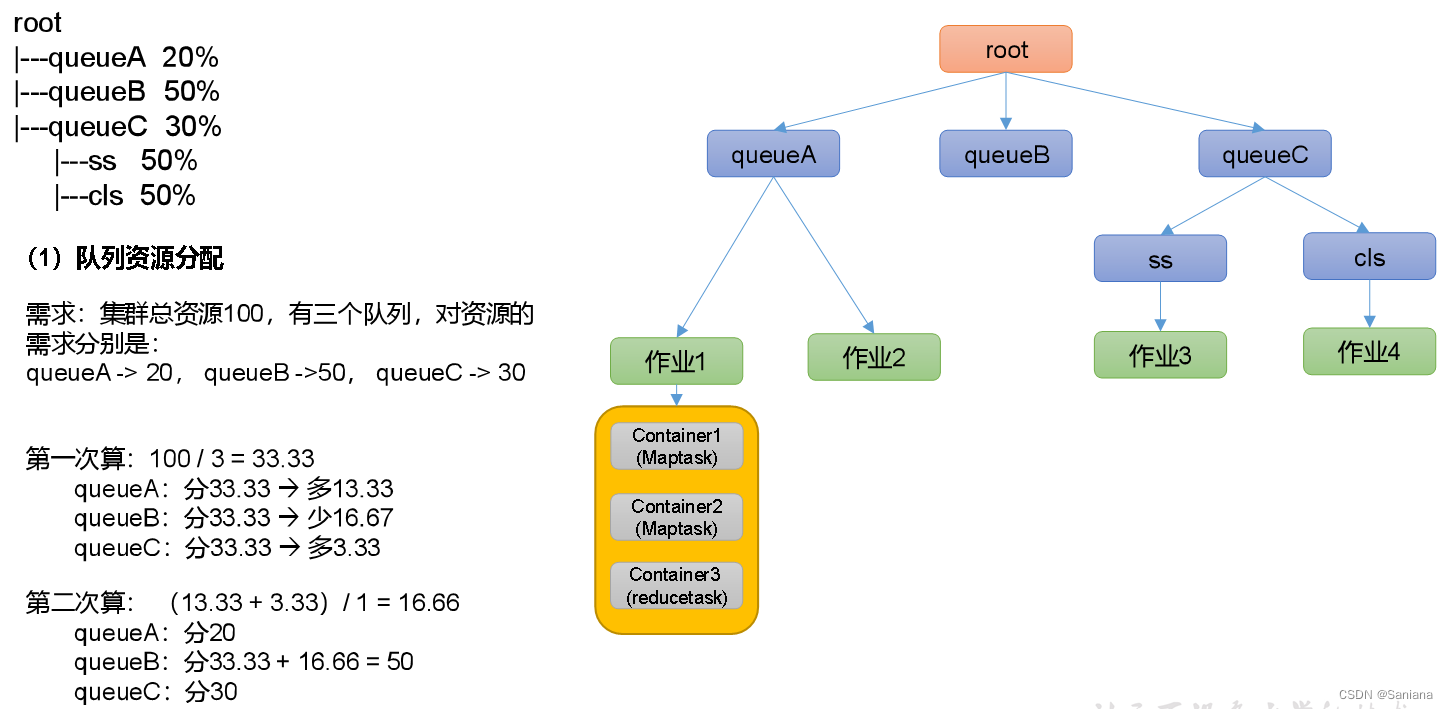
容量调度器(Capacity Scheduler)
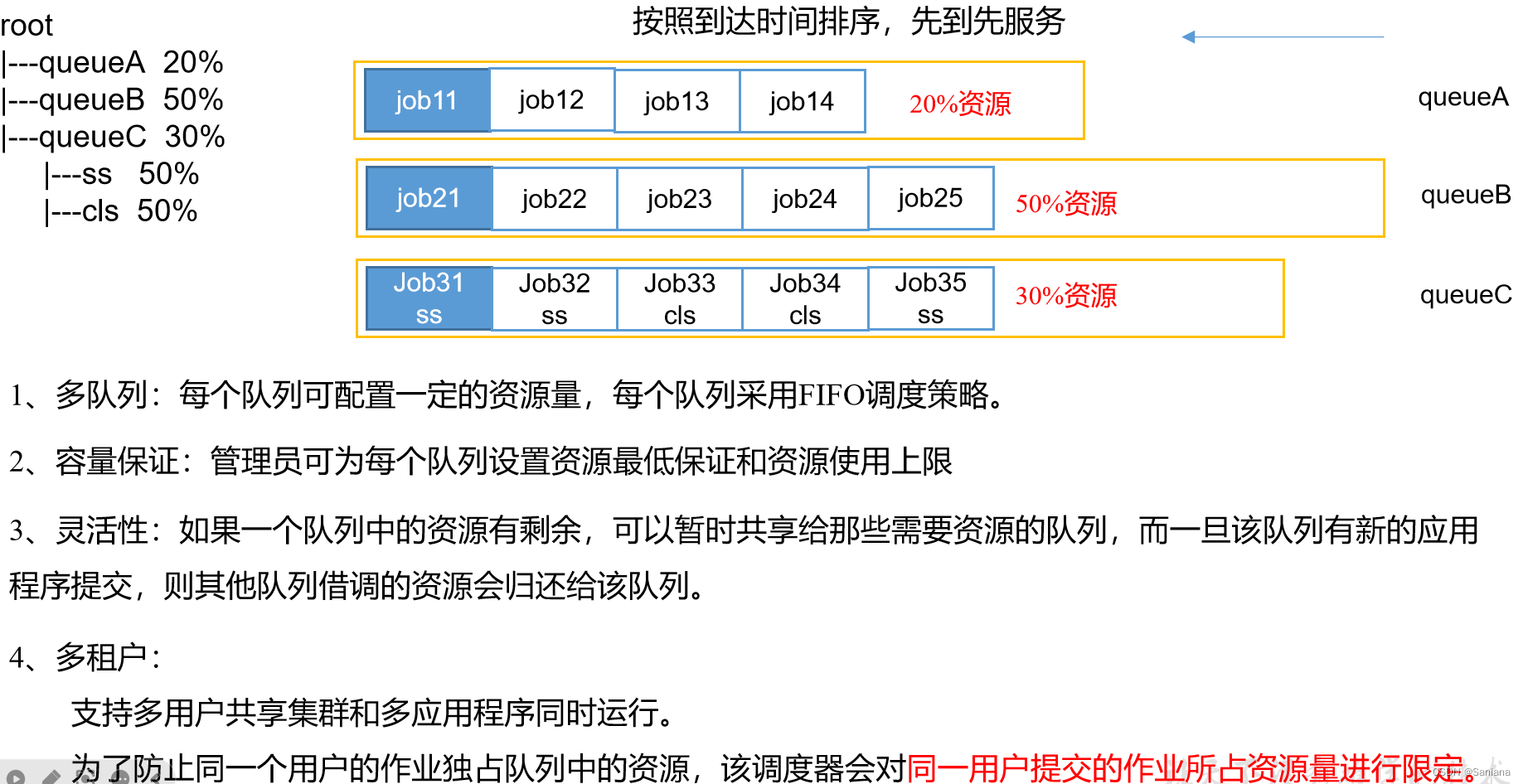
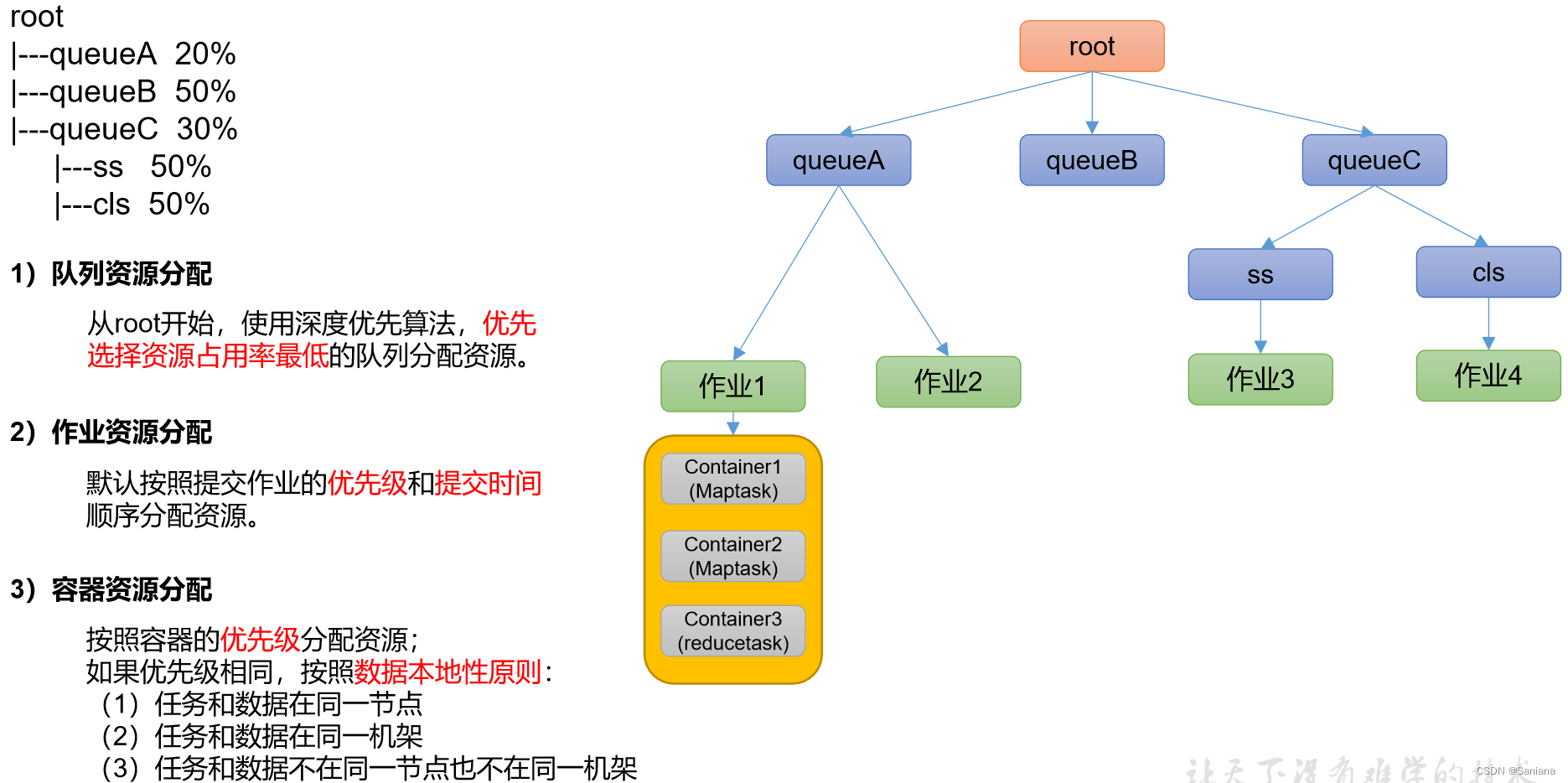
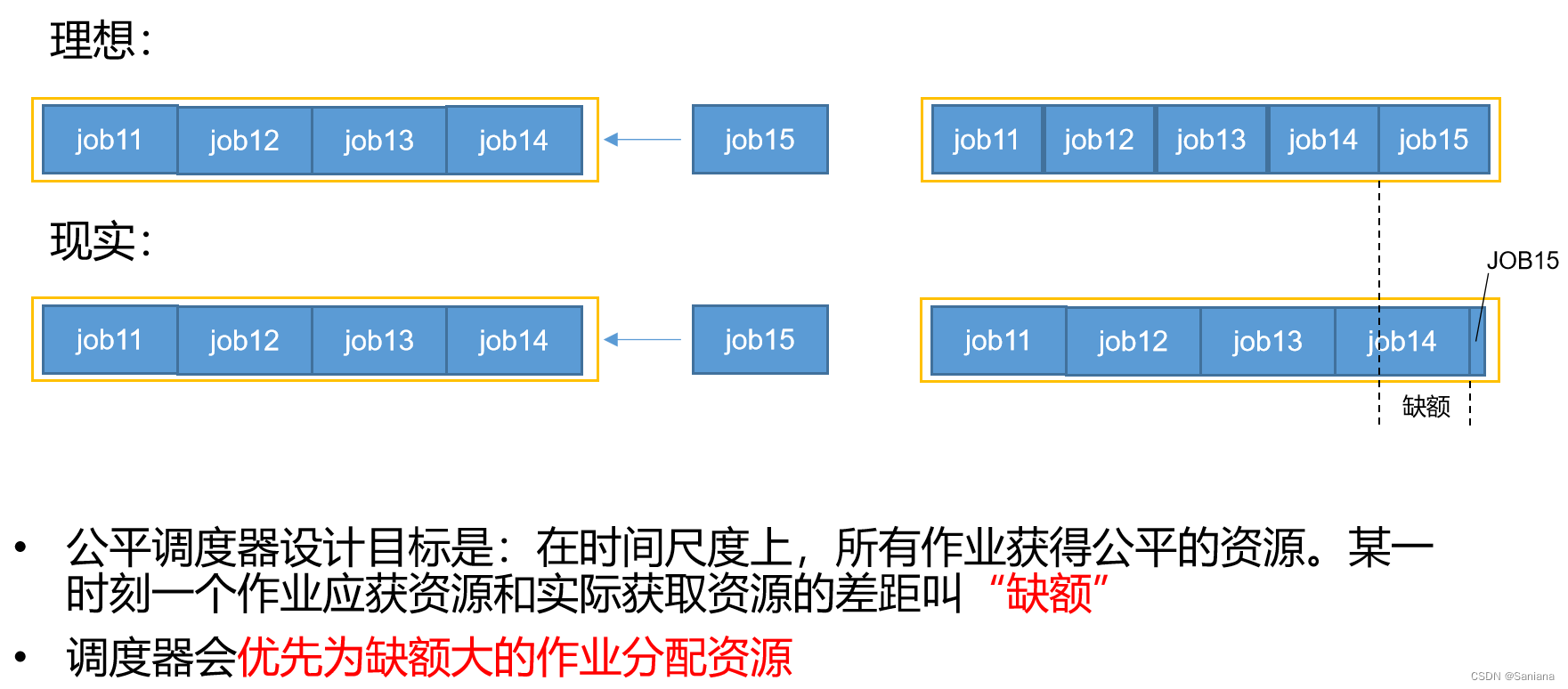
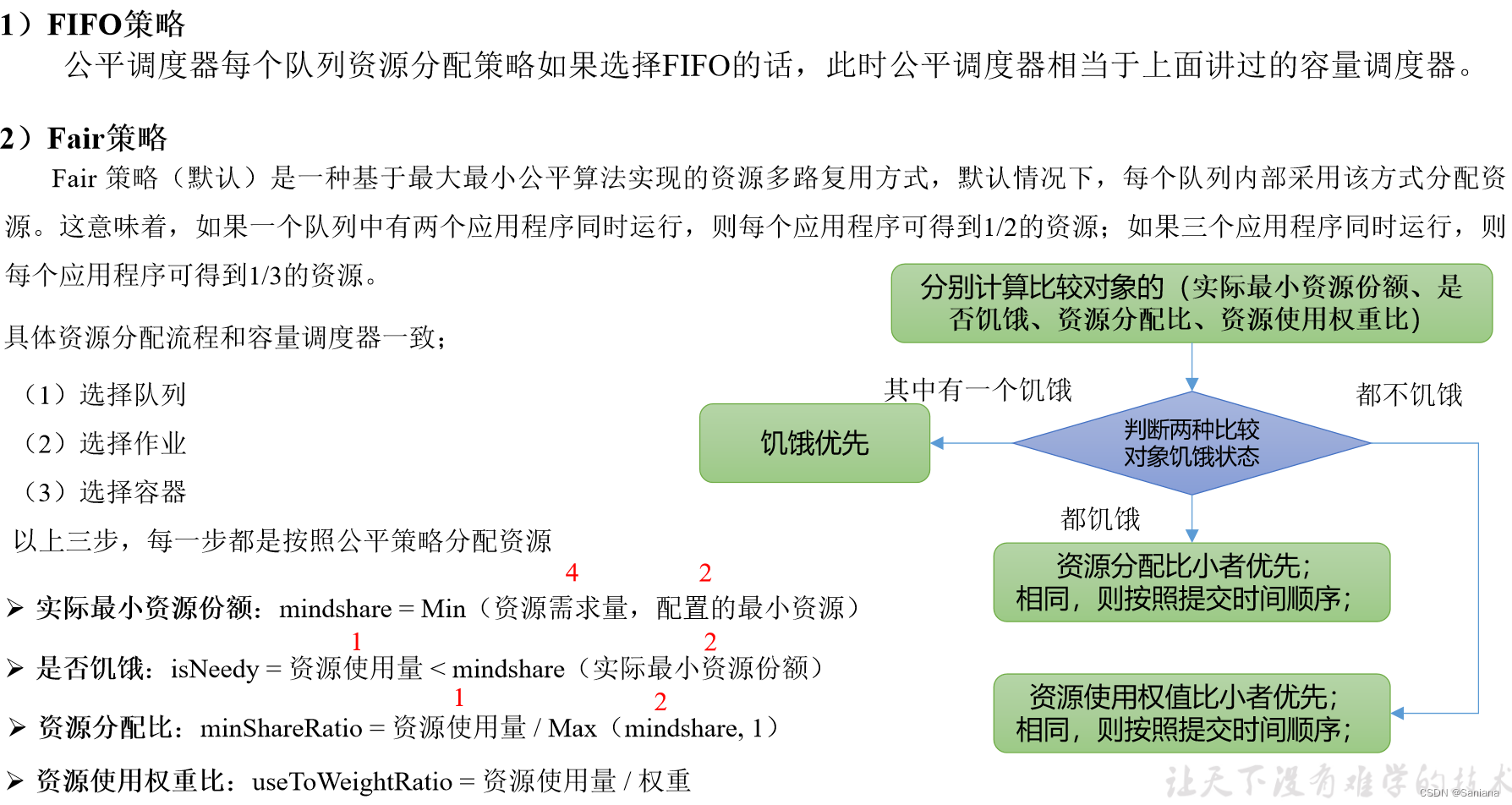
公平调度器(Fair Scheduler)



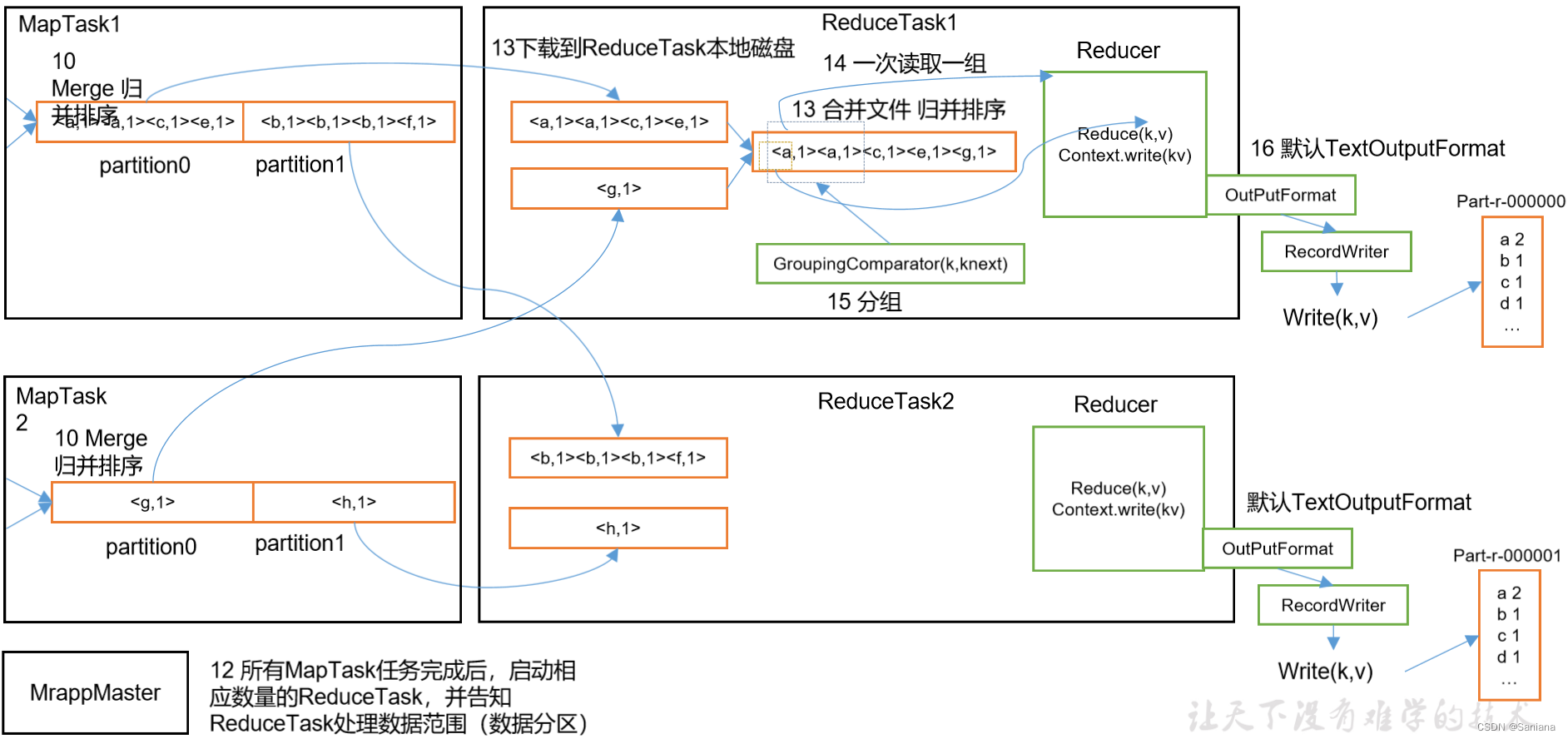
Map Task工作机制
流程图

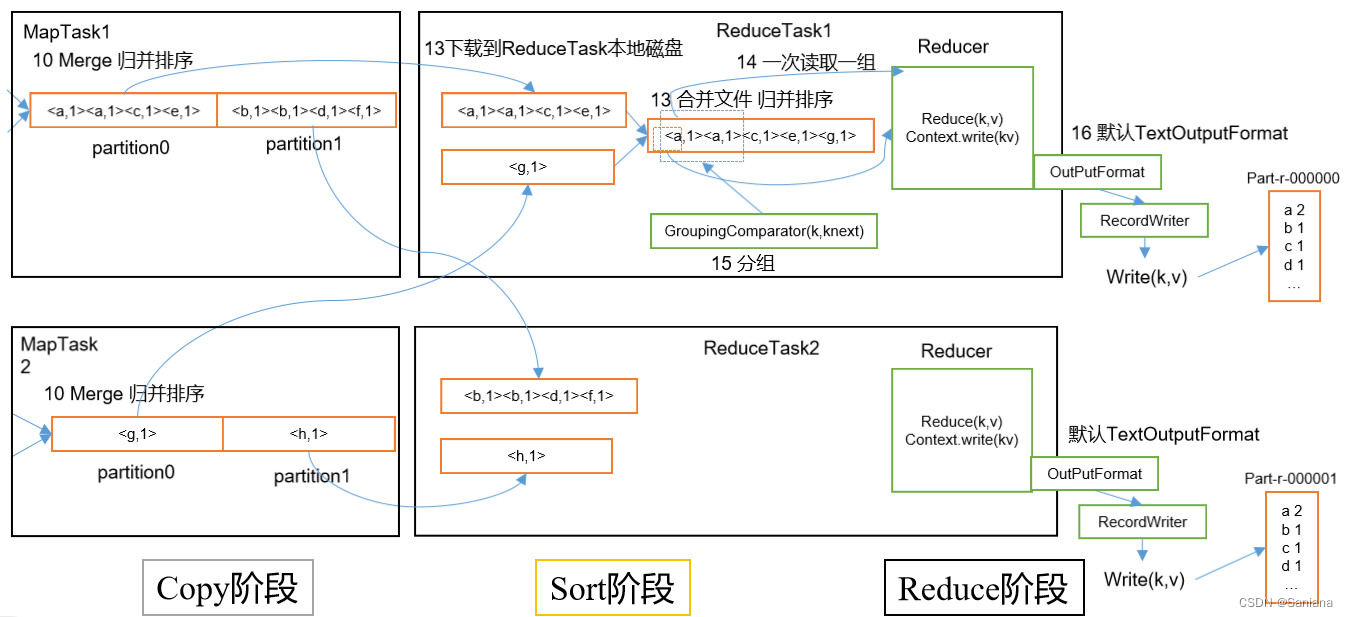
Reduce Task 工作机制
流程图
MapReduce工作机制
流程图